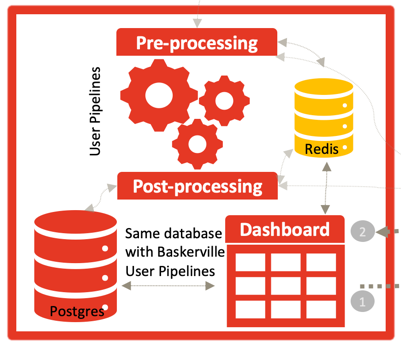
O desafio: Projetar e implementar um sistema para receber e processar feedback dos clientes, a fim de aprimorar e melhorar o modelo de aprendizado de máquina. Criar um modelo que tenha flexibilidade para se adaptar ao feedback dos clientes e às mudanças nos padrões das assinaturas das solicitações, permitindo, ao mesmo tempo, a implantação dinâmica do modelo, sem comprometer a integração existente.
Em outras palavras: criamos o sistema de mitigação de botnets Baskerville para podermos reagir a padrões de ataque novos e em constante mudança na rede Deflect. Ao treinar o sistema com base em ataques anteriores, chegamos a um ponto em que o Baskerville consegue identificar mais agentes maliciosos do que aqueles capturados por nossas regras estáticas. Agora, precisamos ampliar essa funcionalidade para aceitar feedback de nossos clientes sobre a precisão das previsões e para podermos implantar regularmente novos modelos sem qualquer interrupção no serviço.
Projeto do modelo
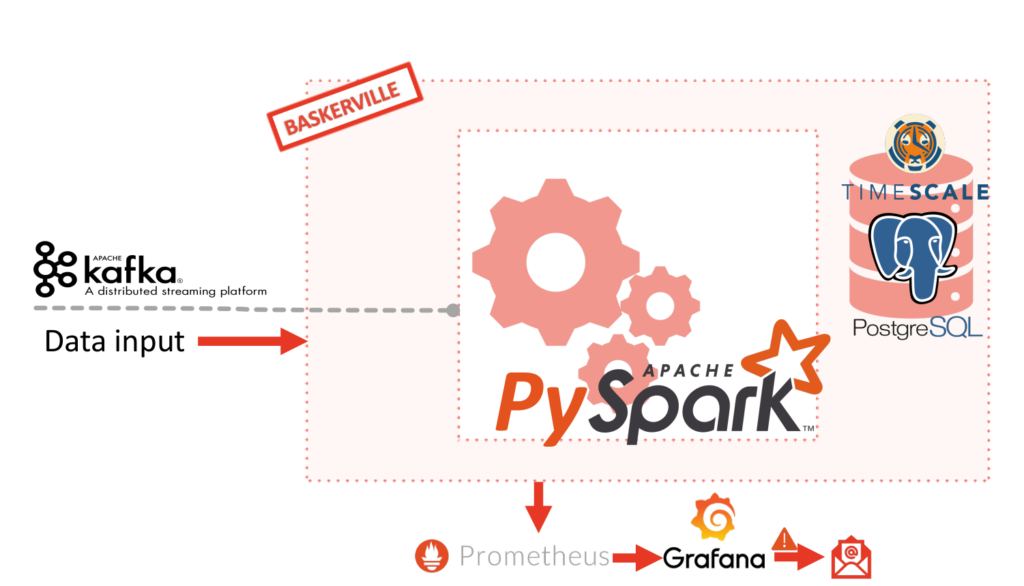
Existem várias abordagens para a atualização dinâmica de modelos. É possível usar arquivos simples, um cache e uma chamada à API REST, ou um mecanismo pub-sub; também é possível utilizar modelos serializados (pickled), modelos armazenados em um banco de dados e muitos outros mecanismos e formatos. Mas o conceito principal é o mesmo: verificar se há um novo modelo a cada X unidades de tempo ou ter um serviço em espera que seja notificado sempre que ocorrer uma alteração e se encarregue de recarregar o modelo — sob demanda. Estamos combinando essas abordagens para o nosso caso.
O modelo precisa ser retreinado regularmente para acompanhar os padrões de tráfego em constante mudança. A ideia geral do projeto é separar o fluxo de geração de características do fluxo de previsão. Como resultado, o fluxo de geração de características calcula um superconjunto de características, e o fluxo de previsão permite que diferentes versões do modelo utilizem qualquer subconjunto dessas características. Além disso, o modelo oferece compatibilidade com versões anteriores e utiliza os valores padrão caso o fluxo de geração de características esteja desatualizado.
Assim que um novo modelo estiver disponível, o pipeline de previsão detecta isso e começa a usar o novo modelo sem qualquer interrupção no serviço. Quando for necessário alterar as características, o modelo será implantado da mesma forma, mas o Módulo do Usuário também precisará ser atualizado e reimplantado. Os clientes atualizarão esse módulo a partir do nosso repositório Git. É muito importante mencionar que, durante o período necessário para a atualização do Módulo de Usuário, o novo modelo será capaz de se comunicar com o Módulo de Usuário desatualizado e fornecer as previsões da maneira habitual. A ausência de características novas ou modificadas na entrada do modelo não prejudicará a compatibilidade, uma vez que os valores padrão serão utilizados para os valores ausentes.
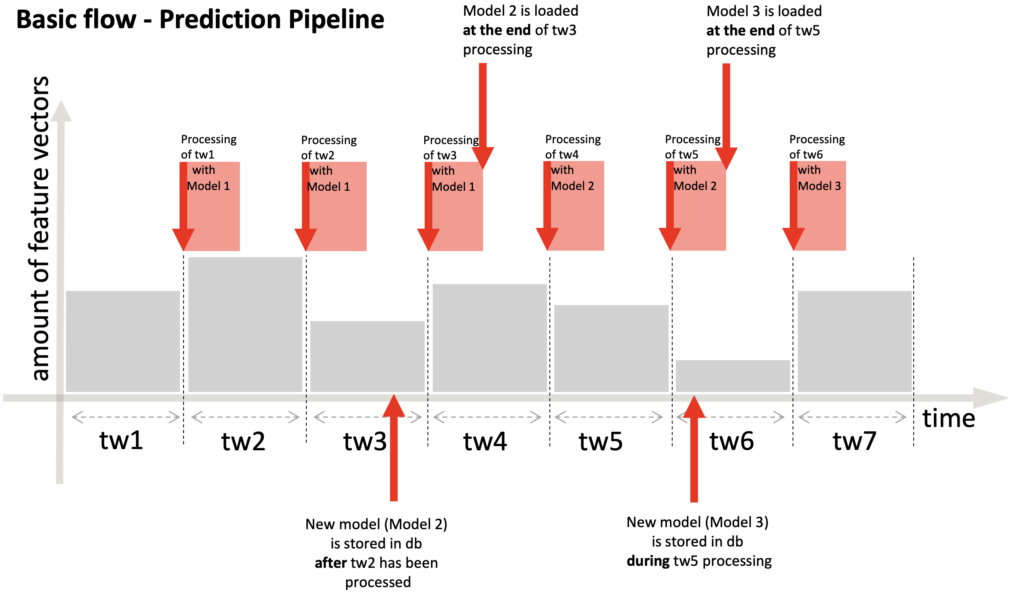
Partindo do pressuposto de que faz sentido que todas as solicitações dentro de uma janela de tempo sejam processadas pelo mesmo modelo, a mudança de modelo deve ocorrer no final ou no início do período de processamento. Por uma questão de desempenho, decidimos colocar o processo de atualização do modelo no final do PredictionPipeline, após as previsões terem sido enviadas ao cliente via Kafka, para que possamos aumentar o tempo que o cliente leva para receber as previsões. A figura a seguir explica o que acontece quando um novo modelo é armazenado no banco de dados após o processamento de uma janela de tempo (durante o tempo ocioso de espera por um novo lote) e durante o processamento de uma janela de tempo. No primeiro caso, a próxima janela de tempo será processada com o modelo antigo e, ao final, o novo será carregado. No segundo caso, como o processamento da janela de tempo atual ainda não foi concluído, carregaremos o novo modelo ao final dela e a próxima janela de tempo terá o modelo atualizado para trabalhar. A natureza assíncrona do treinamento e da previsão é a razão por trás do projeto do recarregamento. Realizamos vários testes para garantir que o recarregamento não afetasse o desempenho do pipeline.
Painel de feedback
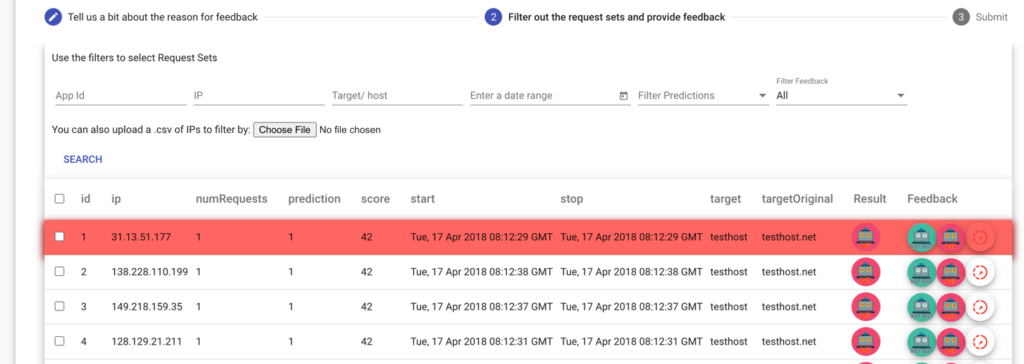
Para receber feedback específico dos clientes (por exemplo, “a previsão estava incorreta”), desenvolvemos e projetamos um painel gráfico composto por dois componentes principais: a API REST de back-end, criada com Python Flask e compatível com WebSocket por meio do Flask-SocketIO; e o projeto Angular de front-end, baseado em Node e npm. O processo de feedback consiste em três etapas:
- Contexto do feedback: forneça alguns detalhes sobre o feedback, como motivo, período e um campo opcional para observações. O motivo pode ser um dos seguintes: ataque, falso positivo, falso negativo, verdadeiro positivo, verdadeiro negativo ou outro. Oferecemos uma breve descrição para cada opção de motivo.
- Filtre os conjuntos de solicitações relevantes para o feedback usando os filtros de pesquisa. O usuário também pode fornecer arquivos CSV com endereços IP para usar como filtro.
- A última etapa consiste no usuário enviar os resultados do feedback para o Baskerville (Clearinghouse). Como a rotulagem e o envio de feedback são um processo meticuloso, projetamos o fluxo de trabalho de forma que o usuário possa pular a última etapa (envio) caso ainda não esteja pronto, podendo optar por enviá-la posteriormente. O Clearinghouse receberá o feedback em algum momento (janela de tempo configurável do pipeline de feedback) e, assim que o feedback for processado, o pipeline responderá ao tópico de resposta ao feedback do usuário – que, por convenção, é “{organization_uuid}.feedback”.
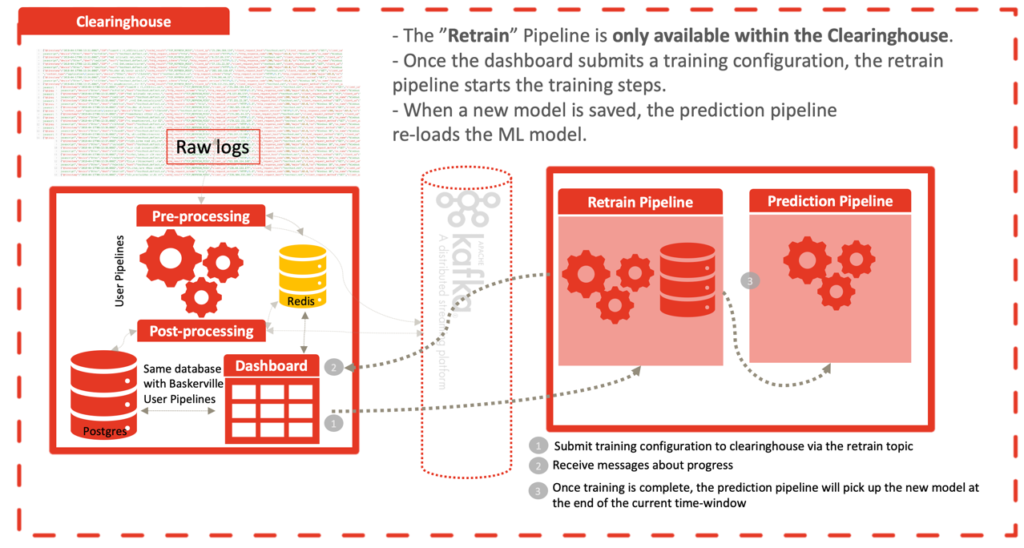
Também criamos um pipeline de retreinamento, bem como uma página de painel de controle e funcionalidades de retreinamento para facilitar a realização de atualizações periódicas do modelo. Essa funcionalidade está disponível apenas no Clearinghouse, onde o modelo está hospedado.
Este trabalho é resultado de meses de desenvolvimento, testes e iterações meticulosos. Se você tiver interesse em experimentar o Baskerville em suas próprias plataformas web, entre em contato conosco. Nosso trabalho está disponível sob uma licença de código aberto e foi desenvolvido com base nos princípios de privacidade desde a concepção. Incentivamos a adoção de nossas ferramentas por terceiros, fora do ecossistema Deflect, e publicaremos em breve outra postagem no blog detalhando o lançamento do Deflect Labs Clearinghouse. Fique de olho aqui!
- Baskerville: https://github.com/equalitie/baskerville
- Cliente do Baskerville: https://github.com/equalitie/baskerville_client
- Painel do Baskerville: https://github.com/equalitie/baskerville_dashboard
- Componentes do Baskerville Docker: https://github.com/equalitie/deflect-analytics-ecosystem
- Fork do Pyspark IForest: https://github.com/equalitie/spark-iforest