The future of Deflect Labs involves splitting the Baskerville engine into separate User Module and Clearinghouse components. The User Module will be run by users to extract feature vectors of browsing behaviour from batches of their incoming web logs. These feature vectors will be sent to the Clearinghouse, where they will be processed and stored by the Prediction Engine, and a prediction (with a degree of certainty) will be returned. The user can then take necessary mitigation action (e.g. banning, restricting access, imposing a captcha challenge…) based on the prediction. In addition, the Clearinghouse will contain an Analysis Center, where Deflect data scientists and technicians will work to improve the trained classifier used in the Prediction Engine. We will develop a framework for providing feedback for iteratively improving and assessing this model. There will be a web interface (dashboard) through which users can easily log attacks they have seen.
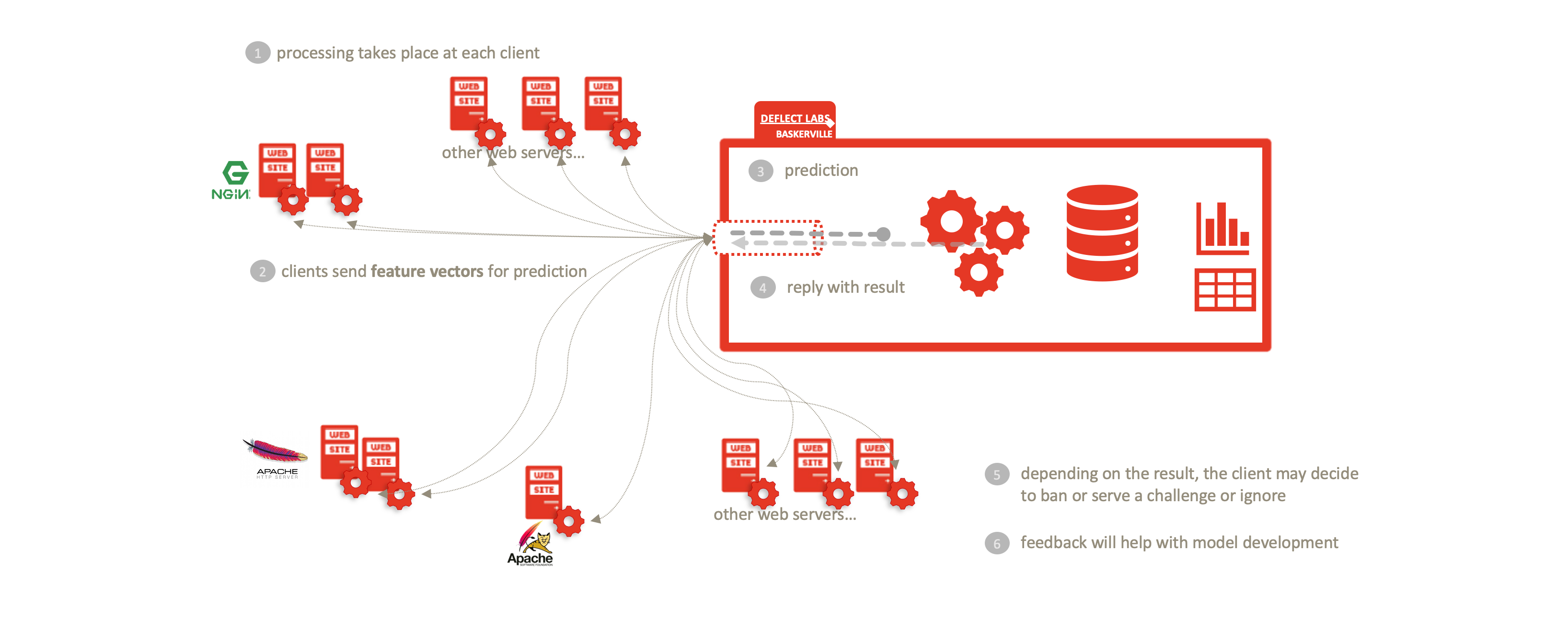
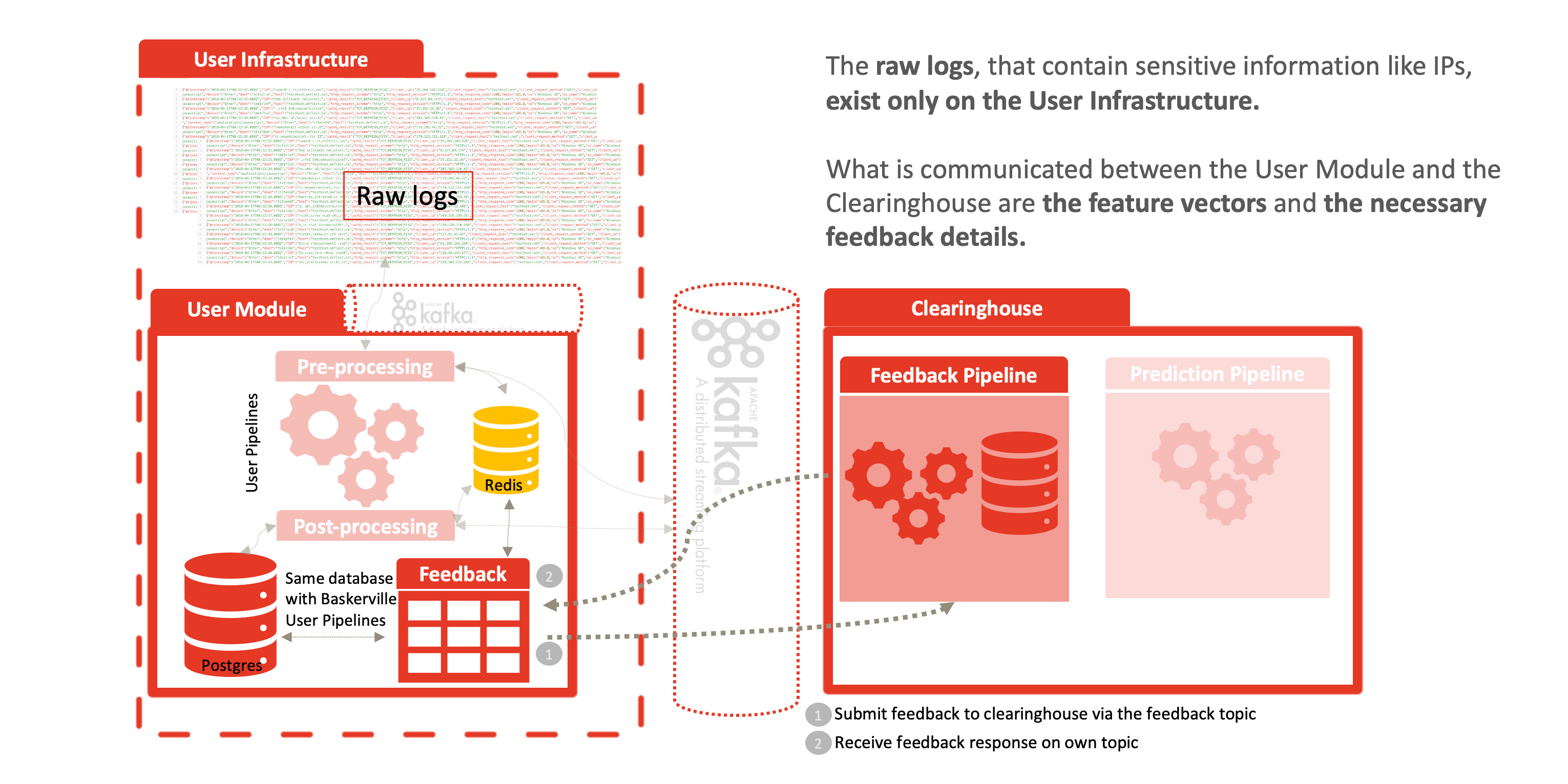
By dividing Baskerville into the log-processing User Module and the Prediction Engine described above, we enable a complete separation of personal data (raw logs) from the centralized Clearinghouse. Users process their own web logs locally, and send feature vectors (devoid of IP/host site) in order to receive a prediction. This allows threat-sharing without compromising privacy of personal data inherent in raw web logs. This separation enables Deflect ISAC adoption by any interested party, outside of the Deflect mitigation infrastructure. Increasing the user base of this component will also increase the amount of behaivoural browsing data we are able to collect, and thus the strength of the models we are able to train.
The Analysis Center component of the Clearinghouse is as an extension of what is currently the Baskerville offline analysis toolkit. As there is no sensitive user IP data contained in the feature vectors used by the Analysis Center, this can be open to external partners, interested in collaborating on model development. Similarly, all the results of the analysis can be kept open source.
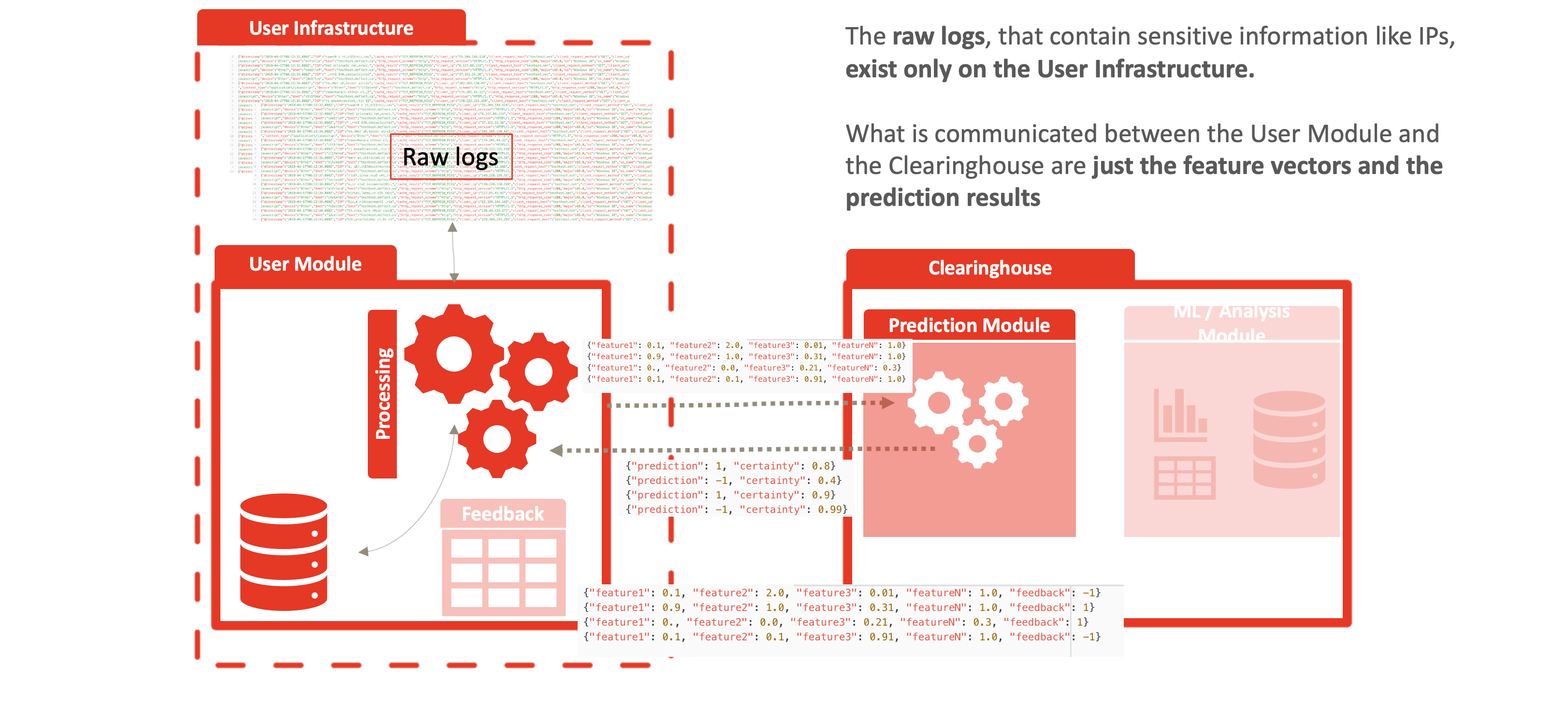
Deflect ISAC does not use, rely upon or swap any log data, including IP addresses (which when combined with other metrics is personally identifiable information) between the network edge and the clearinghouse infrastructure. This reduces the onus on ensuring data privacy and integrity within the service infrastructure and provides protection from man-in-the-middle attacks and network surveillance. Importantly, the service is compliant with all modern data privacy regulations and does not require trust between clients utilizing the service, or service providers sharing the same clearinghouse infrastructure.
The anonymization comes from the fact that raw logs never leave the network edge, as displayed in the following figures. Feature vectors are generated at the edge and communications in the following manner to the clearinghouse:
- the feature vectors, for example: {“feature1”: 0.1, “feature2”: 2.0, “feature3”: 0.01, “featureN”: 1.0, “identifier”: “random identifier for the user to correlate the results”},
- the prediction result: {“prediction”: 1, “certainty”: 0.8, “identifier”: “random identifier for the user to correlate the results”} and
- the user feedback: {“feature1”: 0.1, “feature2”: 2.0, “feature3”: 0.01, “featureN”: 1.0, “prediction”: 1, “certainty”: 0.8, “feedback”: -1}.
Once a prediction is calculated and sent back to the User Module, a feedback mechanism allows system operators to classify this reply as a positive, false-positive, etc. This reply is shared again with the clearinghouse – allowing us to determine the model’s accuracy and decide when and how to fine-tune. For example, if the model predicted something as malicious and the user ended up correctly banning that behavior, then with positive feedback, we expand on the current training set and give the model more data to learn on. The same goes for negative feedback, where the user didn’t end up using the prediction, or it was considered a false positive/ negative. Guided learning allows our model to make giant leaps in improving its accuracy.