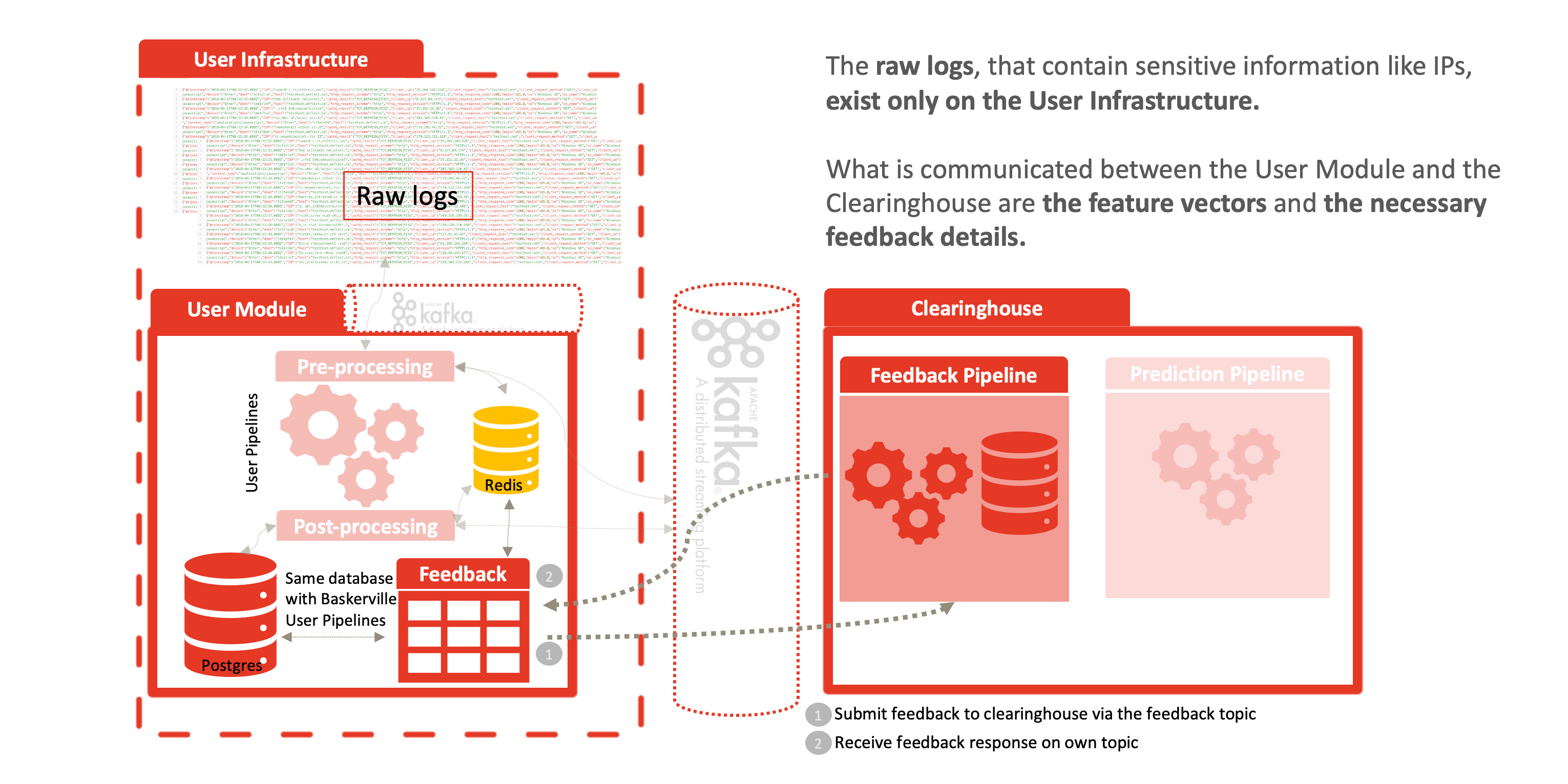
L’avenir de Deflect Labs consiste à diviser le moteur Baskerville en deux composantes distinctes : le module utilisateur et le centre d’échange. Le module utilisateur sera exécuté par les utilisateurs pour extraire des vecteurs de caractéristiques du comportement de navigation à partir de lots de leurs journaux Web entrants. Ces vecteurs de caractéristiques seront envoyés au centre d’échange, où ils seront traités et stockés par le moteur de prédiction, et une prédiction (avec un certain degré de certitude) sera renvoyée. L’utilisateur peut alors prendre les mesures d’atténuation nécessaires (par exemple, bannir, restreindre l’accès, imposer un défi captcha…) sur la base de la prédiction. En outre, le centre d’échange contiendra un centre d’analyse, où les scientifiques et les techniciens de Deflect travailleront à l’amélioration du classificateur formé utilisé dans le moteur de prédiction. Nous développerons un cadre pour fournir un retour d’information afin d’améliorer et d’évaluer ce modèle de manière itérative. Il y aura une interface web (tableau de bord) par laquelle les utilisateurs pourront facilement enregistrer les attaques qu’ils ont vues.
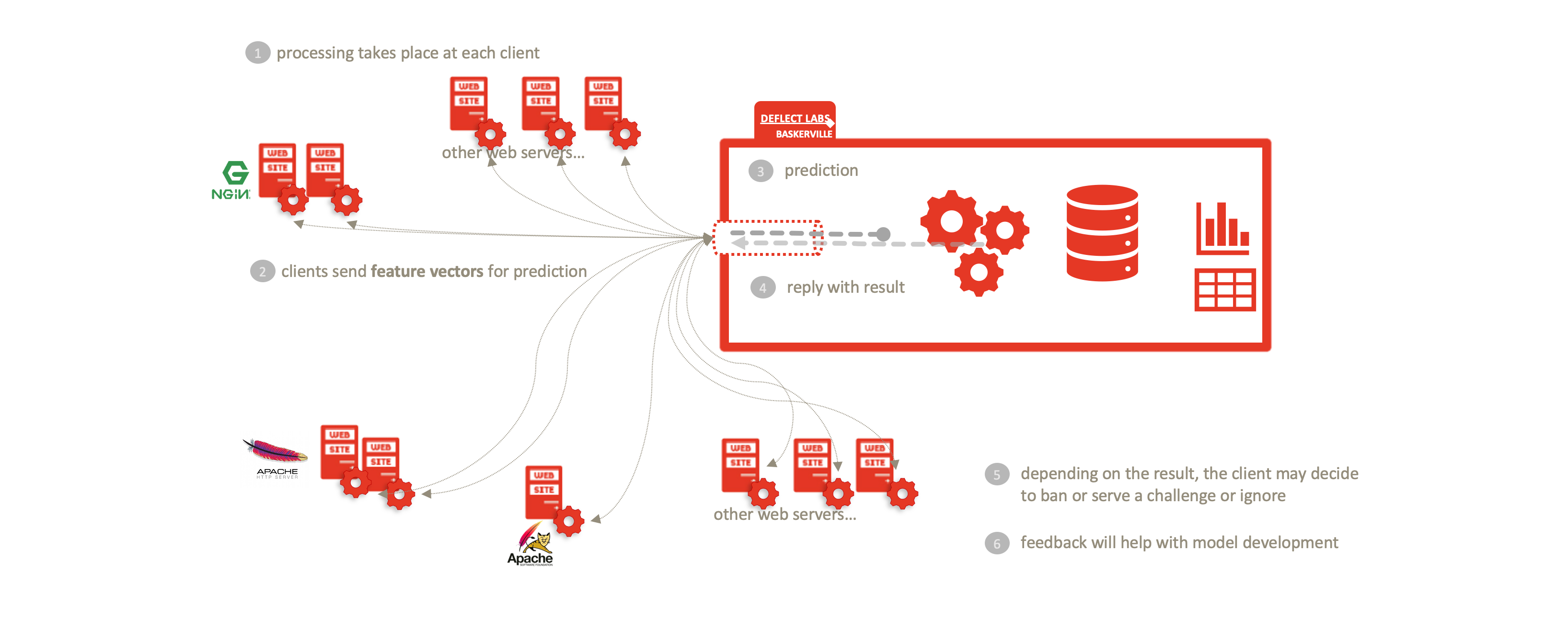
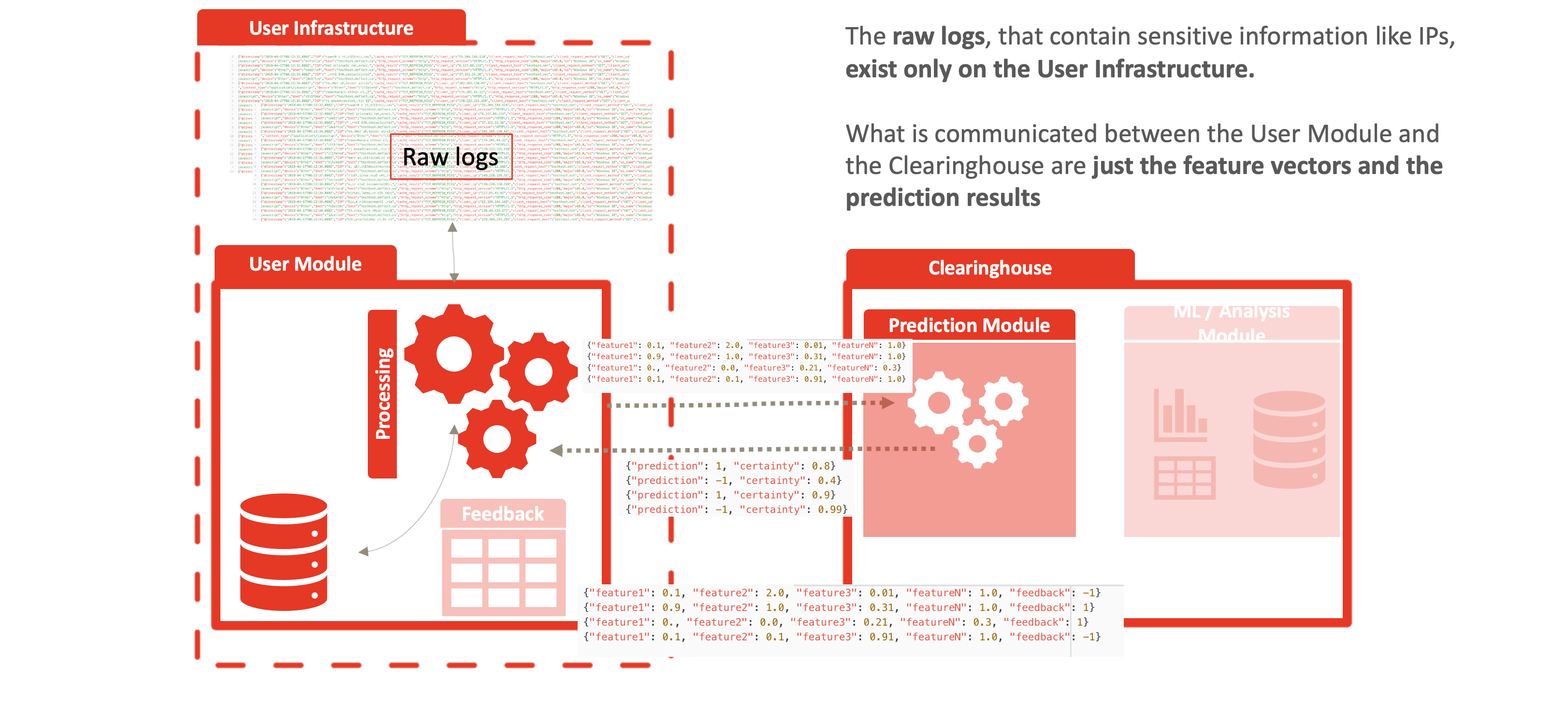
En divisant Baskerville entre le module utilisateur de traitement des logs et le moteur de prédiction décrit ci-dessus, nous permettons une séparation complète des données personnelles (logs bruts) et du centre d’échange centralisé. Les utilisateurs traitent localement leurs propres journaux web et envoient des vecteurs de caractéristiques (sans IP/site hôte) afin de recevoir une prédiction. Cela permet de partager les menaces sans compromettre la confidentialité des données personnelles inhérentes aux journaux web bruts. Cette séparation permet l’adoption de Deflect ISAC par toute partie intéressée, en dehors de l’infrastructure d’atténuation Deflect. L’augmentation du nombre d’utilisateurs de ce composant permettra également d’accroître la quantité de données de navigation comportementale que nous sommes en mesure de collecter, et donc la force des modèles que nous sommes en mesure d’entraîner.
Le centre d’analyse du centre d’échange est une extension de ce qui est actuellement la boîte à outils d’analyse hors ligne de Baskerville. Comme les vecteurs de caractéristiques utilisés par le centre d’analyse ne contiennent pas de données IP sensibles, ils peuvent être ouverts à des partenaires externes désireux de collaborer à l’élaboration d’un modèle. De même, tous les résultats de l’analyse peuvent être conservés en source ouverte.
Deflect ISAC n’utilise pas, ne se fie pas et n’échange pas de données de journal, y compris les adresses IP (qui, lorsqu’elles sont combinées avec d’autres mesures, sont des informations personnellement identifiables) entre la périphérie du réseau et l’infrastructure du centre d’échange. Cela réduit la charge de la confidentialité et de l’intégrité des données au sein de l’infrastructure du service et offre une protection contre les attaques de type « man-in-the-middle » et la surveillance du réseau. Il est important de noter que le service est conforme à toutes les réglementations modernes en matière de confidentialité des données et ne nécessite pas de confiance entre les clients qui utilisent le service ou les fournisseurs de services qui partagent la même infrastructure d’échange.
L’anonymisation vient du fait que les journaux bruts ne quittent jamais la périphérie du réseau, comme le montrent les figures suivantes. Les vecteurs de caractéristiques sont générés à la périphérie et communiqués de la manière suivante au centre d’échange :
- les vecteurs de caractéristiques, par exemple : {« feature1 » : 0.1, « feature2 » : 2.0, « feature3 » : 0.01, « featureN » : 1.0, « identifiant » : « identifiant aléatoire pour l’utilisateur afin de corréler les résultats »},
- le résultat de la prédiction : {« prédiction » : 1, « certitude » : 0.8, « identifiant » : « identifiant aléatoire pour l’utilisateur afin de corréler les résultats »} et
- le retour d’information de l’utilisateur : {« feature1 » : 0.1, « feature2 » : 2.0, « feature3 » : 0.01, « featureN » : 1.0, « prédiction » : 1, « certainty » : 0.8, « feedback » : -1}.
Une fois la prédiction calculée et renvoyée au module utilisateur, un mécanisme de retour d’information permet aux opérateurs du système de classer cette réponse comme positive, faussement positive, etc. Cette réponse est à nouveau partagée avec le centre d’échange, ce qui nous permet de déterminer la précision du modèle et de décider quand et comment l’affiner. Par exemple, si le modèle a prédit quelque chose de malveillant et que l’utilisateur a fini par bannir correctement ce comportement, avec un retour d’information positif, nous élargissons l’ensemble d’apprentissage actuel et donnons au modèle plus de données pour apprendre. Il en va de même pour les commentaires négatifs, lorsque l’utilisateur n’a pas utilisé la prédiction ou qu’elle a été considérée comme un faux positif/négatif. L’apprentissage guidé permet à notre modèle d’améliorer considérablement sa précision.