Задача: розробити та впровадити систему для отримання та обробки зворотного зв’язку від клієнтів, доповнення та вдосконалення моделі машинного навчання. Створити модель, яка гнучко адаптується до відгуків клієнтів та змін у підписах запитів, а також дає змогу динамічно впроваджувати модель, водночас не порушуючи наявну інтеграцію.
Інакше кажучи: ми створили систему помʼякшення ботнету Baskerville, щоб мати змогу реагувати на нові та постійно змінювані моделі атак на мережу Deflect. Навчання пристрою на минулих атаках: ми досягли точки, коли Baskerville може ідентифікувати більше зловмисників, ніж ті, що були зафіксовані нашими статичними правилами. Зараз нам потрібно розширити цей функціонал, щоб приймати відгуки від наших клієнтів щодо точності прогнозів та мати змогу регулярно розгортати нові моделі без перерв у роботі сервісу.
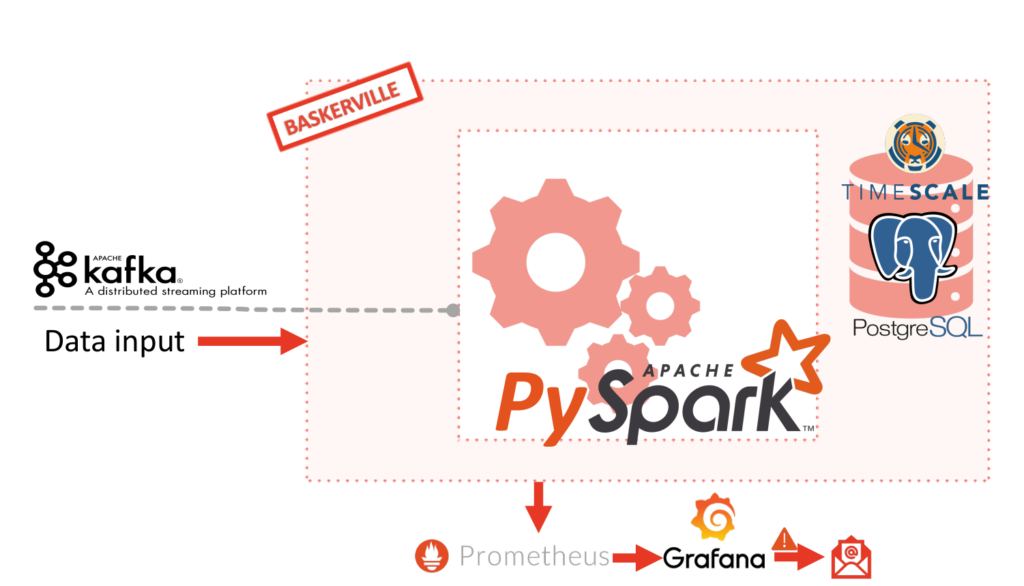
Дизайн моделі
Існує кілька підходів оновлення моделей у реальному часі. Ви можете використовувати прості файли, кеш та виклик Rest API, механізм pub-sub; ви можете використовувати серіалізовані (pickled) моделі; моделі, що зберігаються в базі даних, та багато інших механізмів і форматів. Але основна концепція однакова: або перевіряти наявність нової моделі кожні Х одиниць часу, або мати резервний сервіс, який отримує сповіщення про зміни й піклується про перезавантаження моделі на вимогу. У нашому разі ми комбінуємо підходи.
Модель потребує постійного перенавчання, щоб відстежувати постійні зміни моделей трафіку. Загальна ідея дизайну полягає в тому, щоб відокремити конвеєр генерації функцій від конвеєра прогнозування. У результаті конвеєр генерації функцій обчислює супернабір функцій, а конвеєр прогнозування дає змогу різним версіям моделі використовувати будь-яку підгрупу функцій. Крім того, модель підтримує зворотну сумісність і використовує стандартне значення у разі застарілого конвеєра генерації функцій.
Щойно нова модель стає доступною, конвеєр прогнозування виявляє це і починає використовувати її без зупинки обслуговування. Коли функції потрібно змінити, модель встановлюється так само, але модуль користувача також потрібно буде оновити і повторно налаштувати. Клієнти оновлюватимуть цей модуль з нашого git-репозиторію. Важливо зазначити, що протягом часу, необхідного для оновлення модуля користувача, нова модель зможе взаємодіяти із застарілою користувацькою моделлю та надавати прогнози як зазвичай. Відсутність нових або змінених функцій у вхідних даних моделі не порушить сумісність, оскільки для відсутніх значень будуть використовуватися стандартні значення.
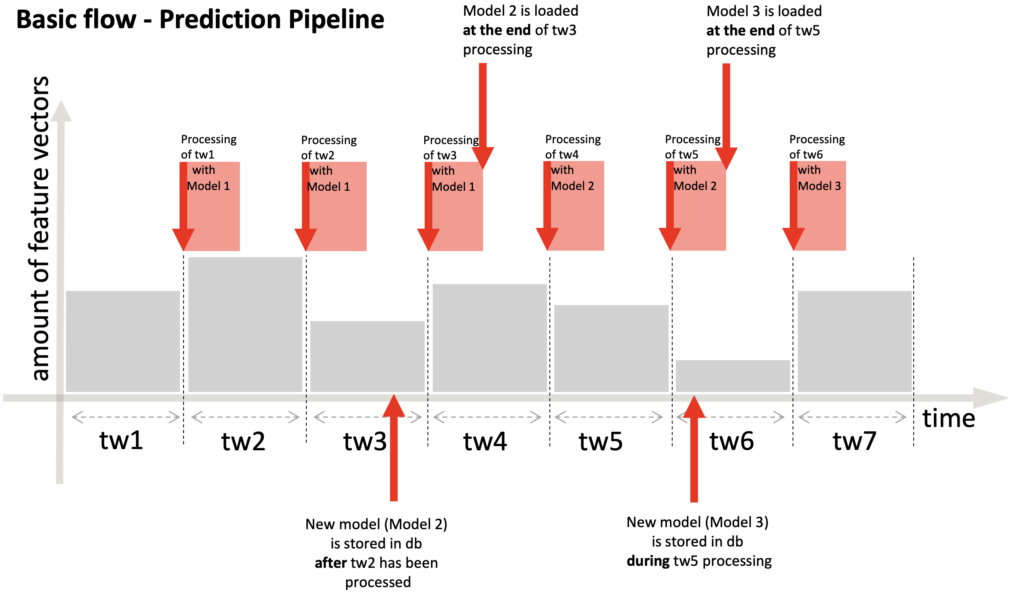
Зважаючи на те, що всі запити, отримані протягом вікна часу, повинні оброблятися однією моделлю, а зміна моделі повинна відбуватись або в кінці, або на початку періоду обробки. Для продуктивності ми вирішили помістити процес оновлення моделі в кінець PredictionPipeline, після того, як прогнози були надіслані клієнту через Kafka. Це допоможе збільшити час, необхідний клієнту для отримання прогнозів. На наступному малюнку показано, що відбувається, коли нова модель зберігається в базі даних під час і після обробки вікна часу (під час простою на очікування нового пакету). У першому разі наступне вікно часу буде оброблено зі старою моделлю, а в кінці буде завантажена нова модель. У другому разі, оскільки обробка поточного вікна часу ще не завершена, ми завантажимо нову модель в кінці обробки і наступне вікно часу матиме нову модель для роботи. Асинхронна природа навчання та прогнозування – основна причина перезавантаження. Ми провели кілька тестових запусків, щоб переконатися, що перезавантаження не впливає на продуктивність конвеєра.
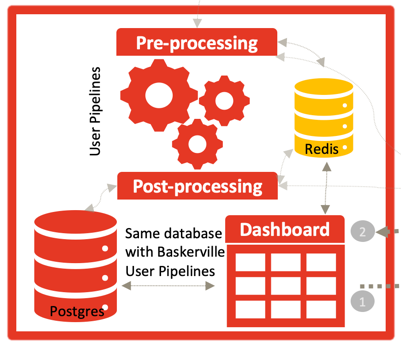
Панель зворотного зв’язку
Щоб отримати від клієнтів зворотний зв’язок (наприклад, якщо прогноз виявився неправильним), ми розробили та спроєктували графічну інформаційну панель, що складається з двох основних компонентів: серверного REST API, створеного за допомогою Python Flask з підтримкою вебсокетів через Flask-SocketIO; та зовнішнього проєкту Angular, що спирається на node та npm. Процес зворотного звʼязку складається з трьох етапів:
- Контекст відгуку: вкажіть деякі відомості про відгук, наприклад причину, період і необов’язкове поле для приміток. Причиною може бути один з наступних варіантів: атака, хибний результат, хибний негативний результат, істинний результат, істинний негативний результат тощо. Ми надаємо короткий опис кожної причини.
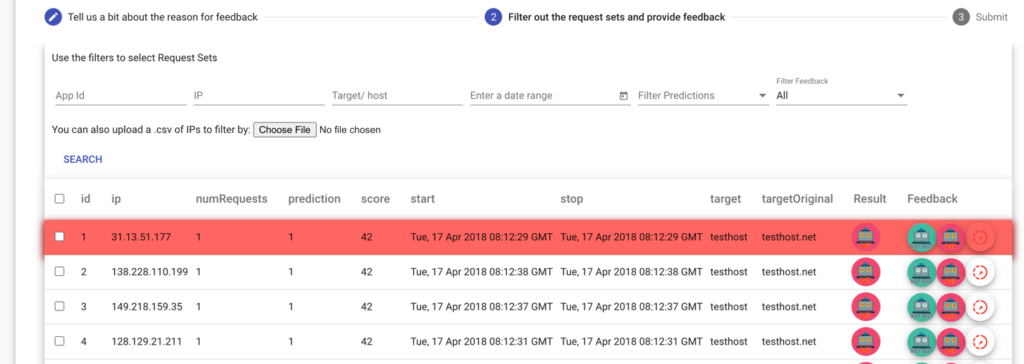
- Фільтруйте набори запитів, що стосуються відгуку, використовуючи фільтри пошуку. Користувач також може надати файл CSV з IP-адресами для використання як фільтр.
- The lОстаннім етапом є надання результатів відгуку до Baskerville (Координаційного центру). Оскільки маркування та надання зворотного зв’язку – доволі складний процес, ми розробили його так, щоб користувач міг пропустити останній крок (“Надіслати”), якщо він ще не готовий, та мав змогу надіслати результати пізніше. Координаційний центр отримає відгук у певний момент (за допомогою конфігурованого часового вікна каналу зворотного зв’язку) і, як тільки відгук буде опрацьовано, конвеєр відповість користувачеві в темі відгуку – за умовною назвою “{organization_uuid}.feedback”.
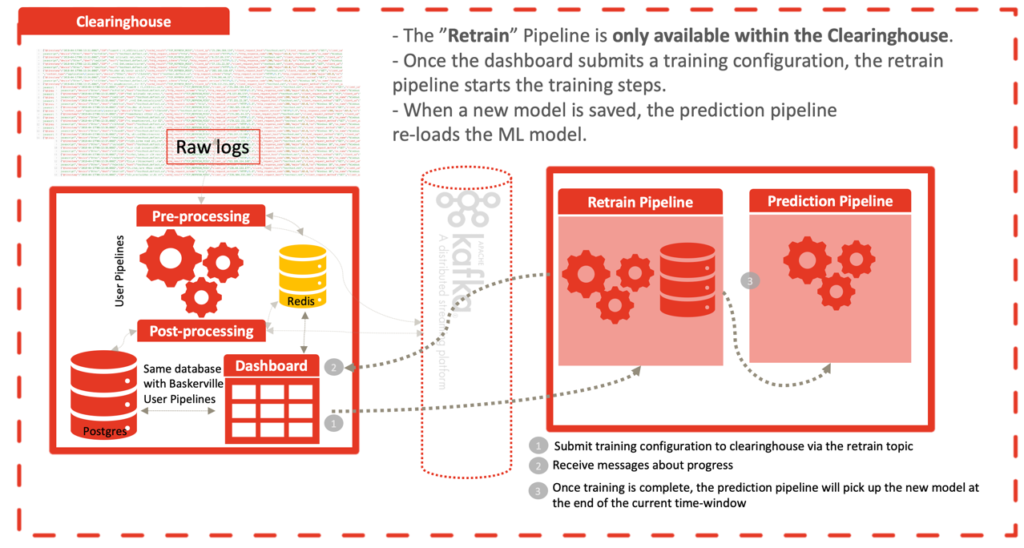
Також ми створили Retrain Pipeline, а ще сторінку інформаційної панелі, Retrain і функціонал, щоб полегшити нам періодичне оновлення моделі. Ця функція доступна лише в Clearinghouse, де розміщена модель.
Ця робота є результатом місяців кропіткої розробки, тестування та ітерацій. Якщо ви зацікавлені у використанні Baskerville на власних вебплатформах, будь ласка, зв’яжіться з нами. Наша робота доступна за ліцензією з відкритим вихідним кодом і розроблена з дотриманням принципів конфіденційності. Ми заохочуємо сторонніх розробників використовувати наш інструментарій поза екосистемою Deflect і незабаром опублікуємо ще одну статтю в блозі, в якій розповімо про запуск інформаційного центру Deflect Labs Clearinghouse. Стежте за новинами!
- Baskerville: https://github.com/equalitie/baskerville
- Baskerville User Client: https://github.com/equalitie/baskerville_client
- Baskerville Dashboard: https://github.com/equalitie/baskerville_dashboard
- Baskerville Docker components: https://github.com/equalitie/deflect-analytics-ecosystem
- Pyspark IForest fork: https://github.com/equalitie/spark-iforest