

Quanto mais bizarro e grotesco for um incidente, mais cuidadosamente ele merece ser analisado.
― Arthur Conan Doyle, O Cão dos Baskervilles
Capítulo 1 – Baskerville
O Baskerville é uma máquina que opera na rede Deflect e protege sites contra bots maliciosos e persistentes. É também um projeto de código aberto que, com o tempo, poderá reduzir comportamentos indesejáveis também em suas redes. O Baskerville responde ao tráfego da web, analisando as solicitações em tempo real e bloqueando aqueles que apresentam comportamento suspeito. Há alguns meses, o Baskerville atingiu um marco importante: tomar suas próprias decisões sobre o tráfego considerado anômalo. A qualidade dessas decisões (recall) é alta, e o Baskerville já mitigou com sucesso muitos ataques sofisticados na vida real.
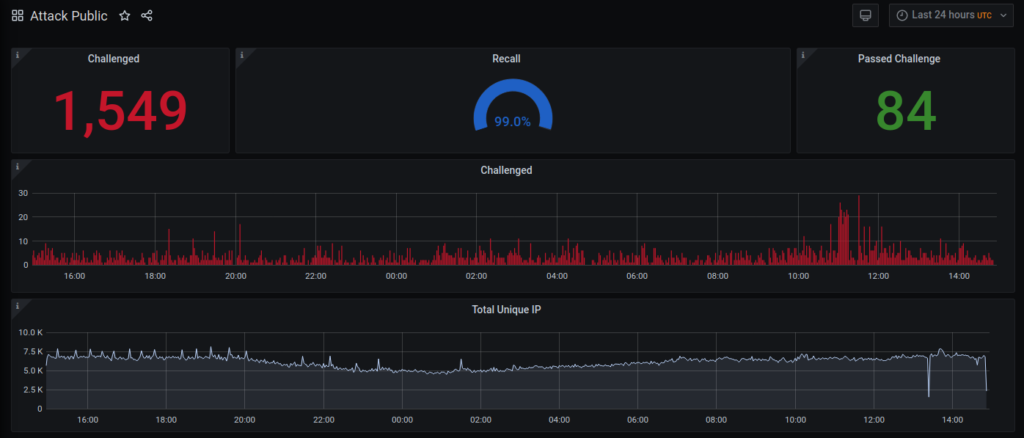
Treinamos o Baskerville para reconhecer como é o tráfego legítimo em nossa rede e como diferenciá-lo de solicitações maliciosas que tentam prejudicar os sites de nossos clientes. O Baskerville tem se mostrado muito útil para mitigar ataques DDoS e para classificar corretamente outros tipos de comportamentos maliciosos.
O Baskerville representa uma importante contribuição para o mundo da segurança online — onde defesas robustas na web costumam ser domínio exclusivo de empresas de software proprietário ou de complicados conjuntos de regras manuais. A natureza e os padrões em constante mudança dos ataques tornam sua mitigação um processo contínuo de adaptação. É por isso que treinamos uma máquina para reconhecer e responder ao tráfego anômalo. Nossos planos para o futuro do Baskerville permitirão a instalação do tipo “plug-and-play” na maioria dos ambientes web e a troca de dados de inteligência contra ameaças, respeitando a privacidade, entre o seu servidor e o centro de informações do Baskerville.
Capítulo 2 – Contexto
Os ataques à web representam uma ameaça às vozes democráticas na Internet. As botnets utilizam um arsenal de métodos, incluindo tentativas de login por força bruta, varredura de vulnerabilidades e ataques DDoS, para sobrecarregar os recursos de hospedagem e as defesas de uma plataforma, ou para causar prejuízos financeiros aos proprietários do site. Os ataques tornam-se uma forma de punição, intimidação e, acima de tudo, censura, seja por meio da negação direta de acesso a um recurso da Internet ou pela instigação do medo entre os editores. Grande parte do desenvolvimento até o momento na detecção de anomalias e na mitigação do tráfego de rede malicioso tem sido de código fechado e proprietário. Essas abordagens isoladas são limitantes ao lidar com variáveis em constante mudança. Elas também são bastante caras de se implementar, com os custos da empresa frequentemente compensados pela venda ou troca de inteligência de ameaças coletada na rede do cliente — algo que a Deflect não faz nem incentiva.
Desde 2010, o projeto Deflect protege centenas de sites da sociedade civil e da mídia independente contra ataques na web, processando mais de um bilhão de solicitações mensais a sites, provenientes tanto de pessoas quanto de bots. Agora, estamos disponibilizando ferramentas de mitigação desenvolvidas internamente para um público mais amplo, aprimorando as defesas de rede em prol da liberdade de expressão e de associação na internet.
O Baskerville foi desenvolvido ao longo de três anos pela equipe dedicada de especialistas em aprendizado de máquina da eQualitie. Vários desafios e metas foram apresentados à equipe. Para tornar essa solução eficaz diante da necessidade cada vez maior de que seres humanos realizem o monitoramento constante da rede e da necessidade incessante de criar regras para bloquear comportamentos maliciosos recém-descobertos na rede, o Baskerville precisava:
- Seja rápido o suficiente para que valha a pena
- Ser capaz de se adaptar às mudanças nos padrões de tráfego
- Fornecer informações úteis (uma previsão e uma pontuação para cada endereço IP)
- Fornecer previsões confiáveis (período de experiência e feedback)
O Baskerville funciona analisando o tráfego HTTP destinado ao seu site, monitorando a proporção entre tráfego legítimo e anômalo. Na rede Deflect, ele aciona um desafio de Turing para um endereço IP com comportamento suspeito, confirmando, em seguida, se é uma pessoa real ou um bot que está enviando solicitações para nós.
Capítulo 3 – Baskerville descobre
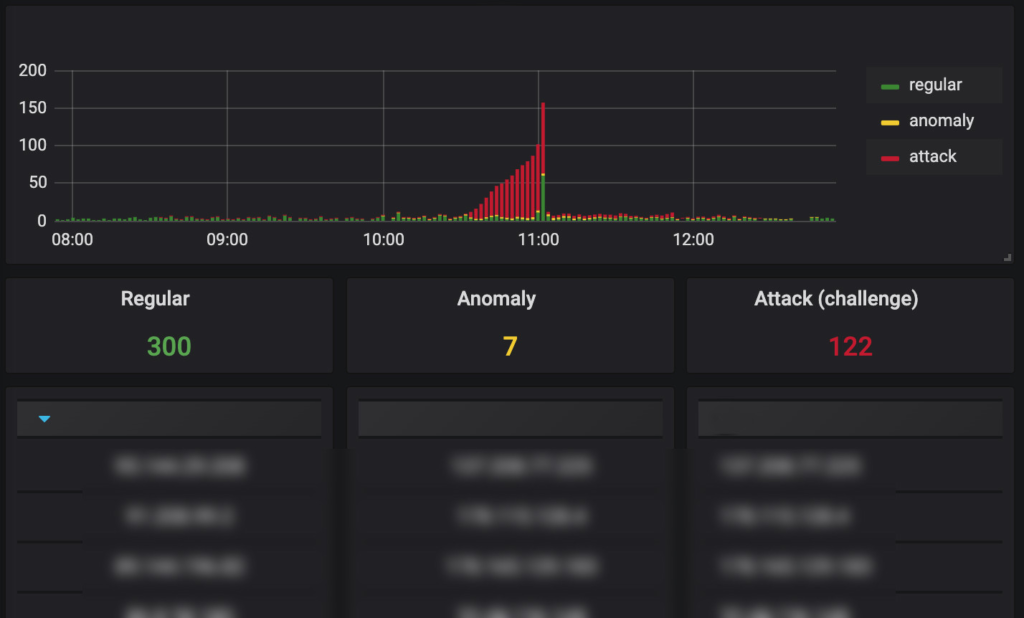
Para detectar novas ameaças em evolução, o Baskerville utiliza o algoritmo de detecção de anomalias não supervisionado Isolation Forest. A maioria dos algoritmos de detecção de anomalias constrói um perfil de instâncias normais e, em seguida, classifica as instâncias que não se enquadram nesse perfil como anomalias. O principal problema dessa abordagem é que o modelo é otimizado para detectar instâncias normais, mas não para detectar anomalias, o que resulta em um número excessivo de alarmes falsos ou na detecção insuficiente de anomalias. Em contrapartida, o Isolation Forest isola explicitamente as anomalias, em vez de traçar o perfil das instâncias normais. Esse método se baseia em uma suposição simples: “As anomalias são poucas e são diferentes”. Além disso, o algoritmo da Floresta de Isolamento não exige que o conjunto de treinamento contenha apenas instâncias normais. Mais ainda, o algoritmo apresenta um desempenho ainda melhor se o conjunto de treinamento contiver algumas anomalias — ou incidentes de ataque, no nosso caso. Isso nos permite retreinar o modelo regularmente com todo o tráfego recente, sem qualquer procedimento de rotulagem, a fim de nos adaptarmos aos padrões em constante mudança.
Rotulagem
Apesar de não precisarmos de rótulos para treinar um modelo, ainda precisamos de um conjunto de dados rotulado com ataques históricos para o ajuste dos parâmetros. Tradicionalmente, a rotulagem é um procedimento desafiador, pois exige muito trabalho manual. Cada novo ataque deve ser relatado e investigado, e cada endereço IP deve ser rotulado como malicioso ou benigno.
Nosso ambiente de produção registra vários incidentes por semana; por isso, criamos um procedimento automatizado de classificação utilizando um modelo de máquina treinado com as mesmas características que usamos para o modelo de detecção de anomalias Isolation Forest.
Concluímos que, se um incidente de ataque apresentar um pico de tráfego claramente visível, podemos supor que a grande maioria dos endereços IP durante esse período seja maliciosa e, assim, treinar um classificador como o Random Forest especificamente para esse incidente. A única informação fornecida pelo usuário seria o período exato desse incidente e o período de tráfego normal desse host. Esse classificador não seria perfeito, mas seria bom o suficiente para separar alguns endereços IP regulares da maioria dos endereços IP maliciosos durante o período do incidente. Além disso, partimos do princípio de que os IPs dos invasores provavelmente não estão ativos imediatamente antes do ataque e não classificamos um IP como malicioso se ele tiver sido detectado no período de tráfego normal.
Esse procedimento de classificação não é perfeito, mas nos permite classificar novos incidentes com muito pouco tempo e interação humana.

Métricas de desempenho
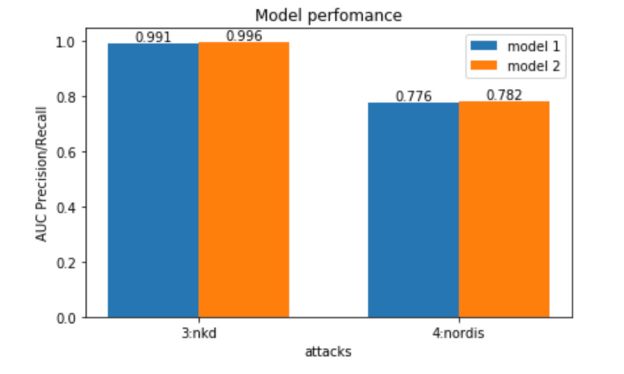
Utilizamos a métrica AUC de Precisão-Recall para avaliar o desempenho do modelo. A principal razão para usar a métrica de Precisão-Recall é que ela é mais sensível às melhorias na classe positiva do que a curva ROC (curva característica de operação do receptor). Estamos menos preocupados com a taxa de falsos positivos, pois, caso prevejamos erroneamente que um endereço IP está realizando alguma ação maliciosa, não o baniremos, mas apenas notificaremos o sistema de mitigação de ataques baseado em regras para que ele faça uma verificação desse endereço IP específico. O endereço IP só será banido se a verificação falhar.
Características categóricas
Após dois meses validando nossa abordagem no ambiente de produção, começamos a perceber que o modelo não era sofisticado o suficiente para distinguir anomalias específicas apenas de determinados clientes.
A principal razão para isso é que o algoritmo Isolation Forest publicado originalmente suporta apenas características numéricas e não conseguia funcionar com os chamados valores categóricos de string, como o nome do host. Primeiro, decidimos treinar um modelo separado para cada host-alvo e criar um conjunto de modelos para a previsão final. Essa abordagem complicou demais todo o processo e não se adaptou bem à escala. Além disso, tivemos que nos preocupar em ajustar os pesos no conjunto de modelos. Na verdade, comprometemos a ideia original de compartilhamento de conhecimento ao ter um único modelo para todos os clientes. Então, tentamos usar a maneira clássica de lidar com esse problema: a codificação one-hot. No entanto, a solução implantada não funcionou bem, pois o modelo ficou excessivamente ajustado à nova característica do nome do host, e o desempenho diminuiu.
Na iteração seguinte, descobrimos outra maneira de codificar características categóricas com base em um artigo revisado por pares publicado recentemente em 2018. A ideia principal era não usar a codificação one-hot, mas sim modificar o próprio algoritmo de construção de árvores. Não conseguimos encontrar a implementação dessa ideia e tivemos que modificar o código-fonte da biblioteca IForest em Scala. Introduzimos uma nova característica de string, “hostname”, e, dessa vez, o modelo apresentou uma melhoria notável de desempenho em produção. Além disso, nossa implementação final era genérica e nos permitiu fazer experimentos com outras características categóricas, como país, agente do usuário, sistema operacional etc.
Amostragem estratificada
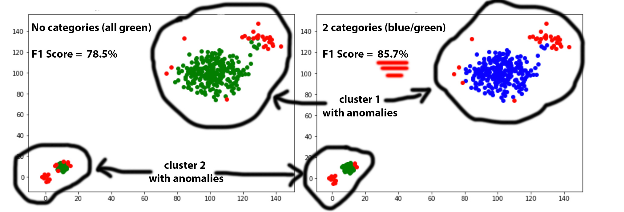
O Baskerville utiliza um único modelo de aprendizado de máquina treinado com os dados recebidos de centenas de clientes. Isso nos permite compartilhar o conhecimento e aproveitar os benefícios de um modelo treinado com um conjunto de dados global de incidentes registrados. No entanto, quando implantamos o Baskerville pela primeira vez, percebemos que o modelo apresenta um viés em favor de clientes com alto tráfego.
Tivemos que encontrar um equilíbrio na quantidade de dados que alimentamos no pipeline de treinamento a partir de cada cliente. Por um lado, queríamos equalizar o número de registros de cada cliente, mas, por outro lado, os clientes com alto tráfego forneciam informações sobre incidentes muito mais valiosas. Decidimos usar amostragem estratificada dos conjuntos de dados de treinamento com um único parâmetro: o número máximo de amostras por host.
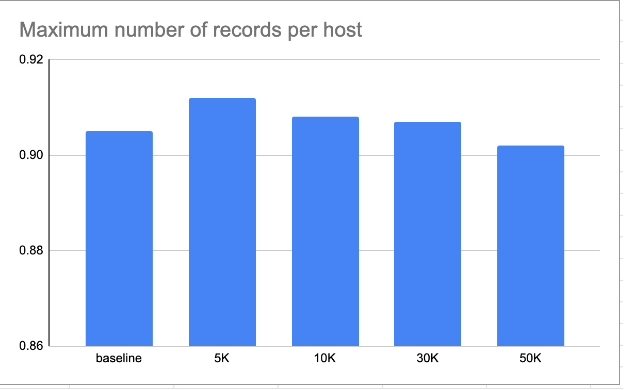
Armazenamento
A Baskerville usa o Postgres para armazenar os resultados processados. A tabela `request-sets` contém os resultados dos weblogs em tempo real pré-processados pelo nosso mecanismo de análise, que tem um volume estimado de entrada de ~30 GB por semana. Assim, em um ano, teríamos uma tabela de ~1,5 TB. Embora isso esteja dentro dos limites do Postgres, executar consultas nessa tabela não seria muito eficiente. Foi aí que o recurso de particionamento de dados do Postgres entrou em cena. Usamos esse recurso para dividir a tabela “request-sets” em tabelas menores, cada uma contendo os dados de uma semana. Isso permitiu um melhor gerenciamento de dados e uma execução mais rápida das consultas.
No entanto, mesmo com o uso do particionamento de dados, precisávamos ser capazes de escalar horizontalmente o banco de dados. Como já contávamos com a extensão Timescale para o banco de dados Prometheus, decidimos usá-la também para o Baskerville. Seguimos o tutorial do Timescale para migração de dados no mesmo banco de dados, o que significa que criamos uma tabela temporária, transferimos os dados de cada uma das partições para a tabela temporária, executamos o comando para criar uma hypertable na tabela temporária, excluímos a tabela inicial de conjuntos de solicitações e suas partições e, por fim, renomeamos a tabela temporária como “conjuntos de solicitações”. Infelizmente, o processo não foi muito simples e enfrentamos alguns problemas. Mas, no final, conseguimos escalar o banco de dados e, atualmente, estamos operando com o Timescale em produção.
Também analisamos outras opções, como o TileDb, o Apache Hive e o Apache HBase, mas, por enquanto, o Timescale é suficiente para nossas necessidades. No entanto, com certeza voltaremos a analisar essa questão no futuro.
Arquitetura
O projeto inicial do Baskerville foi elaborado partindo do pressuposto de que ele funcionaria no âmbito do Deflect como um mecanismo de análise, para auxiliar o mecanismo de detecção e mitigação de ataques baseado em regras já em vigor. No entanto, as necessidades mudaram, pois tornou-se necessário disponibilizar as previsões do Baskerville a outros usuários e colocar nossas análises à disposição deles.
Para permitir que outros usuários pudessem aproveitar nosso modelo, tivemos que reprojetar os pipelines para torná-los mais modulares. Também precisávamos levar em conta o tipo de dados a ser trocado; mais especificamente, queríamos evitar qualquer troca que envolvesse dados confidenciais, como endereços IP, por exemplo. A ideia era que o pré-processamento ocorresse no lado do cliente, e apenas os vetores de características resultantes fossem enviados, via Kafka, para o Centro de Predição. O Centro de Previsão monitora continuamente a chegada de vetores de características e, assim que uma solicitação chega, utiliza o modelo pré-treinado para fazer a previsão e enviar os resultados de volta ao usuário. Todo esse processo ocorre sem a troca de qualquer tipo de informação confidencial, já que apenas os vetores de características são transmitidos de um lado para o outro.
No lado do cliente, tivemos que implementar um mecanismo de cache com TTL, para que os conjuntos de solicitações aguardem suas previsões correspondentes. Se o centro de previsão demorar mais de 10 minutos, os conjuntos de solicitações expiram. 10 minutos, é claro, não é um tempo aceitável, mas apenas uma medida de segurança para que não mantenhamos conjuntos de solicitações indefinidamente, o que pode resultar em OOM. O TTL é configurável. Utilizamos o Redis para esse mecanismo, pois ele possui o recurso de TTL integrado e existe um conector Spark-Redis que pudemos usar facilmente, mas ainda estamos ajustando o desempenho e considerando alternativas. Também precisávamos de um aplicativo Spark separado para lidar com a correspondência entre a previsão e o conjunto de solicitações assim que a resposta do Centro de Previsão fosse recebida. Esse aplicativo monitora o tópico do Kafka específico do cliente e, assim que uma previsão chega, ele consulta o Redis, busca o conjunto de solicitações correspondente e salva tudo no banco de dados.
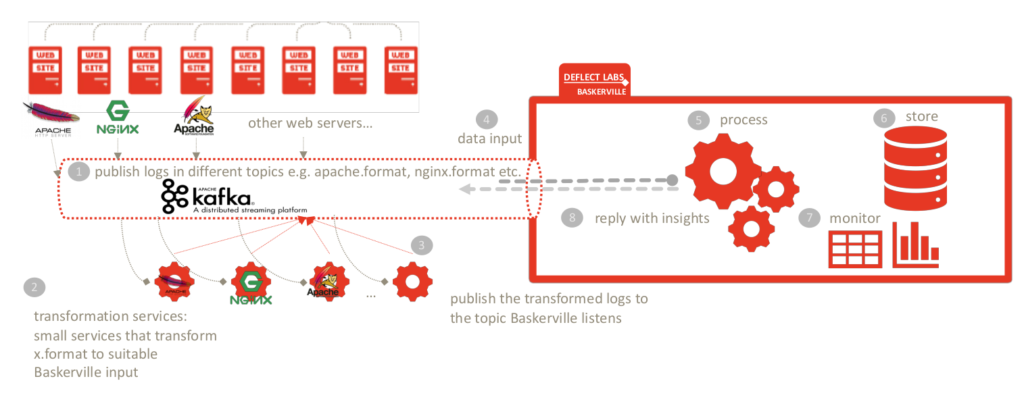
Resumindo, na nova arquitetura, o pré-processamento ocorre no lado do cliente; os vetores de características são enviados via Kafka para o centro de previsão (sem troca de dados confidenciais); uma previsão e uma pontuação para cada conjunto de solicitações são enviadas como resposta a cada vetor de características (via Kafka), e, no lado do cliente, outro trabalho do Spark está aguardando para consumir a mensagem de previsão, associá-la ao respectivo conjunto de solicitações e salvá-la no banco de dados.
Leia mais sobre o projeto e baixe o código-fonte para experimentar por conta própria. Entre em contato conosco para obter mais informações ou para receber ajuda na configuração do Baskerville em seu ambiente web.
