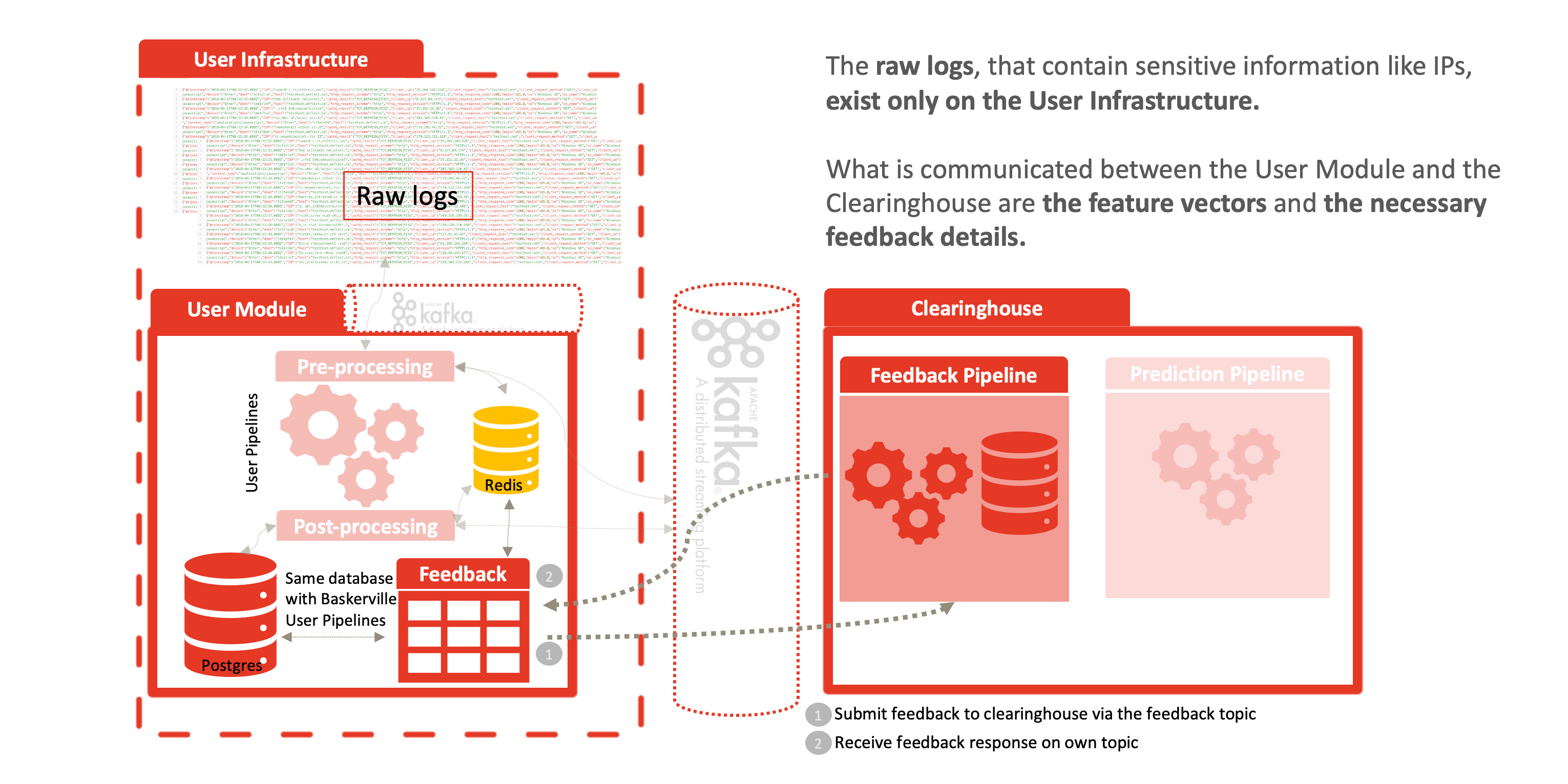
El futuro de Deflect Labs pasa por dividir el motor Baskerville en dos componentes separados: el módulo de usuario y el centro de intercambio de información. El módulo de usuario será ejecutado por los usuarios para extraer vectores de características del comportamiento de navegación a partir de lotes de sus registros web entrantes. Estos vectores se enviarán al Centro de Intercambio de Información, donde serán procesados y almacenados por el Motor de Predicción, que emitirá una predicción (con cierto grado de certeza). El usuario puede entonces tomar las medidas de mitigación necesarias (por ejemplo, prohibir, restringir el acceso, imponer un desafío captcha…) basándose en la predicción. Además, el Centro de Intercambio de Información contendrá un Centro de Análisis, donde los científicos y técnicos de datos de Deflect trabajarán para mejorar el clasificador entrenado utilizado en el Motor de Predicción. Desarrollaremos un marco de retroalimentación para mejorar y evaluar iterativamente este modelo. Habrá una interfaz web (dashboard) a través de la cual los usuarios podrán registrar fácilmente los ataques que hayan visto.
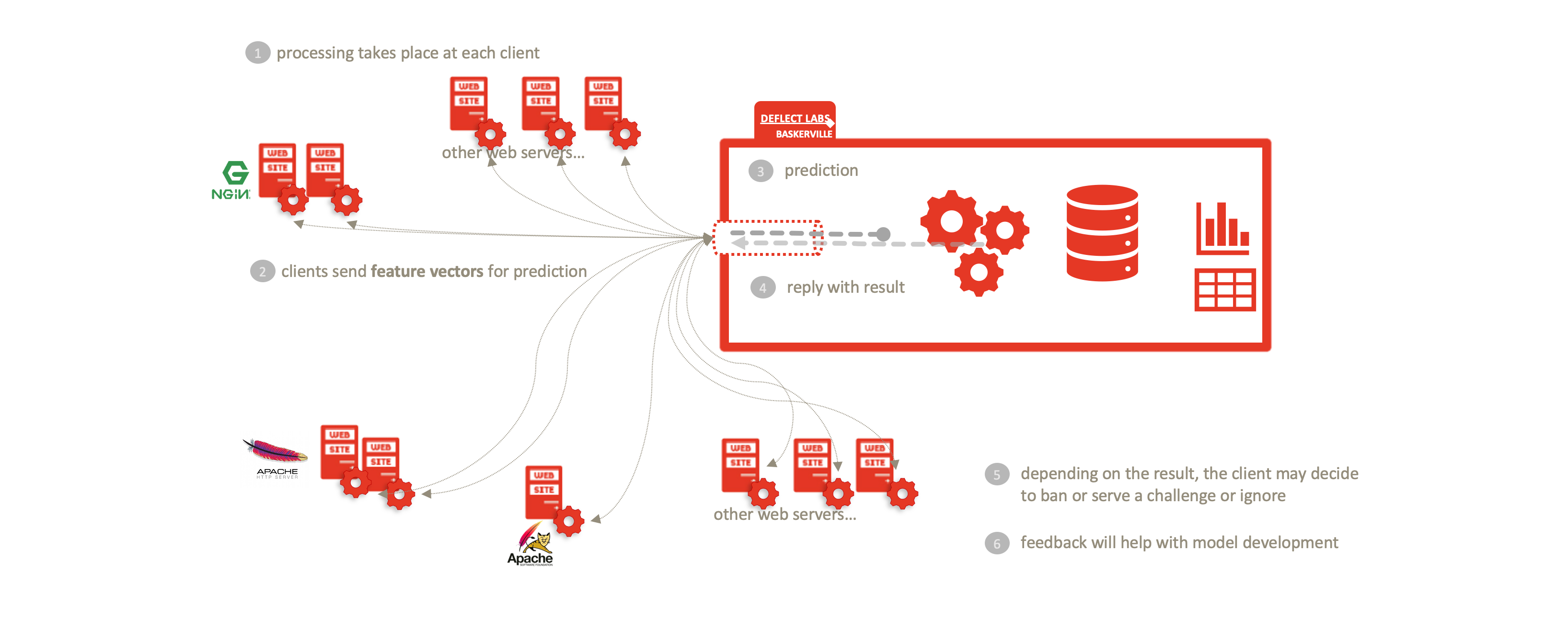
Al dividir Baskerville en el Módulo de Usuario de procesamiento de registros y el Motor de Predicción descrito anteriormente, permitimos una separación completa de los datos personales (registros en bruto) del Centro de Intercambio de Información centralizado. Los usuarios procesan sus propios registros web localmente y envían vectores de características (sin IP ni sitio web) para recibir una predicción. Esto permite compartir las amenazas sin comprometer la privacidad de los datos personales inherentes a los registros web sin procesar. Esta separación permite la adopción de Deflect ISAC por cualquier parte interesada, fuera de la infraestructura de mitigación de Deflect. El aumento de la base de usuarios de este componente también aumentará la cantidad de datos de navegación behaivoural que somos capaces de recoger, y por lo tanto la fuerza de los modelos que somos capaces de entrenar.
El componente del Centro de Análisis del Centro de Intercambio de Información es una extensión de lo que actualmente es el conjunto de herramientas de análisis offline de Baskerville. Dado que los vectores de características utilizados por el Centro de Análisis no contienen datos sensibles de propiedad intelectual de los usuarios, éste puede estar abierto a socios externos interesados en colaborar en el desarrollo de modelos. Del mismo modo, todos los resultados del análisis pueden mantenerse en código abierto.
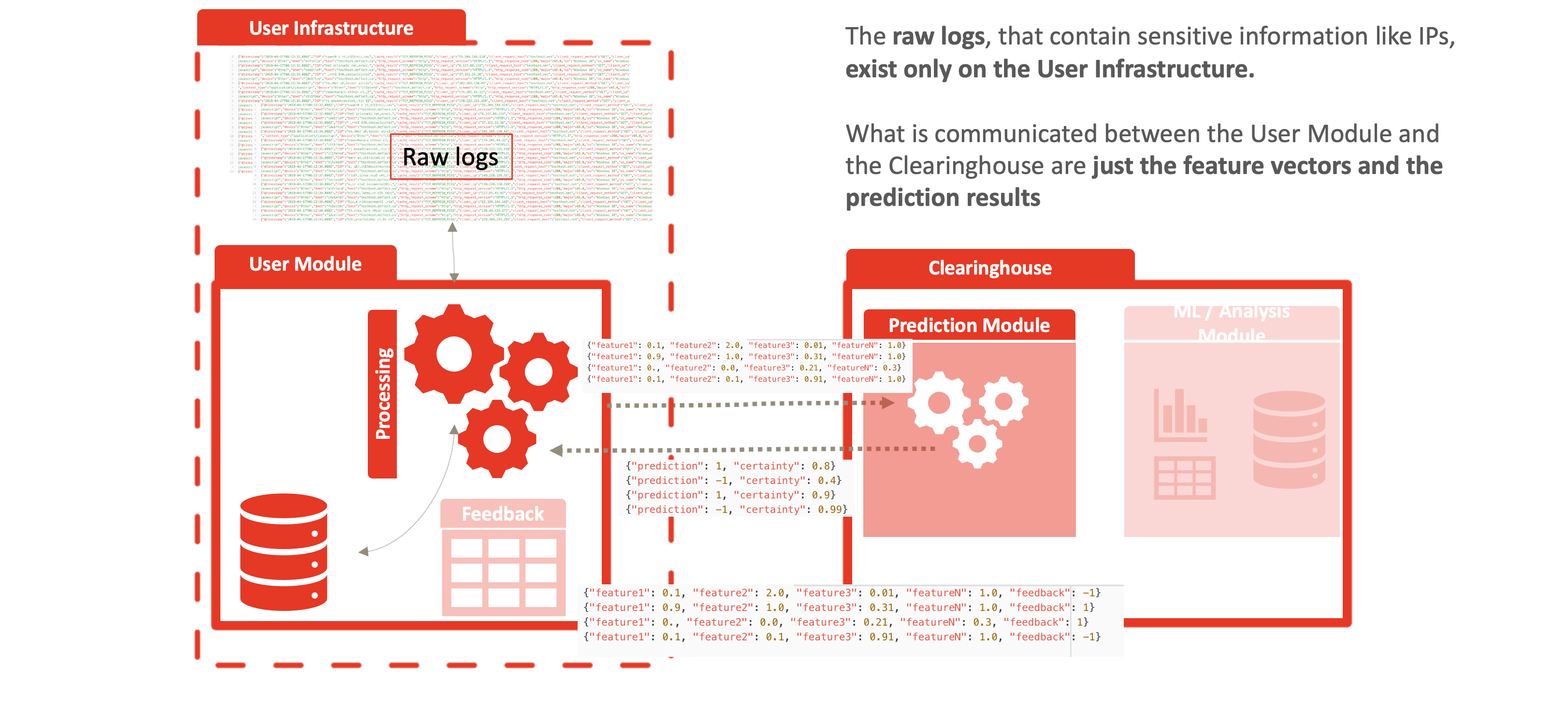
Deflect ISAC no utiliza, confía ni intercambia ningún dato de registro, incluidas las direcciones IP (que cuando se combinan con otras métricas constituyen información de identificación personal) entre el borde de la red y la infraestructura del centro de intercambio de información. Esto reduce la carga de garantizar la privacidad y la integridad de los datos dentro de la infraestructura del servicio y ofrece protección contra los ataques de intermediario y la vigilancia de la red. Y lo que es más importante, el servicio cumple todas las normativas modernas sobre privacidad de datos y no requiere confianza entre los clientes que utilizan el servicio o los proveedores de servicios que comparten la misma infraestructura de centro de intercambio de información.
La anonimización procede del hecho de que los registros en bruto nunca abandonan el borde de la red, como se muestra en las siguientes figuras. Los vectores de características se generan en el borde y se comunican de la siguiente manera al centro de intercambio de información:
- los vectores de características, por ejemplo: {“feature1”: 0.1, “feature2”: 2.0, “feature3”: 0,01, “característicaN”: 1,0, “identificador”: “identificador aleatorio para que el usuario correlacione los resultados”},
- el resultado de la predicción: {“predicción”: 1, “certeza”: 0.8, “identificador”: “identificador aleatorio para que el usuario correlacione los resultados”} y
- los comentarios de los usuarios: {“feature1”: 0.1, “feature2”: 2.0, “feature3”: 0.01, “característicaN”: 1.0, “predicción”: 1, “certeza”: 0.8, “feedback”: -1}.
Una vez calculada la predicción y enviada de vuelta al módulo de usuario, un mecanismo de retroalimentación permite a los operadores del sistema clasificar esta respuesta como positiva, falso-positiva, etc. Esta respuesta se comparte de nuevo con el centro de intercambio de información, lo que permite determinar la precisión del modelo y decidir cuándo y cómo realizar ajustes. Por ejemplo, si el modelo predijo algo como malicioso y el usuario acabó prohibiendo correctamente ese comportamiento, entonces, con una respuesta positiva, ampliamos el conjunto de entrenamiento actual y damos al modelo más datos con los que aprender. Lo mismo ocurre con la retroalimentación negativa, cuando el usuario no acaba utilizando la predicción, o se considera un falso positivo/negativo. El aprendizaje guiado permite a nuestro modelo dar pasos de gigante para mejorar su precisión.