Deflect’s service has proven itself to be reliable, stable, and easy to manage. The support team is attentive and always ready to solve any problem. Any socially responsible business should know that by choosing Deflect, it is supporting dozens of non-profit, charitable, volunteer, and human rights organizations.
Roman Zholud, Chief of the Information Services Department at Mass Media Defence Centre
The Deflect team has been protecting Osservatorio Balcani Caucaso Transeuropa since 2013, when our website was subjected to repeated DDoS attacks, and hackers asked for the removal of “inconvenient” articles, threatening to completely obscure our service to our readers. Back then, the Deflect team promptly reacted to the threat, offering us their support, and ever since it has protected our site completely free of charge, in what we believe is an exemplary case of what “global social responsibility” can be. Thanks to their protection, during these last years we have been able to keep working without suffering new attacks. Deflect’s contribution to OBCT’s work may be invisible to our public, but is nonetheless fundamental: that’s why we want to publicly say thanks to the Deflect team for its daily commitment to defending the right to free expression online.
Roberto Antoniazzi, OpenWeb
On behalf of Osservatorio Balcani e Caucaso (OBC), the Italian nonprofit media organization I direct, I would like to express our gratitude and appreciation for the cyber-protection services you are currently offering us. During the past few months, OBC has been the target of persistent and intense DDoS attacks, most likely launched from abroad and aimed at intimidating us. Needless to say, these attacks provoked a great deal of preoccupation and endangered the work we have been carrying out for more than 13 years, but we could not compromise the quality and reliability of the news we publish and tried our best to protect ourselves. As a short-term emergency measure, we turned to a premium mitigation system that in no way could be economically sustainable in the medium and long-run for a small organization like ours. Very soon after, we were surprised to receive your offer and precious solidarity that has allowed us to start again focusing on our mission, that is to say the production of news, research, and training, and the dissemination of activities on the democratization processes of South-east Europe and the Caucasus. Your help made us feel less vulnerable and also part of a wider spectrum of CSO’s committed to protecting rights, justice, and peace worldwide. Thank you once more for your solidarity and friendship, and, of course, for the protection you guarantee.
Luisa Chiodi, Director at Osservatorio Balcani e Caucaso
We came to know Deflect in June of 2012, when violence broke out in the Rakhine state of Myanmar, Burma. Our website, the first Rohingya News Agency, had been continuously attacked and went down. The Deflect team brought it back on-line and are still protecting it today.
Ronnie, Director at Arakan Rohingya National Organisation
eQualitie really saved the day for us when our website was being attacked by the far-right, which caused us to lose our hosting. You all stepped in, offered to host the site (and refused our offer to pay!), and protected us from future attacks with Deflect. We are a grassroots, volunteer-run anarchist community space funded by individual donations, and eQualitie’s support was crucial for us in having the resiliency to get through those times. It allowed us to keep our main website online, but also our library catalogue (largest free library of political books in Hamilton) and our fundraising platform (used pretty heavily for regional anti-repression work).
We basically liked everything, particularly the principles with regards to respect for privacy and data ownership– we’re assured that Deflect won’t sell our data. It also has better integration of the Let’s encrypt SSL certificate. We don’t have to worry about renewing it every 3 months because Deflect has it included in its workflow/process. The support is responsive and helpful!
This site is a public resource that has provided a wide range of information about local government and community problems in the Prirpin region since 2013. This is the main communication platform for Prirpin communities.
Thank you so much for your support in getting it back up and running and also for Deflect’s general support of nonprofits. It’s vital that our Ugandan team can communicate their work to their own networks, and we’re very grateful to have found a way to make that possible.
Esther Smitheram, Communications Manager, Children on the Edge
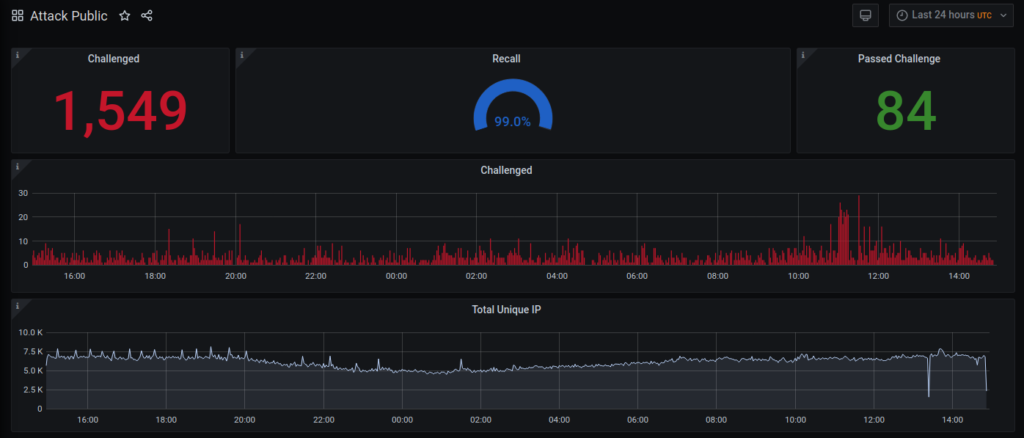
Baskerville is a machine operating on the Deflect network that protects sites from hounding, malicious bots. It’s also an open source project that, in time, will be able to reduce bad behaviour on your networks too. Baskerville responds to web traffic, analyzing requests in real-time, and challenging those acting suspiciously. A few months ago, Baskerville passed an important milestone – making its own decisions on traffic deemed anomalous. The quality of these decisions (recall) is high and Baskerville has already successfully mitigated many sophisticated real-life attacks.
We’ve trained Baskerville to recognize what legitimate traffic on our network looks like, and how to distinguish it from malicious requests attempting to disrupt our clients’ websites. Baskerville has turned out to be very handy for mitigating DDoS attacks, and for correctly classifying other types of malicious behaviour.
Baskerville is an important contribution to the world of online security – where solid web defences are usually the domain of proprietary software companies or complicated manual rule-sets. The ever-changing nature and patterns of attacks makes their mitigation a continuous process of adaptation. This is why we’ve trained a machine how to recognize and respond to anomalous traffic. Our plans for Baskerville’s future will enable plug-and-play installation in most web environments and privacy-respecting exchange of threat intelligence data between your server and the Baskerville clearinghouse.
Chapter 2 – Background
Web attacks are a threat to democratic voices on the Internet. Botnets deploy an arsenal of methods, including brute force password login, vulnerability scanning, and DDoS attacks, to overwhelm a platform’s hosting resources and defences, or to wreak financial damage on the website’s owners. Attacks become a form of punishment, intimidation, and most importantly, censorship, whether through direct denial of access to an Internet resource or by instilling fear among the publishers. Much of the development to-date in anomaly detection and mitigation of malicious network traffic has been closed source and proprietary. These silo-ed approaches are limiting when dealing with constantly changing variables. They are also quite expensive to set-up, with a company’s costs often offset by the sale or trade of threat intelligence gathered on the client’s network, something Deflect does not do or encourage.
Since 2010, the Deflect project has protected hundreds of civil society and independent media websites from web attacks, processing over a billion monthly website requests from humans and bots. We are now bringing internally developed mitigation tooling to a wider audience, improving network defences for freedom of expression and association on the internet.
Baskerville was developed over three years by eQualitie’s dedicated team of machine learning experts. Several challenges or ambitions were presented to the team. To make this an effective solution to the ever-growing need for humans to perform constant network monitoring, and the never-ending need to create rules to ban newly discovered malicious network behaviour, Baskerville had to:
Be fast enough to make it count
Be able to adapt to changing traffic patterns
Provide actionable intelligence (a prediction and a score for every IP)
Provide reliable predictions (probation period & feedback)
Baskerville works by analyzing HTTP traffic bound for your website, monitoring the proportion of legitimate vs anomalous traffic. On the Deflect network, it will trigger a Turing challenge to an IP address behaving suspiciously, thereafter confirming whether a real person or a bot is sending us requests.
Chapter 3 – Baskerville Learns
To detect new evolving threats, Baskerville uses the unsupervised anomaly detection algorithm Isolation Forest. The majority of anomaly detection algorithms construct a profile of normal instances, then classify instances that do not conform to the normal profile as anomalies. The main problem with this approach is that the model is optimized to detect normal instances, but not optimized to detect anomalies causing either too many false alarms or too few anomalies. In contrast, Isolation Forest explicitly isolates anomalies rather than profiling normal instances. This method is based on a simple assumption: ‘Anomalies are few, and they are different’. In addition, the Isolation Forest algorithm does not require a training set to contain normal instances only. Moreover, the algorithm performs even better if the training set contains some anomalies, or attack incidents in our case. This enables us to re-train the model regularly on all the recent traffic without any labeling procedure in order to adapt to the changing patterns.
Labelling
Despite the fact that we don’t need labels to train a model, we still need a labelled dataset of historical attacks for parameter tuning. Traditionally, labelling is a challenging procedure since it requires a lot of manual work. Every new attack must be reported and investigated, and every IP should be labelled either malicious or benign.
Our production environment reports several incidents a week, so we designed an automated procedure of labelling using a machine model trained on the same features we use for the Isolation Forest anomaly detection model.
We reasoned that if an attack incident has a clearly visible traffic spike, we can assume that the vast majority of the IPs during this period are malicious, and we can train a classifier like Random Forest particularly for this incident. The only user input would be the precise time period for that incident and for the time period for ordinal traffic for that host. Such a classifier would not be perfect, but it would be good enough to be able to separate some regular IPs from the majority of malicious IPs during the time of the incident. In addition, we assume that attacker IPs most likely are not active immediately before the attack, and we do not label an IP as malicious if it was seen in the regular traffic period.
This labelling procedure is not perfect, but it allows us to label new incidents with very little time or human interaction.
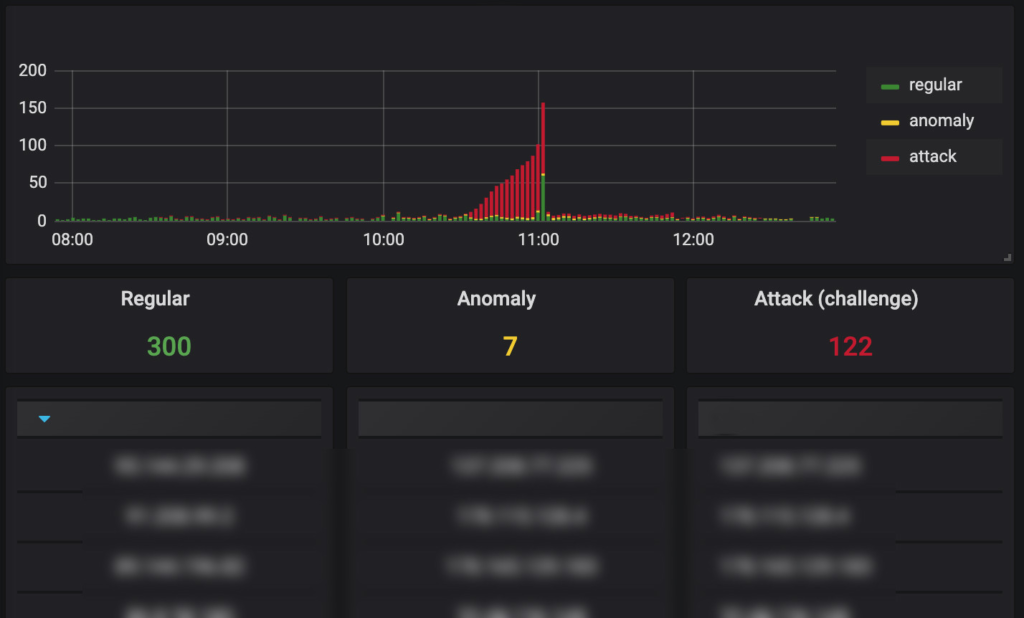
An example of the labelling procedure output
Performance Metrics
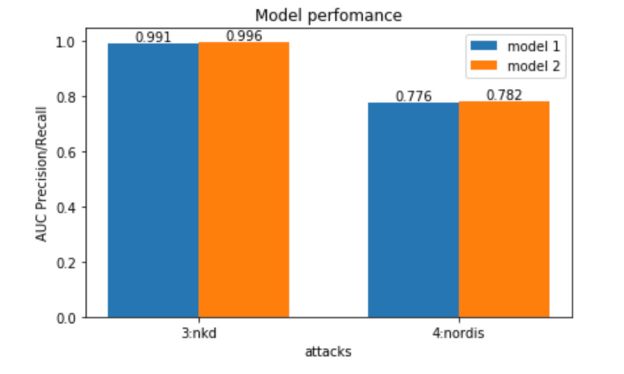
We use the Precision-Recall AUC metric for model performance evaluation. The main reason for using the Precision-Recall metric is that it is more sensitive to the improvements for the positive class than the ROC (receiver operating characteristic) curve. We are less concerned about the false positive rate since, in the event that we falsely predict that an IP is doing something malicious, we won’t ban it, but only notify the rule-based attack mitigation system to challenge that specific IP. The IP will only be banned if the challenge fails.
The performance of two different models on two different attacks
Categorical Features
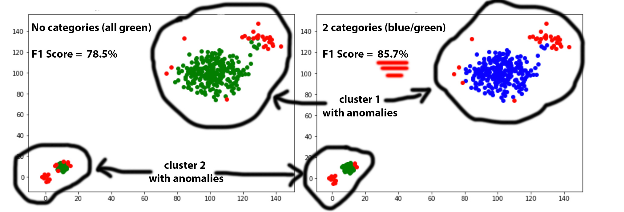
After two months of validating our approach in the production environment, we started to realize that the model was not sophisticated enough to distinguish anomalies specific only to particular clients.
The main reason for this is that the originally published Isolation Forest algorithm supports only numerical features, and could not work with so-called categorical string values, such as hostname. First, we decided to train a separate model per target host and create an assembly of models for the final prediction. This approach over complicated the whole process and did not scale well. Additionally, we had to take care of adjusting the weights in the model assembly. In fact, we jeopardized the original idea of knowledge sharing by having a single model for all the clients. Then we tried to use the classical way of dealing with this problem: one-hot encoding. However, the deployed solution did not work well since the model became too overfit to the new hostname feature, and the performance decreased.
In the next iteration, we found another way of encoding categorical features based on a peer-review paper recently published in 2018. The main idea was not to use one-hot encoding, but rather to modify the tree-building algorithm itself. We could not find the implementation of the idea, and had to modify the source code of IForest library in Scala. We introduced a new string feature ‘hostname,’ and this time the model showed notable performance improvement in production. Moreover, our final implementation was generic and allowed us to experiment with other categorical features like country, user agent, operating system, etc.
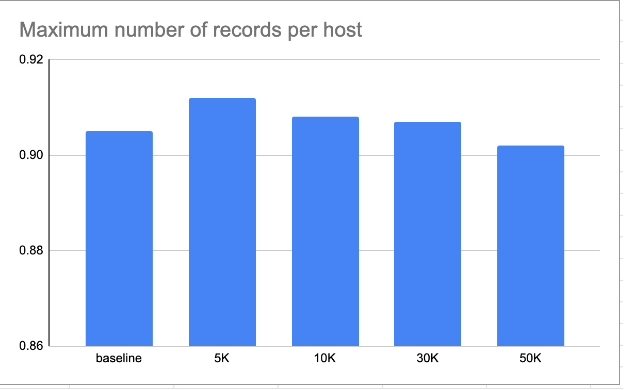
Stratified Sampling
Baskerville uses a single machine learning model trained on the data received from hundreds of clients.This allows us to share the knowledge and benefit from a model trained on a global dataset of recorded incidents. However, when we first deployed Baskerville, we realized that the model is biased towards high traffic clients.
We had to find a balance in the amount of data we feed to the training pipeline from each client. On the one hand, we wanted to equalize the number of records from each client, but on the other hand, high traffic clients provided much more valuable incident information. We decided to use stratified sampling of training datasets with a single parameter: the maximum number of samples per host.
Storage
Baskerville uses Postgres to store the processed results. The request-sets table holds the results of the real-time weblogs pre-processed by our analytics engine which has an estimated input of ~30GB per week. So, within a year, we’d have a ~1.5 TB table. Even though this is within Postgres limits, running queries on this would not be very efficient. That’s where the data partitioning feature of Postgres came in. We used that feature to split the request sets table into smaller tables, each holding one week’s data. . This allowed for better data management and faster query execution.
However, even with the use of data partitioning, we needed to be able to scale the database out. Since we already had the Timescale extension for the Prometheus database, we decided to use it for Baskerville too. We followed Timescale’s tutorial for data migration in the same database, which means we created a temp table, moved the data from each and every partition into the temp table, ran the command to create a hypertable on the temp table, deleted the initial request sets table and its partitions, and, finally, renamed the temp table as ‘request sets.’ The process was not very straightforward, unfortunately, and we did run into some problems. But in the end, we were able to scale the database, and we are currently operating using Timescale in production.
We also explored other options, like TileDb, Apache Hive, and Apache HBase, but for the time being, Timescale is enough for our needs. We will surely revisit this in the future, though.
Architecture
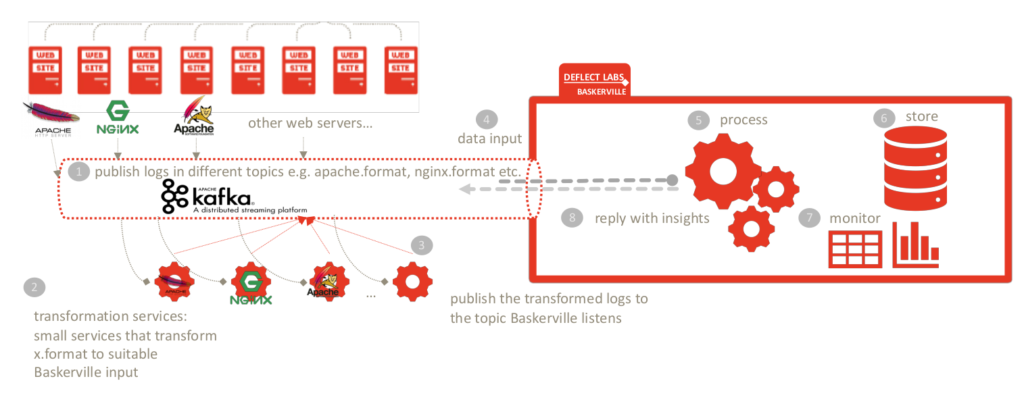
The initial design of Baskerville was created with the assumption that Baskerville will be running under Deflect as an analytics engine, to aid the already in place rule-based attack detection and mitigation mechanism. However, the needs changed as it became necessary to open up Baskerville’s prediction to other users and make our insights available to them.
In order to allow other users to take advantage of our model, we had to redesign the pipelines to be more modular. We also needed to take into account the kind of data to be exchanged, more specifically, we wanted to avoid any exchange that would involve sensitive data, like IPs for example. The idea was that the preprocessing would happen on the client’s end, and only the resulting feature vectors would be sent, via Kafka, to the Prediction centre. The Prediction centre continuously listens for incoming feature vectors, and once a request arrives, it uses the pre-trained model to predict and send the results back to the user. This whole process happens without the exchange of any kind of sensitive information, as only the feature vectors go back and forth.
On the client side, we had to implement a caching mechanism with TTL, so that the request sets wait for their matching predictions. If the prediction center takes more than 10 minutes, the request sets expire. 10 minutes, of course, is not an acceptable amount of time, just a safeguard so that we do not keep request sets forever which can result in OOM. The ttl is configurable. We used Redis for this mechanism, as it has the ttl feature embedded, and there is a spark-redis connector we could easily use, but we’re still tuning the performance and thinking about alternatives. We also needed a separate spark application to handle the prediction to request set matching once the response from the Prediction center is received.. This application listens to the client specific Kafka topic, and once a prediction arrives, it looks into redis, fetches the matched request set, and saves everything into the database.
To sum up, in the new architecture, the preprocessing happens on the client’s side, the feature vectors are sent via Kafka to the Prediction centre (no sensitive data exchange), a prediction and a score for each request set is sent as a reply to each feature vector (via Kafka), and on the client side, another Spark job is waiting to consume the prediction message, match it with the respective request set, and save it to the database.
Read more about the project and download the source to try for yourself. Contact us for more information or to get help setting up Baskerville in your web environment.
Deflect responds to the COVID19 emergency with free services
In response and solidarity with numerous efforts that have sprung up to help with communications, coordination and outreach during the COVID-19 epidemic, eQualitie is offering Deflect website security and content delivery services for free until the end of 2020 to organizations and individuals working to help others during this difficult time. This includes:
Availability: as demand for your content grows, our worldwide infrastructure will ensure that your website remains accessible and fast
Security: protecting your website from malicious bots and hackers
Hosting: for existing or new WordPress sites
Aanalytics: view real-time statistics in the Deflect dashboard
Deflect is always offered free of charge to not-for-profit entities that meet our eligibility requirements. This offer extends our free services to any business or individual that is responding to societal needs during the pandemic, including media organizations, government, online retail and hospitality services, etc. We will review all applications to make sure they align with Deflect’s Terms of Use.
It takes 15 minutes to set up and we’ll have you protected on the same day. Our support team can help you in English, French, Chinese, Spanish and Russian. If you have any questions please contact us.
The attacks leading to the publication of this report quickly stood out from the daily onslaught of malicious traffic on Deflect, at first because they were using professional vulnerability scanning tools like Acunetix. The moment we discovered that the origin server of these scans was also hosting fake gmail domains, it became evident that something bigger was going on here. In this report, we describe all the pieces put together about this campaign, with the hope to contribute to public knowledge about the methods and impact of such attacks against civil society.
Context : Human Rights and Surveillance in Uzbekistan
Emblem of Uzbekistan (wikipedia)
Uzbekistan is defined by many human-rights organizations as an authoritarian state, that has known strong repression of civil society. Since the collapse of the Soviet Union, two presidents have presided over a system that institutionalized torture and repressed freedom of expression, as documented over the years by Human Rights Watch, Amnesty International and Front Line Defenders, among many others. Repression extended to media and human rights activists in particular, many of whom had to leave the country and continue their work in diaspora.
Uzbekistan was one of the first to establish a pervasive Internet censorship infrastructure, blocking access to media and human rights websites. Hacking Team servers in Uzbekistan were identified as early as 2014 by the Citizen Lab. It was later confirmed that Uzbek National Security Service (SNB) were among the customers of Hacking Team solutions from leaked Hacking Team emails. A Privacy International report from 2015 describes the installation in Uzbekistan of several monitoring centers with mass surveillance capabilities provided by the Israeli branch of the US-based company Verint Systems and by the Israel-based company NICE Systems. A 2007 Amnesty International report entitled ‘We will find you anywhere’ gives more context on the utilisation of these capabilities, describing digital surveillance and targeted attacks against Uzbek journalists and human-right activists. Among other cases, it describes the unfortunate events behind the closure of uznews.net – an independent media website established by Galima Bukharbaeva in 2005 following the Andijan massacre. In 2014, she discovered that her email account had been hacked and information about the organization, including names and personal details journalists in Uzbekistan was published online. Galima is now the editor of Centre1, a Deflect client and one of the targets of this investigation.
A New Phishing and Web Attack Campaign
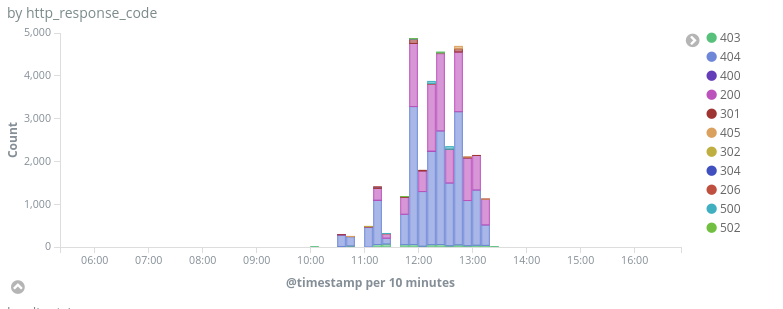
On the 16th of November 2018, we identified a large attack against several websites protected by Deflect. This attack used several professional security audit tools like NetSparker and WPScan to scan the websites eltuz.com and centre1.com.
Peak of traffic during the attack (16th of November 2018)
This attack was coming from the IP address 51.15.94.245 (AS12876 – Online AS but an IP range dedicated to Scaleway servers). By looking at older traffic from this same IP address, we found several cases of attacks on other Deflect protected websites, but we also found domains mimicking google and gmail domains hosted on this IP address, like auth.login.google.email-service[.]host or auth.login.googlemail.com.mail-auth[.]top. We looked into passive DNS databases (using the PassiveTotal Community Edition and other tools like RobTex) and crossed that information with attacks seen on Deflect protected websites with logging enabled. We uncovered a large campaign combining web and phishing attacks against media and activists. We found the first evidence of activity from this group in February 2016, and the first evidence of attacks in December 2017.
The list of Deflect protected websites chosen by this campaign, may give some context to the motivation behind them. Four websites were targeted:
Fergana News is a leading independent Russian & Uzbek language news website covering Central Asian countries
Centre1 is an independent media organization covering news in Central Asia
Palestine Chronicle is a non-profit organization working on human-rights issues in Palestine
Three of these targets are prominent media focusing on Uzbekistan. We have been in contact with their editors and several other Uzbek activists to see if they had received phishing emails as part of this campaign. Some of them were able to confirm receiving such messages and forwarded them to us. Reaching out further afield we were able to get confirmations of phishing attacks from other prominent Uzbek activists who were not linked websites protected by Deflect.
Palestine Chronicle seems to be an outlier in this group of media websites focusing on Uzbekistan. We don’t have a clear hypothesis about why this website was targeted.
A year of web attacks against civil society
Through passive DNS, we identified three IPs used by the attackers in this operation :
46.45.137.74 was used in 2016 and 2017 (timeline is not clear, Istanbul DC, AS197328)
139.60.163.29 was used between October 2017 and August 2018 (HostKey, AS395839)
51.15.94.245 was used between September 2018 and February 2019 (Scaleway, AS12876)
We have identified 15 attacks from the IPs 139.60.163.29 and 51.15.94.245 since December 2017 on Deflect protected websites:
Date
IP
Target
Tools used
2017/12/17
139.60.163.29
eltuz.com
WPScan
2018/04/12
139.60.163.29
eltuz.com
Acunetix
2018/09/15
51.15.94.245
www.palestinechronicle.com eltuz.com www.fergana.info and uzbek.fergananews.com
Acunetix and WebCruiser
2018/09/16
51.15.94.245
www.fergana.info
Acunetix
2018/09/17
51.15.94.245
www.fergana.info
Acunetix
2018/09/18
51.15.94.245
www.fergana.info
NetSparker and Acunetix
2018/09/19
51.15.94.245
eltuz.com
NetSparker
2018/09/20
51.15.94.245
www.fergana.info
Acunetix
2018/09/21
51.15.94.245
www.fergana.info
Acunetix
2018/10/08
51.15.94.245
eltuz.com, www.fergananews.com and news.fergananews.com
Unknown
2018/11/16
51.15.94.245
eltuz.com, centre1.com and en.eltuz.com
NetSparker and WPScan
2019/01/18
51.15.94.245
eltuz.com
WPScan
2019/01/19
51.15.94.245
fergana.info www.fergana.info and fergana.agency
Unknown
2019/01/30
51.15.94.245
eltuz.com and en.eltuz.com
Unknown
2019/02/05
51.15.94.245
fergana.info
Acunetix
Besides classic open-source tools like WPScan, these attacks show the utilization of a wide range of commercial security audit tools, like NetSparker or Acunetix. Acunetix offers a trial version that may have been used here, NetSparker does not, showing that the operators may have a consistent budget (standard offer is $4995 / year, a cracked version may have been used).
It is also surprising to see so many different tools coming from a single server, as many of them require a Graphical User Interface. When we scanned the IP 51.15.94.245, we discovered that it hosted a Squid proxy on port 3128, we think that this proxy was used to relay traffic from the origin operator computer.
Extract of nmap scan of 51.15.94.245 in December 2018 :
3128/tcp open http-proxy Squid http proxy 3.5.23
|_http-server-header: squid/3.5.23
|_http-title: ERROR: The requested URL could not be retrieved
A large phishing campaign
After discovering a long list of domains made to resemble popular email providers, we suspected that the operators were also involved in a phishing campaign. We contacted owners of targeted websites, along with several Uzbek human right activists and gathered 14 different phishing emails targeting two activists between March 2018 and February 2019 :
Date
Sender
Subject
Link
12th of March 2018
g.corp.sender[@]gmail.com
У Вас 2 недоставленное сообщение (You have 2 undelivered message)
http://mail.gmal.con.my-id[.]top/
13th of June 2018
service.deamon2018[@]gmail.com
Прекращение предоставления доступа к сервису (Termination of access to the service)
http://e.mail.gmall.con.my-id[.]top/
18th of June 2018
id.warning.users[@]gmail.com
Ваш новый адрес в Gmail: alexis.usa@gmail.com (Your new email address in Gmail: alexis.usa@gmail.com)
http://e.mail.users.emall.com[.]my-id.top/
10th of July 2018
id.warning.daemons[@]gmail.com
Прекращение предоставления доступа к сервису (Termination of access to the service)
hxxp://gmallls.con-537d7.my-id[.]top/
10th of July 2018
id.warning.daemons[@]gmail.com
Прекращение предоставления доступа к сервису (Termination of access to the service)
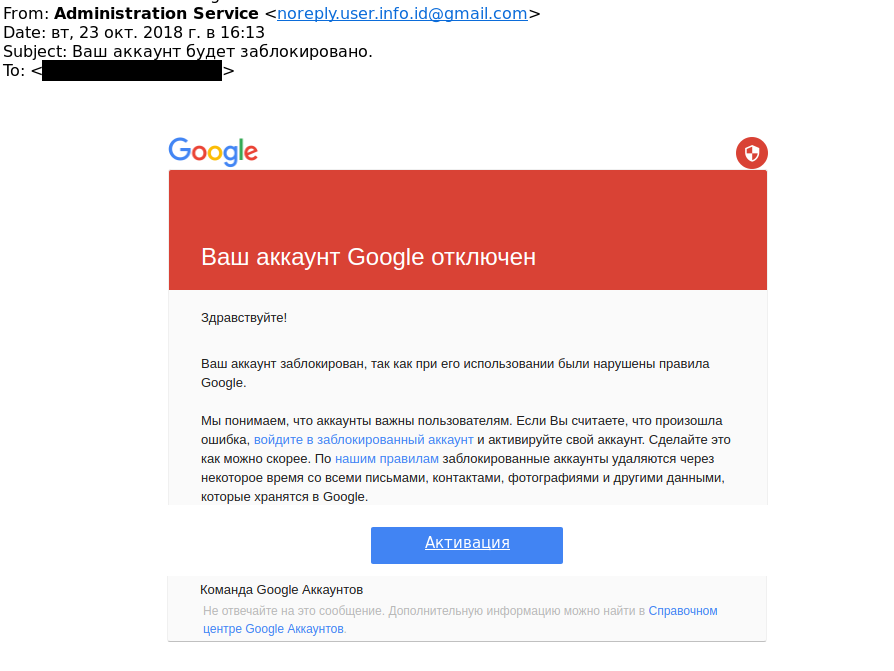
Almost all these emails were mimicking Gmail alerts to entice the user to click on the link. For instance this email received on the 23rd of October 2018 pretends that the account will be closed soon, using images of the text hosted on imgur to bypass Gmail detection :
The only exception was an email received on the 16th of October 2018 pretending to give confidential information on the former Hokim (governor) of Tashkent :
Emails were using simple tricks to bypass detection, at times drw.sh url shortener (this tool belongs to a Russian security company Doctor Web) or by using open re-directions offered in several Google tools.
Every email we have seen used a different sub-domain, including emails from the same Gmail account and with the same subject line. For instance, two different emails entitled “Прекращение предоставления доступа к сервису” and sent from the same address used hxxp://gmallls.con-537d7.my-id[.]top/ and http://gmallls.con-4f137.my-id[.]top/ as phishing domains. We think that the operators used a different sub-domain for every email sent in order to bypass Gmail list of known malicious domains. This would explain the large number of sub-domains identified through passive DNS. We have identified 74 sub-domains for 26 second-level domains used in this campaign (see the appendix below for full list of discovered domains).
We think that the phishing page stayed online only for a short time after having sent the email in order to avoid detection. We got access to the phishing page of a few emails. We could confirm that the phishing toolkit checked if the password is correct or not (against the actual gmail account) and suspect that they implemented 2 Factor authentication for text messages and 2FA applications, but could not confirm this.
Timeline for the campaign
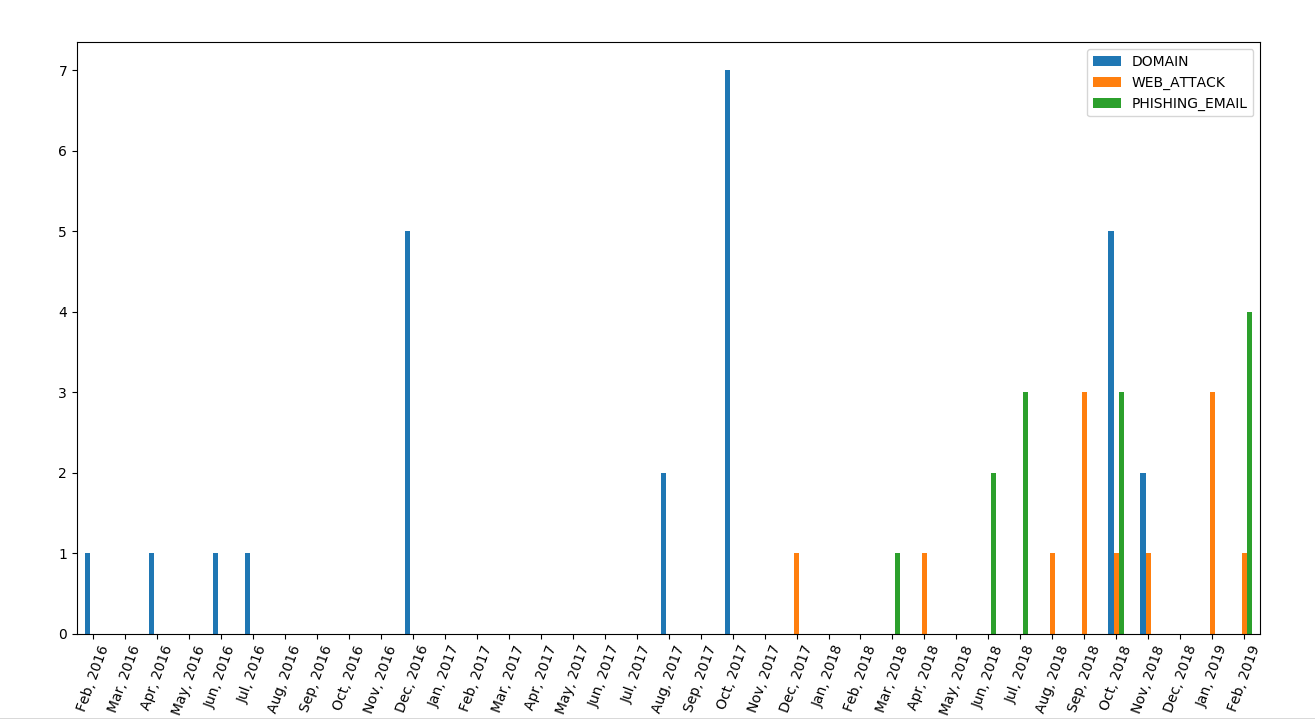
We found the first evidence of activity in this operation with the registration of domain auth-login[.]com on the 21st of February 2016. Because we discovered the campaign recently, we have little information on attacks during 2016 and 2017, but the domain registration date shows some activity in July and December 2016, and then again in August and October 2017. It is very likely that the campaign started in 2016 and continued in 2017 without any public reporting about it.
Here is a first timeline we obtained based on domain registration dates and dates of web attacks and phishing emails :
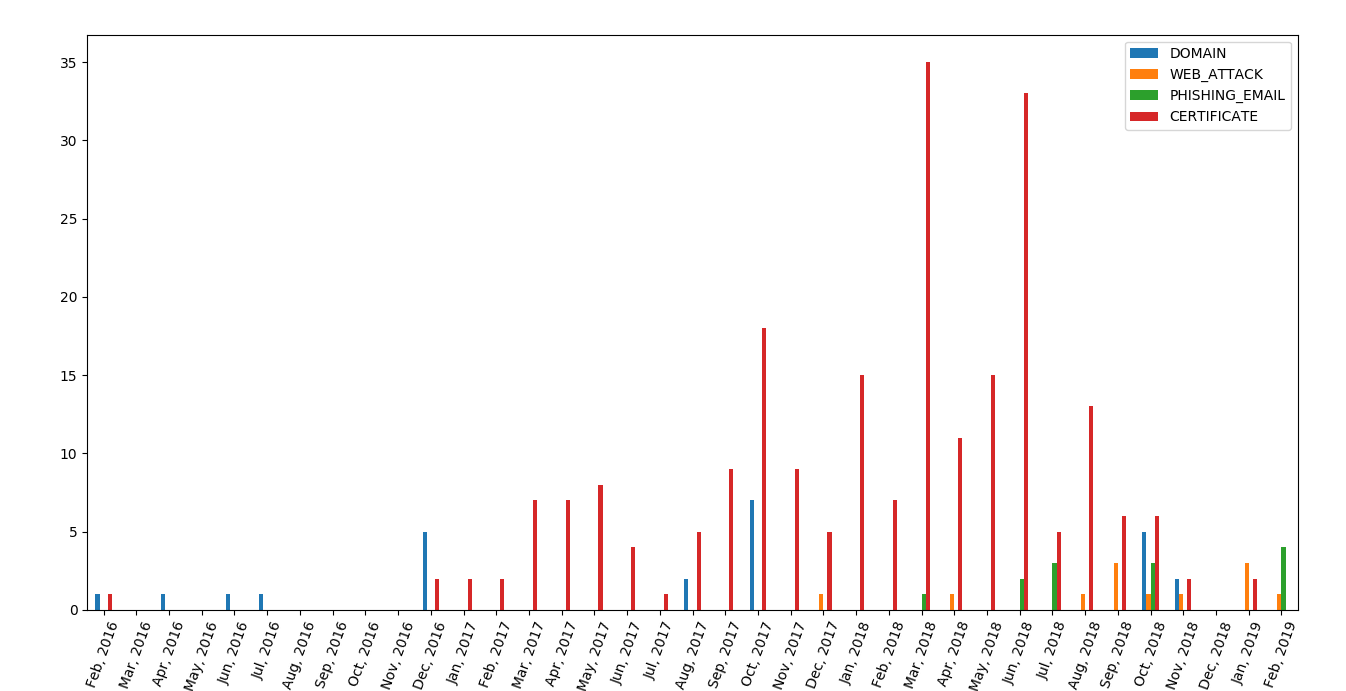
To confirm that this group had some activity during 2016 and 2017, we gathered encryption (TLS) certificates for these domains and sub-domains from the crt.sh Certificate Transparency Database. We identified 230 certificates generated for these domains, most of them created by Cloudfare. Here is a new timeline integrating the creation of TLS certificates :
We see here many certificates created since December 2016 and continuing over 2017, which shows that this group had some activity during that time. The large number of certificates over 2017 and 2018 comes from campaign operators using Cloudflare for several domains. Cloudflare creates several short-lived certificates at the same time when protecting a website.
It is also interesting to note that the campaign started in February 2016, with some activity in the summer of 2016, which happens to when the former Uzbek president Islam Karimov died, news first reported by Fergana News, one of the targets of this attack campaign.
Infrastructure Analysis
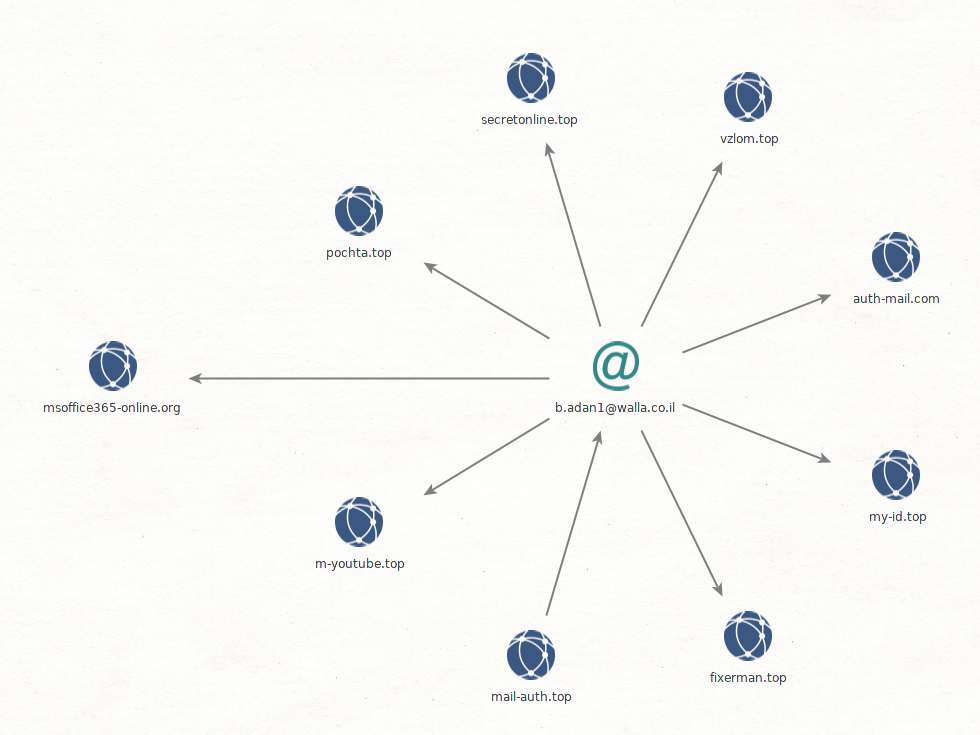
We identified domains and subdomains of this campaign through analysis of passive DNS information, using mostly the Community access of PassiveTotal. Many domains in 2016/2017 reused the same registrant email address, b.adan1@walla.co.il, which helped us identify other domains related to this campaign :
Based on this list, we identified subdomains and IP addresses associated with them, and discovered three IP addresses used in the operation. We used Shodan historical data and dates of passive DNS data to estimate the timeline of the utilisation of the different servers :
46.45.137.74 was used in 2016 and 2017
139.60.163.29 was used between October 2017 and August 2018
51.15.94.245 was used between September and February 2019
We have identified 74 sub-domains for 26 second-level domains used in this campaign (see the appendix for a full list of IOCs). Most of these domains are mimicking Gmail, but there are also domains mimicking Yandex (auth.yandex.ru.my-id[.]top), mail.ru (mail.ru.my-id[.]top) qip.ru (account.qip.ru.mail-help-support[.]info), yahoo (auth.yahoo.com.mail-help-support[.]info), Live (login.live.com.mail-help-support[.]info) or rambler.ru (mail.rambler.ru.mail-help-support[.]info). Most of these domains are sub-domains of a few generic second-level domains (like auth-mail.com), but there are a few specific second-level domains that are interesting :
We have not found any information on vzlom[.]top and fixerman[.]top. Vzlom means “break into” in Russian, so it could have hosted or mimicked a security website
A weird Cyber-criminality Nexus
It is quite unusual to see connections between targeted attacks and cyber-criminal enterprises, however during this investigation we encountered two such links.
The first one is with the domain msoffice365[.]win which was registered by b.adan1@walla.co.il (as well as many other domains from this campaign) on the 7th of December 2016. This domain was identified as a C2 server for a cryptocurrency theft tool called Quant, as described in this Forcepoint report released in December 2017. Virus Total confirms that this domain hosted several samples of this malware in November 2017 (it was registered for a year). We have not seen any malicious activity from this domain related to our campaign, but as explained earlier, we have marginal access to the group’s activity in 2017.
The second link we have found is between the domain auth-login[.]com and the groups behind the Bedep trojan and the Angler exploit kit. auth-login[.]com was linked to this operation through the subdomain login.yandex.ru.auth-login[.]com that fit the pattern of long subdomains mimicking Yandex from this campaign and it was hosted on the same IP address 46.45.137.74 in March and April 2016 according to RiskIQ. This domain was registered in February 2016 by yingw90@yahoo.com (David Bowers from Grovetown, GA in the US according to whois information). This email address was also used to register hundreds of domains used in a Bedep campaign as described by Talos in February 2016 (and confirmed by severalother reports). Angler exploit kit is one of the most notorious exploit kit, that was commonly used by cyber-criminals between 2013 and 2016. Bedep is a generic backdoor that was identified in 2015, and used almost exclusively with the Angler exploit kit. It should be noted that Trustwave documented the utilization of Bedep in 2015 to increase the number of views of pro-Russian propaganda videos.
Even if we have not seen any utilisation of these two domains in this campaign, these two links seem too strong to be considered cirmcumstantial. These links could show a collaboration between cyber-criminal groups and state-sponsored groups or services. It is interesting to remember the potential involvement of Russian hacking groups in attacks on Uznews.net editor in 2014, as described by Amnesty international.
Taking Down Servers is Hard
When the attack was discovered, we decided to investigate without sending any abuse requests, until a clearer picture of the campaign emerged. In January, we decided that we had enough knowledge of the campaign and started to send abuse requests – for fake Gmail addresses to Google and for the URL shorteners to Doctor Web. We did not receive any answer but noticed that the Doctor Web URLs were taken down a few days after.
Regarding the Scaleway server, we entered into an unexpected loop with their abuse process. Scaleway operates by sending the abuse request directly to the customer and then asks them for confirmation that the issue has been resolved. This process works fine in the case of a compromised server, but does not work when the server was rented intentionally for malicious activities. We did not want to send an abuse request because it would have involved giving away information to the operators. We contacted Scaleway directly and it took some time to find the right person on the security team. They acknowledged the difficulty of having an efficient Abuse Process, and after we sent them an anonymized version of this report along with proof that phishing websites were hosted on the server, they took down the server around the 25th of January 2019.
Being an infrastructure provider, we understand the difficulty of dealing with abuse requests. For a lot of hosting providers, the number of requests is what makes a case urgent or not. We encourage hosting providers to better engage with organisations working to protect Civil Society and establish trust relationships that help quickly mitigate the effects of malicious campaigns.
Conclusion
In this report, we have documented a prolonged phishing and web attack campaign focusing on media covering Uzbekistan and Uzbek human right activists. It shows that once again, digital attacks are a threat for human-right activists and independent media. There are several threat actors known to use both phishing and web attacks combined (like the Vietnam-related group OceanLotus), but this campaign shows a dual strategy targeting civil society websites and their editors at the same time.
We have no evidence of government involvement in this operation, but these attacks are clearly targeted on prominent voices of Uzbek civil society. They also share strong similarities with the hack of Uznews.net in 2014, where the editor’s mailbox was compromised through a phishing email that appeared as a notice from Google warning her that the account had been involved in distributing illegal pornography.
Over the past 10 years, several organisations like the Citizen Lab or Amnesty International have dedicated lots of time and effort to document digital surveillance and targeted attacks against Civil Society. We hope that this report will contribute to these efforts, and show that today, more than ever, we need to continue supporting civil society against digital surveillance and intrusion.
Counter-Measures Against such Attacks
If you think you are targeted by similar campaigns, here is a list of recommendations to protect yourself.
Against phishing attacks, it is important to learn to recognize classic phishing emails. We give some examples in this report, but you can read othersimilar reports by the Citizen Lab. You can also read this nice explanation by NetAlert and practice with this Google Jigsaw quizz. The second important point is to make sure that you have configured 2-Factor Authentication on your email and social media accounts. Two-Factor Authentication means using a second way to authenticate when you log-in besides your password. Common second factors include text messages, temporary password apps or hardware tokens. We recommend using either temporary password apps (like Google Authenticator; FreeOTP) or Hardware Keys (like YubiKeys). Hardware keys are known to be more secure and strongly recommended if you are an at-risk activist or journalist.
Against web attacks, if you are using a CMS like WordPress or Drupal, it is very important to update both the CMS and its plugins very regularly, and avoid using un-maintained plugins (it is very common to have websites compromised because of outdated plugins). Civil society websites are welcome to apply to Deflect for free website protection.
Appendix
Acknowledgement
We would like to thank Front Line Defenders and Scaleway for their help. We would also like to thank ipinfo.io and RiskIQ for their tools that helped us in the investigation.