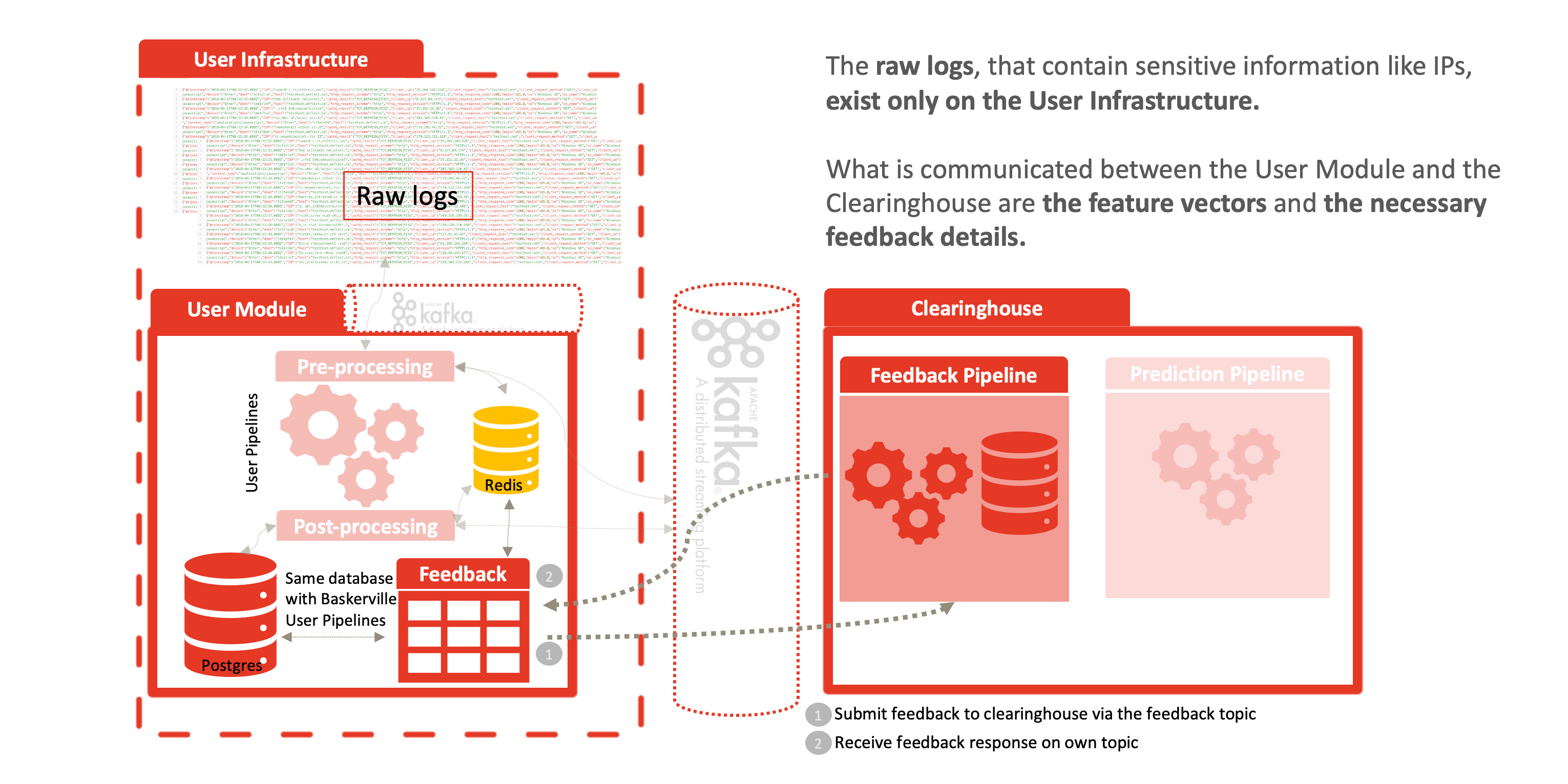
O futuro do Deflect Labs envolve a divisão do mecanismo Baskerville em componentes separados do User Module e da Clearinghouse. O User Module será executado pelos usuários para extrair vetores de recursos do comportamento de navegação de lotes de seus logs da Web recebidos. Esses vetores de recursos serão enviados para a Clearinghouse, onde serão processados e armazenados pelo mecanismo de previsão, e uma previsão (com um grau de certeza) será retornada. O usuário pode então tomar as medidas de mitigação necessárias (por exemplo, banir, restringir o acesso, impor um desafio de captcha…) com base na previsão. Além disso, a Câmara de Compensação conterá um Centro de Análise, onde os cientistas e técnicos de dados do Deflect trabalharão para aprimorar o classificador treinado usado no Mecanismo de Previsão. Desenvolveremos uma estrutura para fornecer feedback para aprimorar e avaliar iterativamente esse modelo. Haverá uma interface da Web (painel de controle) por meio da qual os usuários poderão registrar facilmente os ataques que viram.
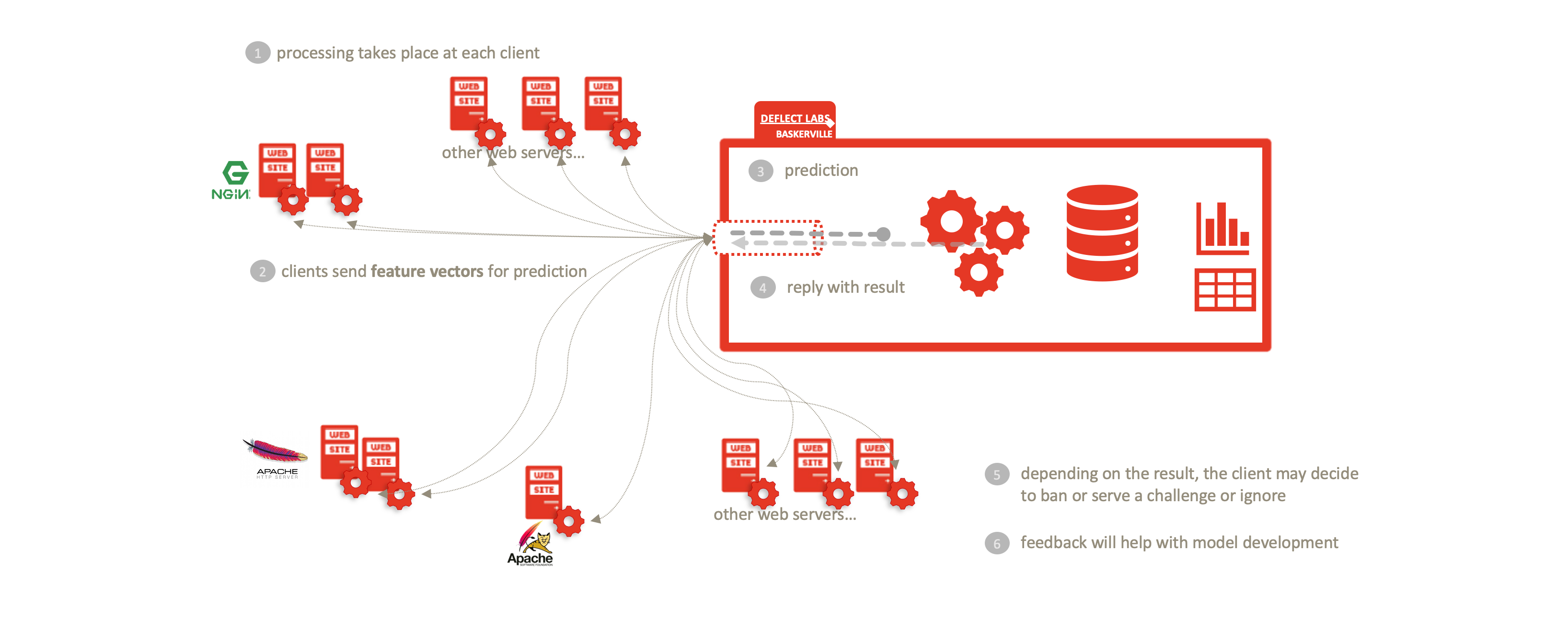
Ao dividir o Baskerville no módulo do usuário de processamento de logs e no mecanismo de previsão descrito acima, possibilitamos uma separação completa dos dados pessoais (logs brutos) da câmara de compensação centralizada. Os usuários processam seus próprios logs da Web localmente e enviam vetores de recursos (sem o IP/site do host) para receber uma previsão. Isso permite o compartilhamento de ameaças sem comprometer a privacidade dos dados pessoais inerentes aos registros brutos da Web. Essa separação permite a adoção do Deflect ISAC por qualquer parte interessada, fora da infraestrutura de atenuação do Deflect. O aumento da base de usuários desse componente também aumentará o volume de dados de navegação comportamental que podemos coletar e, portanto, a força dos modelos que podemos treinar.
O componente Analysis Center da Clearinghouse é uma extensão do que é atualmente o kit de ferramentas de análise off-line da Baskerville. Como não há dados confidenciais de IP do usuário contidos nos vetores de recursos usados pelo Analysis Center, ele pode ser aberto a parceiros externos interessados em colaborar no desenvolvimento de modelos. Da mesma forma, todos os resultados da análise podem ser mantidos em código aberto.
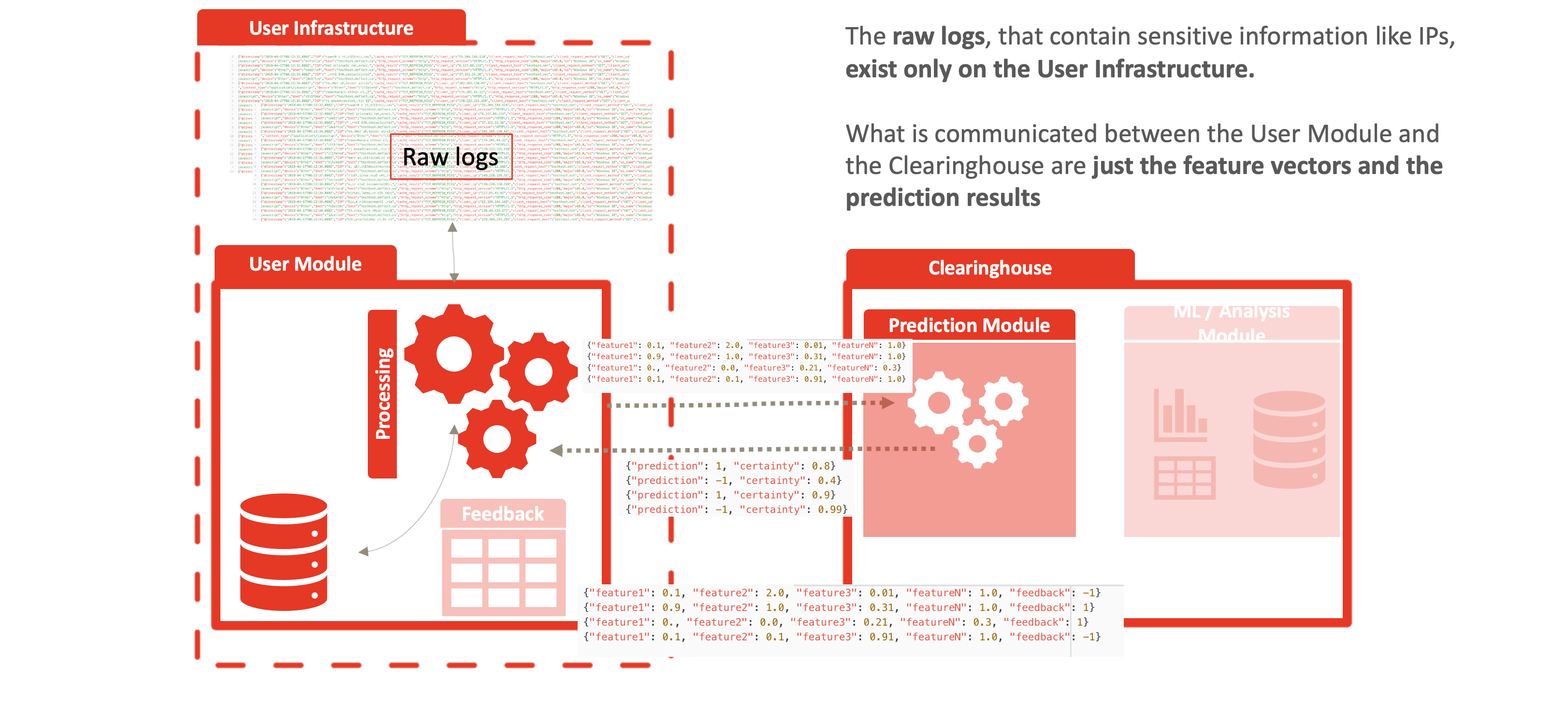
O Deflect ISAC não usa, não confia nem troca nenhum dado de registro, incluindo endereços IP (que, quando combinados com outras métricas, são informações de identificação pessoal) entre a borda da rede e a infraestrutura da câmara de compensação. Isso reduz o ônus de garantir a privacidade e a integridade dos dados na infraestrutura do serviço e oferece proteção contra ataques man-in-the-middle e vigilância da rede. É importante ressaltar que o serviço está em conformidade com todas as normas modernas de privacidade de dados e não exige confiança entre os clientes que utilizam o serviço ou entre os provedores de serviços que compartilham a mesma infraestrutura de câmara de compensação.
A anonimização vem do fato de que os logs brutos nunca saem da borda da rede, conforme mostrado nas figuras a seguir. Os vetores de recursos são gerados na borda e comunicados da seguinte maneira à câmara de compensação:
- os vetores de recursos, por exemplo: {“feature1”: 0,1, “feature2”: 2.0, “feature3”: 0,01, “featureN”: 1.0, “identifier”: “identificador aleatório para o usuário correlacionar os resultados”},
- o resultado da previsão: {“prediction”: 1, “certainty” (certeza): 0.8, “identifier”: “identificador aleatório para o usuário correlacionar os resultados”} e
- o feedback do usuário: {“feature1”: 0.1, “feature2”: 2.0, “feature3”: 0,01, “featureN”: 1.0, “prediction” (previsão): 1, “certainty” (certeza): 0,8, “feedback”: -1}.
Depois que uma previsão é calculada e enviada de volta ao módulo do usuário, um mecanismo de feedback permite que os operadores do sistema classifiquem essa resposta como positiva, falso-positiva etc. Essa resposta é compartilhada novamente com a câmara de compensação, o que nos permite determinar a precisão do modelo e decidir quando e como fazer o ajuste fino. Por exemplo, se o modelo previu algo como mal-intencionado e o usuário acabou banindo corretamente esse comportamento, então, com o feedback positivo, expandimos o conjunto de treinamento atual e fornecemos ao modelo mais dados para aprender. O mesmo vale para o feedback negativo, em que o usuário acabou não usando a previsão ou ela foi considerada um falso positivo/negativo. O aprendizado orientado permite que nosso modelo dê saltos gigantescos no aprimoramento de sua precisão.