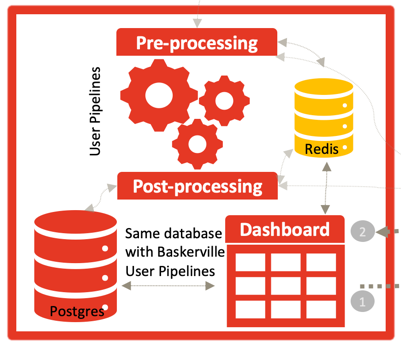
The challenge: Design and implement a system to receive and process feedback from clients, to augment and improve the machine learning model. Produce a model that has the flexibility to adapt to clients’ feedback and the changing patterns in request signatures, whilst also allowing for dynamic model deployment, without breaking existing integration.
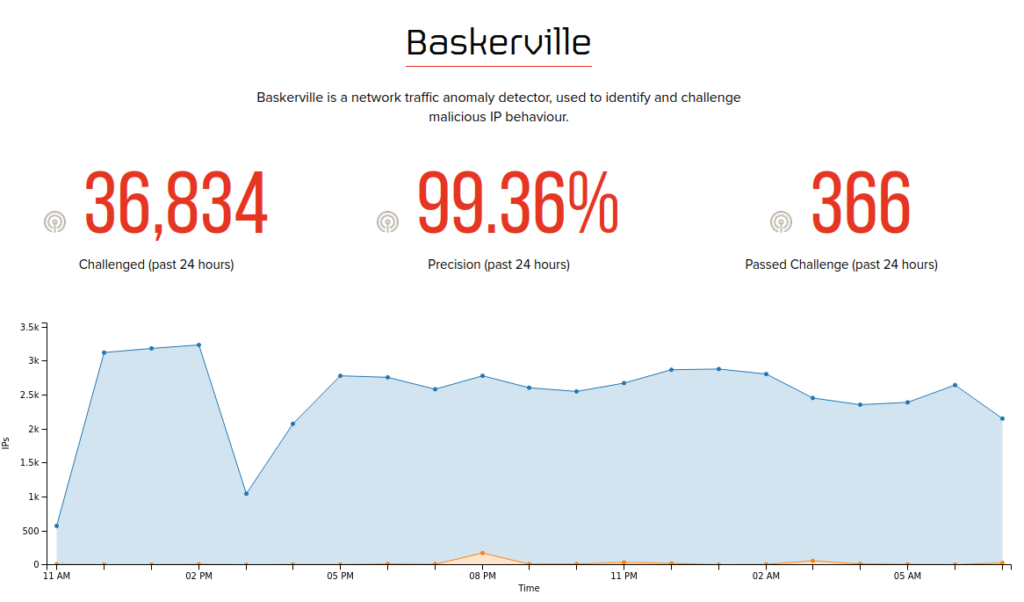
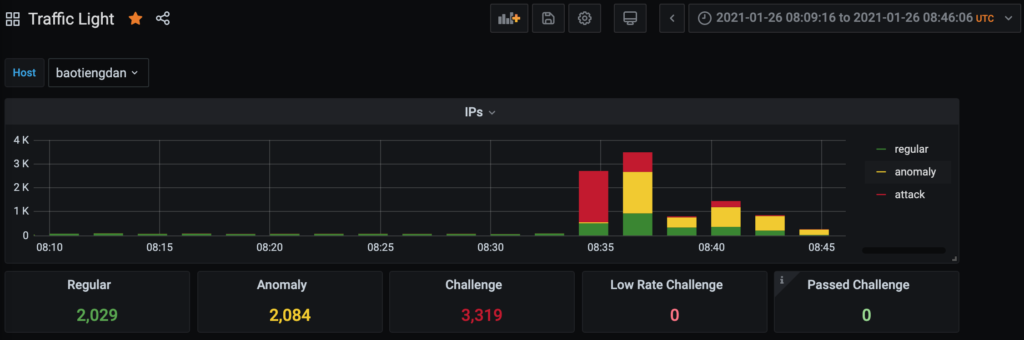
In other words: we created the Baskerville botnet mitigation system to be able to react to new and constantly changing attack patterns on the Deflect network. Training the machine on past attacks – we have reached a point where Baskerville can identify more malicious actors than what was captured by our static rules. Now, we need to grow this functionality to accept feedback from our clients on prediction accuracy and to be able to regularly deploy new models without any interruption of service.
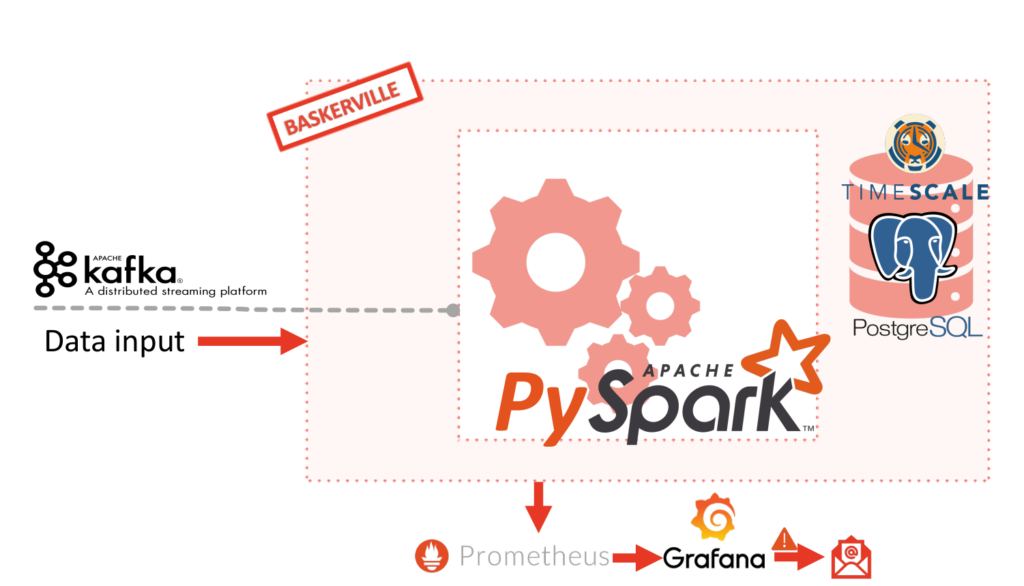
Model design
There are several approaches for live model updating. You can use simple files, or a cache and an Rest API call, or a pub-sub mechanism, you can use serialized (pickled) models, models stored in a database and many more mechanisms and formats. But the main concept is the same, either check for a new model every X time unit or have a stand by service which is notified whenever a change occurs and takes care of the model reloading – on demand. We are combining approaches for our case.
The model needs to be re-trained regularly in order to follow the constantly changing patterns of traffic. The general design idea is to decouple the feature generation pipeline from the prediction pipeline. As a result, the feature generation pipeline calculates a super-set of features and the prediction pipeline allows different model versions to use any subset of features. In addition, the model supports backward compatibility and uses the default values in case of an outdated feature generation pipeline.
As soon as a new model is available, the prediction pipeline detects this and starts using the new model without any interruption of service. When features need to be changed, the model is deployed the same way but the User Module will need to be updated and re-deployed as well. Clients will be updating this module from our git repository. It’s very important to mention that during this period required for the User Module to be updated, the new model will be able to communicate with the outdated User Model and deliver the predictions in the usual way. The lack of new or modified features in the model’s input will not break the compatibility since the defaults will be used for missing values.
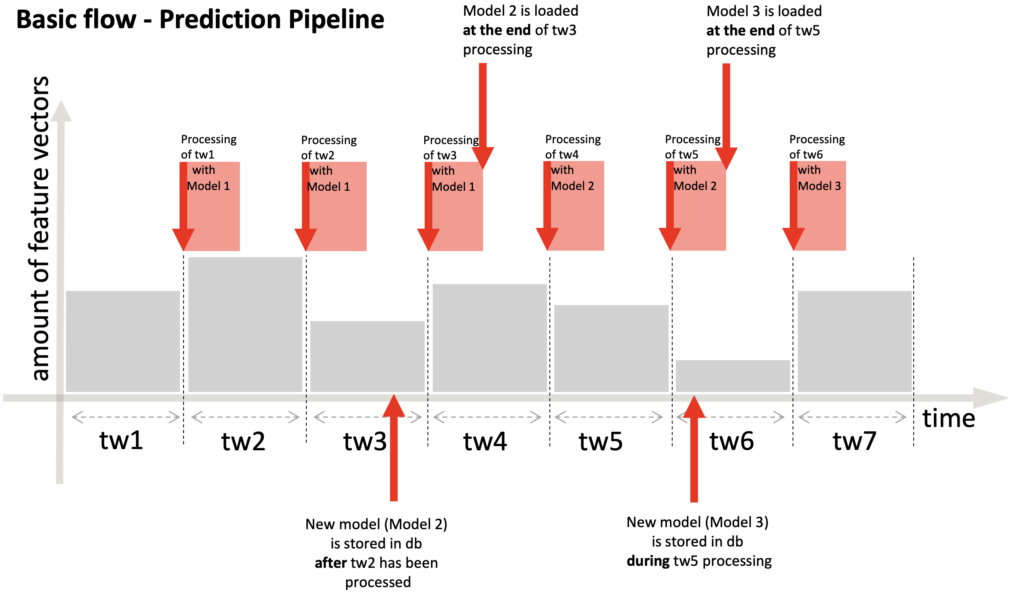
Based on the assumption that it makes sense that all the requests within a time-window should be processed by the same model, the model change should happen either at the end or at the start of the processing period. For the sake of performance, we decided to put the model updating process at the end of the PredictionPipeline, after the predictions were sent to the client via Kafka, so that we can increase the time it takes for the client to get receive predictions. The following figure explains what happens when a new model is stored in the database after a time-window has been processed (during the idle time waiting for a new batch) and during a time-window processing. In the first case, the next time-window will be processed with the old model and at the end the new one will be loaded. In the second case, since the processing of the current time window has not completed yet, we will load the new model at the end of it and the next time-window will have the fresh model to work with. The asynchronous nature of the training and the predicting is the reason behind the design of the reloading. We ran several test runs to make sure the reloading did not affect the performance of the pipeline.
Feedback Dashboard
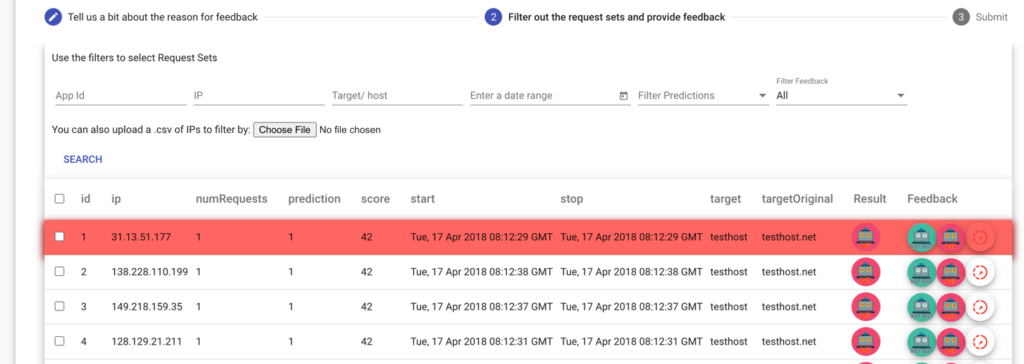
In order to receive curated feedback from clients (e.g. the prediction was incorrect) we developed and designed a graphical dashboard consisting of two main components: the back-end REST API built using Python Flask with web-socket support via Flask-SocketIO; and the front-end Angular project, relying on node and npm. The feedback process consists of three steps:
- Feedback Context: provide some details about the feedback, like reason, period and an optional notes field. The reason can be one of the following: attack, false positive, false negative, true positive, true negative or other. We provide a short description for each reason option.
- Filter out the request sets relevant to the feedback using the search filters. The user can also provide a csv files with IPs to use as a filter.
- The last step is for the user to submit the feedback results to Baskerville (Clearinghouse). Because labelling and providing feedback is a painstaking process, we designed the process in a way that the user can omit the last step (submit) if they are not ready yet, and can choose to submit later on. The Clearinghouse will receive the feedback at some point (configurable time window of feedback pipeline) and once the feedback is processed, the pipeline will reply to the user feedback reply topic – which by convention is “{organization_uuid}.feedback”.
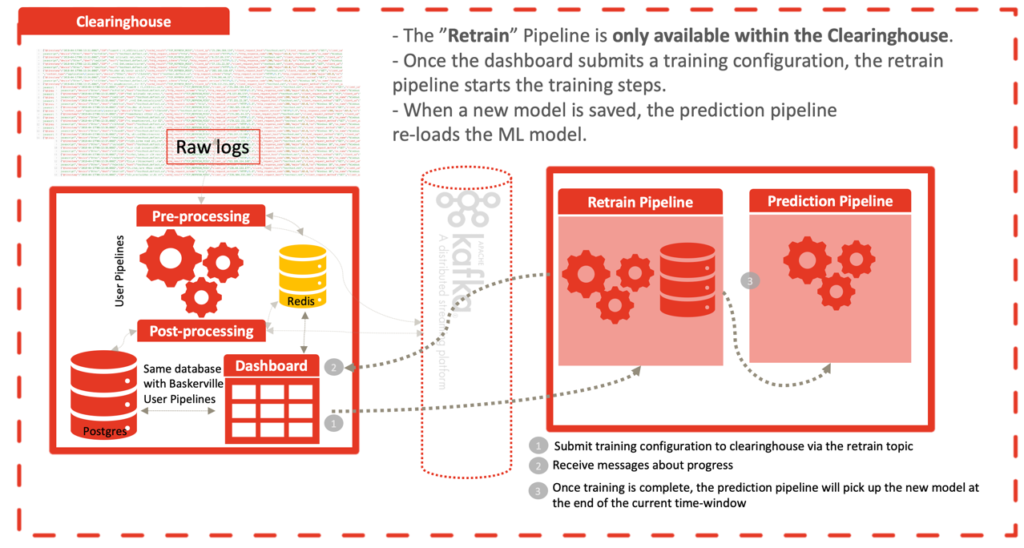
We also created a Retrain Pipeline as well as a Retrain dashboard page and functionality to make it easier for us to do periodic model updates. This functionality is only available within the Clearinghouse where the model resides.
This work is a result of months of painstaking development, testing and iteration. If you are interested in trying out Baskerville on your own web platforms, please get in touch. Our work is available under an open source licence and is developed with privacy-by-design principles. We encourage third-party adoptions of our tooling, outside of the Deflect ecosystem and will be publishing another blog post in the very near future outlining the launch of the Deflect Labs Clearinghouse. Watch this space!
- Baskerville: https://github.com/equalitie/baskerville
- Baskerville User Client: https://github.com/equalitie/baskerville_client
- Baskerville Dashboard: https://github.com/equalitie/baskerville_dashboard
- Baskerville Docker components: https://github.com/equalitie/deflect-analytics-ecosystem
- Pyspark IForest fork: https://github.com/equalitie/spark-iforest