

The more outré and grotesque an incident is the more carefully it deserves to be examined.
― Arthur Conan Doyle, The Hound of the Baskervilles
Chapter 1 – Baskerville
Baskerville is a machine operating on the Deflect network that protects sites from hounding, malicious bots. It’s also an open source project that, in time, will be able to reduce bad behaviour on your networks too. Baskerville responds to web traffic, analyzing requests in real-time, and challenging those acting suspiciously. A few months ago, Baskerville passed an important milestone – making its own decisions on traffic deemed anomalous. The quality of these decisions (recall) is high and Baskerville has already successfully mitigated many sophisticated real-life attacks.
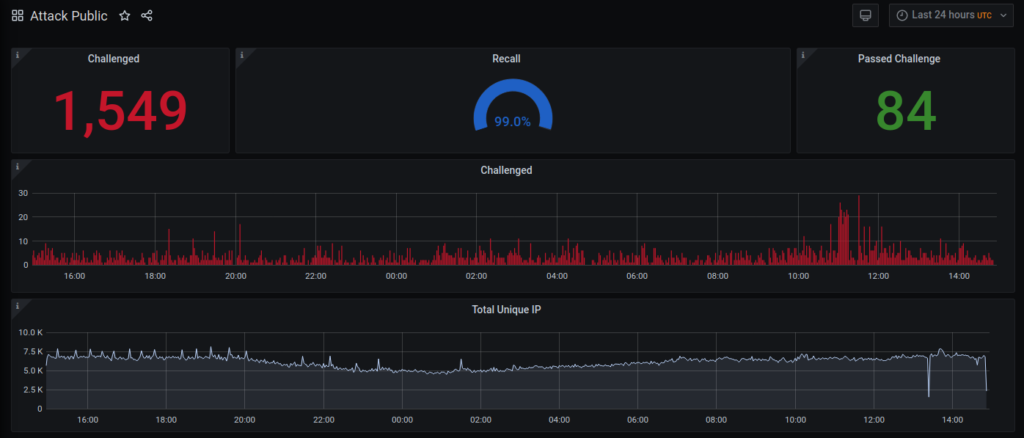
We’ve trained Baskerville to recognize what legitimate traffic on our network looks like, and how to distinguish it from malicious requests attempting to disrupt our clients’ websites. Baskerville has turned out to be very handy for mitigating DDoS attacks, and for correctly classifying other types of malicious behaviour.
Baskerville is an important contribution to the world of online security – where solid web defences are usually the domain of proprietary software companies or complicated manual rule-sets. The ever-changing nature and patterns of attacks makes their mitigation a continuous process of adaptation. This is why we’ve trained a machine how to recognize and respond to anomalous traffic. Our plans for Baskerville’s future will enable plug-and-play installation in most web environments and privacy-respecting exchange of threat intelligence data between your server and the Baskerville clearinghouse.
Chapter 2 – Background
Web attacks are a threat to democratic voices on the Internet. Botnets deploy an arsenal of methods, including brute force password login, vulnerability scanning, and DDoS attacks, to overwhelm a platform’s hosting resources and defences, or to wreak financial damage on the website’s owners. Attacks become a form of punishment, intimidation, and most importantly, censorship, whether through direct denial of access to an Internet resource or by instilling fear among the publishers. Much of the development to-date in anomaly detection and mitigation of malicious network traffic has been closed source and proprietary. These silo-ed approaches are limiting when dealing with constantly changing variables. They are also quite expensive to set-up, with a company’s costs often offset by the sale or trade of threat intelligence gathered on the client’s network, something Deflect does not do or encourage.
Since 2010, the Deflect project has protected hundreds of civil society and independent media websites from web attacks, processing over a billion monthly website requests from humans and bots. We are now bringing internally developed mitigation tooling to a wider audience, improving network defences for freedom of expression and association on the internet.
Baskerville was developed over three years by eQualitie’s dedicated team of machine learning experts. Several challenges or ambitions were presented to the team. To make this an effective solution to the ever-growing need for humans to perform constant network monitoring, and the never-ending need to create rules to ban newly discovered malicious network behaviour, Baskerville had to:
- Be fast enough to make it count
- Be able to adapt to changing traffic patterns
- Provide actionable intelligence (a prediction and a score for every IP)
- Provide reliable predictions (probation period & feedback)
Baskerville works by analyzing HTTP traffic bound for your website, monitoring the proportion of legitimate vs anomalous traffic. On the Deflect network, it will trigger a Turing challenge to an IP address behaving suspiciously, thereafter confirming whether a real person or a bot is sending us requests.
Chapter 3 – Baskerville Learns
To detect new evolving threats, Baskerville uses the unsupervised anomaly detection algorithm Isolation Forest. The majority of anomaly detection algorithms construct a profile of normal instances, then classify instances that do not conform to the normal profile as anomalies. The main problem with this approach is that the model is optimized to detect normal instances, but not optimized to detect anomalies causing either too many false alarms or too few anomalies. In contrast, Isolation Forest explicitly isolates anomalies rather than profiling normal instances. This method is based on a simple assumption: ‘Anomalies are few, and they are different’. In addition, the Isolation Forest algorithm does not require a training set to contain normal instances only. Moreover, the algorithm performs even better if the training set contains some anomalies, or attack incidents in our case. This enables us to re-train the model regularly on all the recent traffic without any labeling procedure in order to adapt to the changing patterns.
Labelling
Despite the fact that we don’t need labels to train a model, we still need a labelled dataset of historical attacks for parameter tuning. Traditionally, labelling is a challenging procedure since it requires a lot of manual work. Every new attack must be reported and investigated, and every IP should be labelled either malicious or benign.
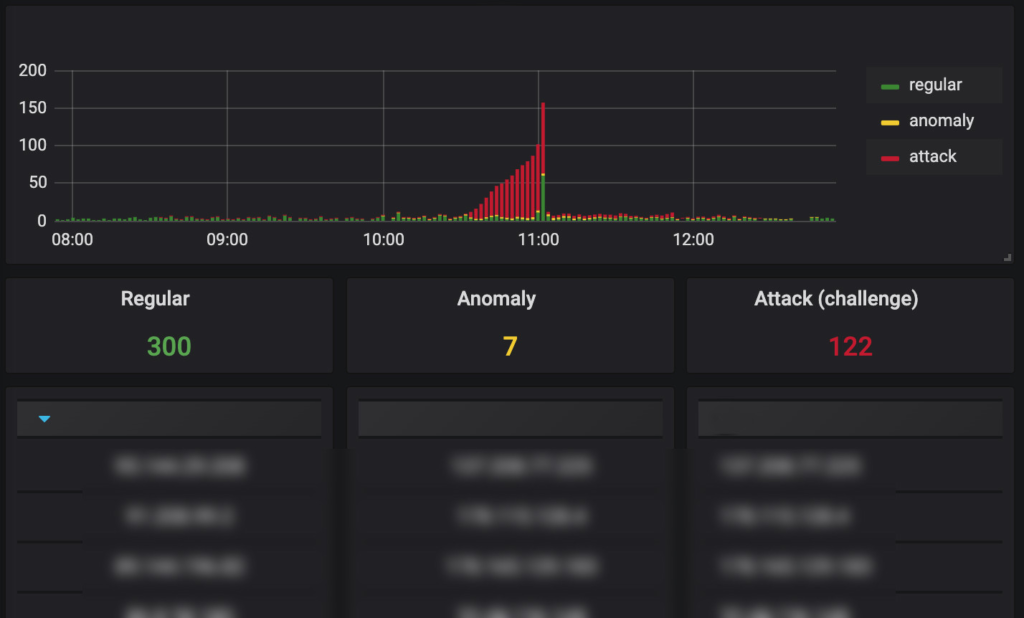
Our production environment reports several incidents a week, so we designed an automated procedure of labelling using a machine model trained on the same features we use for the Isolation Forest anomaly detection model.
We reasoned that if an attack incident has a clearly visible traffic spike, we can assume that the vast majority of the IPs during this period are malicious, and we can train a classifier like Random Forest particularly for this incident. The only user input would be the precise time period for that incident and for the time period for ordinal traffic for that host. Such a classifier would not be perfect, but it would be good enough to be able to separate some regular IPs from the majority of malicious IPs during the time of the incident. In addition, we assume that attacker IPs most likely are not active immediately before the attack, and we do not label an IP as malicious if it was seen in the regular traffic period.
This labelling procedure is not perfect, but it allows us to label new incidents with very little time or human interaction.

Performance Metrics
We use the Precision-Recall AUC metric for model performance evaluation. The main reason for using the Precision-Recall metric is that it is more sensitive to the improvements for the positive class than the ROC (receiver operating characteristic) curve. We are less concerned about the false positive rate since, in the event that we falsely predict that an IP is doing something malicious, we won’t ban it, but only notify the rule-based attack mitigation system to challenge that specific IP. The IP will only be banned if the challenge fails.
Categorical Features
After two months of validating our approach in the production environment, we started to realize that the model was not sophisticated enough to distinguish anomalies specific only to particular clients.
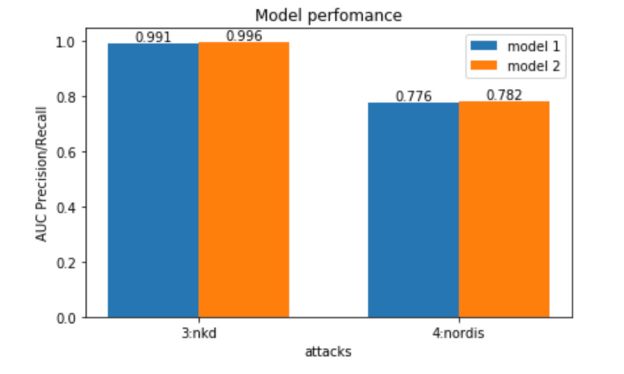
The main reason for this is that the originally published Isolation Forest algorithm supports only numerical features, and could not work with so-called categorical string values, such as hostname. First, we decided to train a separate model per target host and create an assembly of models for the final prediction. This approach over complicated the whole process and did not scale well. Additionally, we had to take care of adjusting the weights in the model assembly. In fact, we jeopardized the original idea of knowledge sharing by having a single model for all the clients. Then we tried to use the classical way of dealing with this problem: one-hot encoding. However, the deployed solution did not work well since the model became too overfit to the new hostname feature, and the performance decreased.
In the next iteration, we found another way of encoding categorical features based on a peer-review paper recently published in 2018. The main idea was not to use one-hot encoding, but rather to modify the tree-building algorithm itself. We could not find the implementation of the idea, and had to modify the source code of IForest library in Scala. We introduced a new string feature ‘hostname,’ and this time the model showed notable performance improvement in production. Moreover, our final implementation was generic and allowed us to experiment with other categorical features like country, user agent, operating system, etc.
Stratified Sampling
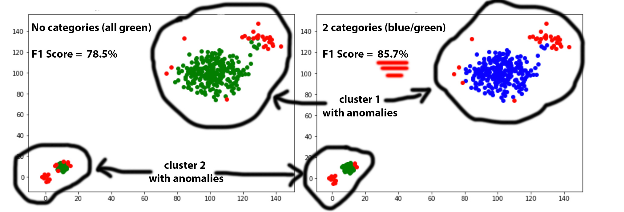
Baskerville uses a single machine learning model trained on the data received from hundreds of clients.This allows us to share the knowledge and benefit from a model trained on a global dataset of recorded incidents. However, when we first deployed Baskerville, we realized that the model is biased towards high traffic clients.
We had to find a balance in the amount of data we feed to the training pipeline from each client. On the one hand, we wanted to equalize the number of records from each client, but on the other hand, high traffic clients provided much more valuable incident information. We decided to use stratified sampling of training datasets with a single parameter: the maximum number of samples per host.
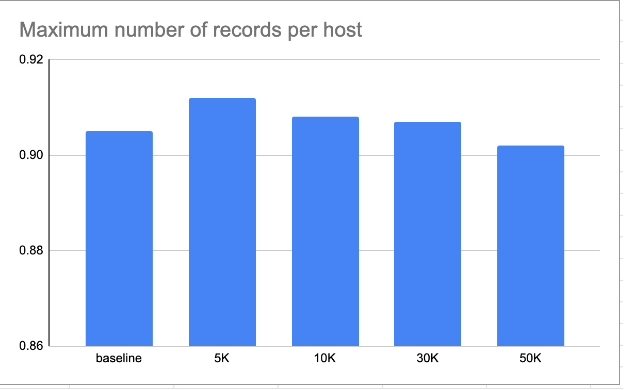
Storage
Baskerville uses Postgres to store the processed results. The request-sets table holds the results of the real-time weblogs pre-processed by our analytics engine which has an estimated input of ~30GB per week. So, within a year, we’d have a ~1.5 TB table. Even though this is within Postgres limits, running queries on this would not be very efficient. That’s where the data partitioning feature of Postgres came in. We used that feature to split the request sets table into smaller tables, each holding one week’s data. . This allowed for better data management and faster query execution.
However, even with the use of data partitioning, we needed to be able to scale the database out. Since we already had the Timescale extension for the Prometheus database, we decided to use it for Baskerville too. We followed Timescale’s tutorial for data migration in the same database, which means we created a temp table, moved the data from each and every partition into the temp table, ran the command to create a hypertable on the temp table, deleted the initial request sets table and its partitions, and, finally, renamed the temp table as ‘request sets.’ The process was not very straightforward, unfortunately, and we did run into some problems. But in the end, we were able to scale the database, and we are currently operating using Timescale in production.
We also explored other options, like TileDb, Apache Hive, and Apache HBase, but for the time being, Timescale is enough for our needs. We will surely revisit this in the future, though.
Architecture
The initial design of Baskerville was created with the assumption that Baskerville will be running under Deflect as an analytics engine, to aid the already in place rule-based attack detection and mitigation mechanism. However, the needs changed as it became necessary to open up Baskerville’s prediction to other users and make our insights available to them.
In order to allow other users to take advantage of our model, we had to redesign the pipelines to be more modular. We also needed to take into account the kind of data to be exchanged, more specifically, we wanted to avoid any exchange that would involve sensitive data, like IPs for example. The idea was that the preprocessing would happen on the client’s end, and only the resulting feature vectors would be sent, via Kafka, to the Prediction centre. The Prediction centre continuously listens for incoming feature vectors, and once a request arrives, it uses the pre-trained model to predict and send the results back to the user. This whole process happens without the exchange of any kind of sensitive information, as only the feature vectors go back and forth.
On the client side, we had to implement a caching mechanism with TTL, so that the request sets wait for their matching predictions. If the prediction center takes more than 10 minutes, the request sets expire. 10 minutes, of course, is not an acceptable amount of time, just a safeguard so that we do not keep request sets forever which can result in OOM. The ttl is configurable. We used Redis for this mechanism, as it has the ttl feature embedded, and there is a spark-redis connector we could easily use, but we’re still tuning the performance and thinking about alternatives. We also needed a separate spark application to handle the prediction to request set matching once the response from the Prediction center is received.. This application listens to the client specific Kafka topic, and once a prediction arrives, it looks into redis, fetches the matched request set, and saves everything into the database.
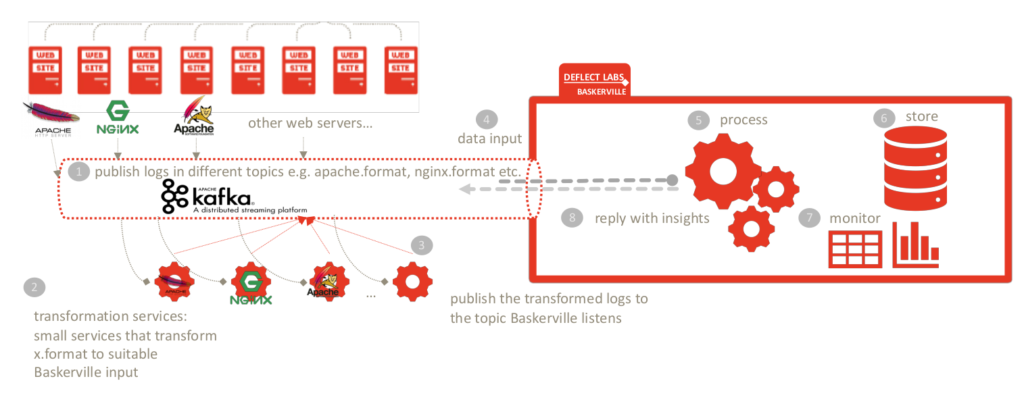
To sum up, in the new architecture, the preprocessing happens on the client’s side, the feature vectors are sent via Kafka to the Prediction centre (no sensitive data exchange), a prediction and a score for each request set is sent as a reply to each feature vector (via Kafka), and on the client side, another Spark job is waiting to consume the prediction message, match it with the respective request set, and save it to the database.
Read more about the project and download the source to try for yourself. Contact us for more information or to get help setting up Baskerville in your web environment.
